

OCTO Technologies est une entreprise spécialisée dans le Conseil et Expertise IT de construction d’applications stratégiques pour l’entreprise.
Hadoop est à la fois une technologie et une plateforme multi-usages, et suscite lui-même de nouveaux usages – ceux du Big Data. Un changement se produira à tous les niveaux :
- Les études informatiques et les équipes décisionnelles (BI) devront se former à une nouvelle panoplie d’outils.
- Les architectes devront maîtriser cette plateforme complexe. Cette compétence leur permettra de choisir les outils adéquats dans un écosystème mouvant, d’optimiser les traitements et d’aider au débogage. Ils joueront aussi un rôle crucial dans les projets d’intégration de la plateforme avec le reste du Système d’information.
- La production devra être prête à construire des clusters d’un type nouveau, à superviser de nouveaux logiciels.
- Les métiers, les data miners et les data scientists bénéficieront eux aussi de nouveaux outils à disposition et susciteront des use cases innovants. Ils croiseront des données qui n’ont pas l’habitude de l’être, parce qu’elles résident dans des silos aujourd’hui cloisonnés ; pour cela ils devront faire bouger les frontières d’organisation internes à l’entreprise.
Dès lors, on se pose la question de l’organisation à mettre en place pour que tout ce petit monde collabore dans ce contexte compliqué et mouvant. C’est que la bête ne se laisse pas facilement mener par la trompe…
Il va déjà falloir faire face à une maturité inégale des composants. Certains sont instables, certains à peine émergents, notamment dans les couches hautes de l’architecture où sont les attentes des utilisateurs finaux. Le tout évolue allègrement à un rythme soutenu. Un travail de veille permanente est donc indispensable, il ne faut surtout pas négliger son ampleur ! Les équipes auront besoin de temps pour cela.
Allons plus loin encore : un cluster Hadoop est un service de traitement de données partagé entre plusieurs utilisateurs, ce que l’on appelle multi-tenant. Vous allez vite vous rendre compte qu’il est un composant critique de vos processus métier. Or c’est une plateforme en évolution, que vous êtes en train d’apprivoiser. Comment résoudre cette équation ? Sûrement pas avec une organisation classique silotée en services. Là encore, ce sont les modèles d’organisation agiles qui donneront la direction.
Par exemple, un embryon d’équipe transverse pourra être constituée d’un architecte, d’un développeur expert Hadoop, d’un data scientist et d’un exploitant. Ils collaboreront pour maintenir un cluster et aider les premiers projets désireux de goûter aux charmes de Big Data.
Hadoop va vite se trouver sous les feux des projecteurs de l’entreprise. Quoi de plus normal ! Des usages innovants à la pelle, des promesses d’économies fabuleuses, et surtout un bon gros effet de mode – les projets vont se bousculer au portillon. Évitez le piège de l’ouverture d’un cluster universel à tous les vents : il est impossible de trouver du premier coup l’organisation parfaite qui soit capable d’absorber autant de projets et la charge d’exploitation qui va avec. Il vaut mieux y aller doucement en choisissant bien ses premiers combats, puis apprendre au fur et à mesure.
Hadoop et l’agilité à l’échelle de l’entreprise
L’agilité à grande échelle cherche à adapter l’organisation pour faciliter l’emploi de méthodes agiles. C’est une pratique récente mais qui a déjà quelques incarnations, par exemple dans le framework SAFe (Scaled Agile Framework (sic)).
Une feature team est une équipe pluridisciplinaire (métier, développeurs, production, architectes, etc.) travaillant sur un même produit final – application ou service.
Une component team maintient un composant utilisé par plusieurs feature teams – par exemple (au hasard) un cluster Hadoop multi-tenant.
L’intérêt des organisations agiles, c’est que tout ce petit monde partage de la connaissance par le biais de communautés de pratiques (par exemple, la communauté des utilisateurs de Hive, ou celle des experts des données RH), bien placées pour faire avancer leurs sujets de prédilection. Tout l’inverse d’une cellule d’architecture perchée dans sa tour d’ivoire, en somme.
Avec Hadoop, les obstacles sont petits mais quotidiens, il faut une grande autonomie pour les surmonter et avancer rapidement. Une organisation agile permet cela, en favorisant l’échange et la discussion. Ce sont des idées conceptuellement simples mais difficiles à mettre en marche quand la culture d’entreprise résiste !
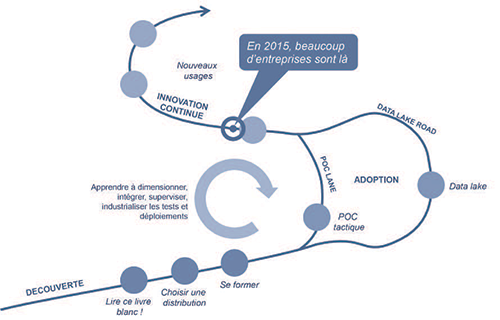
Le processus d’adoption
Premières étapes
Hadoop est à l’œuvre depuis près de 10 ans chez les Géants du Web et les entreprises américaines. En Europe et notamment en France, on observe un décalage. À cette date (fin 2015), de nombreuses organisations ont mené des expérimentations, parfois poussées. Les start-ups et certaines entreprises à la pointe (dont de grandes organisations) ont déjà Hadoop en production, parfois sur des processus critiques.
On peut faire tant de choses avec cette plateforme si complexe, qu’il est difficile de savoir par où commencer. L’astuce est de l’introduire par étapes, ce qui permet de se familiariser avec la technologie, et de laisser la DSI adapter ses processus à un nouveau type d’environnement. C’est une route jalonnée d’étapes, de victoires même. Bien sûr, il y a quelques embûches mais notre expérience nous montre que la solution mais aussi les entreprises sont entrées dans une phase de maturité suffisante pour voir apparaître les premiers cas innovants. L’avenir réserve encore de belles surprises ! Il y a deux approches possibles. L’une et l’autre sont valables, et nous accompagnons des clients sur les deux.
Le premier chemin passe par un POC (Proof of Concept) d’innovation métier. Une nouvelle idée à tester, un nouvel emploi des données du SI, le rapprochement avec des données externes susceptibles d’apporter un nouvel éclairage à votre activité ? Profitez-en, qui dit nouveau besoin dit nouvelle solution, et c’est peut-être l’occasion de faire monter Hadoop sur scène. Du fait de la double nouveauté métier et technique, la mise en œuvre de ce POC nécessitera une collaboration étroite entre les équipes métier et IT.
Contrairement au premier, le deuxième chemin peut et doit être guidé par l’IT. Il s’agit ici d’offrir à l’entreprise un entrepôt de données riche, outillé pour susciter des POC, ce que l’on appelle souvent un data lake. Pour éveiller l’intérêt, le data lake doit satisfaire quelques critères qui le différencient du premier datawarehouse venu. Citons-en quelques-uns :
- Mettre ensemble des données que l’on n’a pas l’habitude de rapprocher : des données provenant de plusieurs métiers, des données externes, des données «.oubliées.» comme les logs ou les emails, etc.
- Offrir un vaste choix de connecteurs ou d’outils, pour permettre l’exploration, l’analyse, la modélisation, la visualisation, etc. en intéressant des acteurs différents.
- Garder une profondeur d’historique inédite en évitant les compromis sur le stockage.
- Démontrer que la plateforme apporte autant, à moindre coût, que les outils habituels du SI – ou plus pour le même coût. Dans beaucoup d’organisations, créer un entrepôt de données relationnel demande de longs mois, en particulier à cause de l’étape centrale de modélisation. Avec Hadoop, vous pouvez mettre très vite des données brutes à disposition de vos utilisateurs, et reporter à plus tard l’étape de modélisation en la lissant dans le temps.
Le data lake, ou l’art de la métaphore
Dans un entrepôt terrestre, un warehouse donc, c’est bien rangé. Les boîtes sont organisées en rayons, et la plupart du temps faciles à empiler. Évidemment, tout ne rentre pas forcément dans un parallélépipède, on perd parfois de l’espace ou on doit répartir les pièces détachées dans des boîtes séparées. Mais c’est simple, bien étiqueté, et tout a été bien planifié. Le contenu des boîtes, ici, c’est la donnée structurée du datawarehouse.
Dans un lac, en revanche, le liquide déversé occupe tout le volume, sans en gaspiller : on peut en mettre plus. On peut y verser des seaux d’eau, ou des glaçons bien cubiques qui finiront par fondre. C’est sûr, une fois mélangé, c’est noyé dans la masse. Mais ce n’est pas très grave, car l’eau n’a d’intérêt que comme contribution au volume global, qu’on peut toujours pomper au besoin. Dans cette analogie approximative, l’eau c’est la donnée « Big data », structurée ou non. Quelle que soit l’approche adoptée, technique ou métier, les projets construits sur le cluster Hadoop seront autant de ruisseaux contributeurs au volume du grand lac.
Les échelles hydrographiques
L’analogie venait au départ du marketing Big Data, puis elle est restée. Les sceptiques ironisent en parlant de data pond (mare de données), les mégalos s’emportent avec des images de data ocean, les pessimistes parlent de data swamp (marécage) pour souligner l’enlisement de l’utilisateur dans une masse de données déversées sans ordre. Finalement, le lac est un juste milieu ! Du reste, on peut compartimenter un lac pour gérer un minimum la circulation des eaux.
Bizarrement, rien n’a été proposé comme analogues des bestioles plus ou moins sympathiques qui grouillent au fond des lacs…
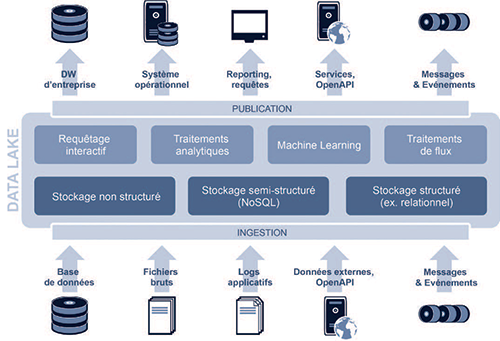
L’architecture d’un data lake
Choisir sa distribution
La multiplicité des distributions et des acteurs Hadoop est un fait. Le choix d’une distribution est évidemment compliqué, d’autant qu’on n’en change pas facilement après coup. Et c’est aussi le choix d’un éditeur, dont vous allez plus ou moins dépendre.
Il est illusoire d’énumérer et d’analyser toutes les distributions du marché, elles sont trop nombreuses. Cependant, après quelques années de maturation d’Hadoop, des éditeurs et distributions incontournables se détachent, souvent généralistes. Nous en citons par ailleurs d’autres qui, par leurs particularités, se destinent à des usages spécifiques.
Pour départager les généralistes, nous voyons trois critères à ce jour :
- La culture plus ou moins open source de chaque éditeur.
- Les partenariats technologiques ou d’intégrateurs de chacun, qui faciliteront l’accueil de sa solution dans votre SI.
- Les outils spécifiques apportés par chaque éditeur à sa distribution, à mettre en regard de vos besoins. Il faut savoir que ces outils ne sont pas facilement portables d’une distribution à l’autre et ne seront pas supportés par les autres éditeurs15.
Par conséquent, si vous n’êtes pas encore affilié à une chapelle, nous vous recommandons de déterminer la solution qui vous convient le mieux grâce à un POC.
À notre connaissance, aujourd’hui seul Hortonworks propose un support en français, soit directement soit par l’intermédiaire de ses partenaires (OCTO étant l’un d’eux).
Le paysage aura sûrement évolué d’ici un an ou deux, à l’occasion des partenariats voire de rachats possibles des généralistes. Des rumeurs circulent régulièrement, pour l’instant elles ne se sont pas vérifiées…
Cette situation pourrait évoluer prochainement, avec le lancement tout récent de Open Data Platform (http://opendataplatform.org/), un effort de standardisation des couches basses d’Hadoop. Plusieurs gros éditeurs adhèrent à l’initiative, à l’exception notable de Cloudera. L’avenir nous dira si cela suffira à rendre les outils de haut niveau portables d’une distribution à l’autre.
Les grands éditeurs Hadoop avec quelques critères de choix
| DISTRIBUTION | POUR QUELS USAGES ? | REMARQUES |
|---|---|---|
| GENERALISTES | ||
| Apache Open Source | POC, Développement | • Choix fin des versions de chaque outil mais risques d’instabilité et de régressions lors des mises à jour. • Moins de choix pour un outil d’administration, facteur important de choix d’une distribution. • Pour le développement, il vaut mieux leur préférer une VM « bac à sable » d’un éditeur généraliste comme Cloudera ou Hortonworks. |
| Cloudera Distribution including Apache Hadoop (CDH) | • Projet généraliste • Intégration avec les produits des partenaires SAS, Oracle ou IBM. | • Gratuit et en grande partie open source (les exceptions concernent les produits « entreprise » : administration, PRA, etc.). • L’éditeur propose du support et des services en option. • Projets phares : Impala, Sentry, Cloudera Manager (propriétaire). |
| Hortonworks Data Platform (HDP) | • Projet généraliste • Intégration avec les produits des partenaires SAS, Teradata. | • Gratuit et open source. • L’éditeur propose du support et des services en option (support de niveau 1 en français possible). • Projets phares : Stinger, Ranger, Knox, Ambari. |
| GoPivotal | • Projet généraliste • Intégration avec le catalogue d’EMC (Greenplum) et VMWare (GemFire, SQLFire). | • Au départ issu du rapprochement d’EMC et de VMWare, GoPivotal a été cédé à Hortonworks. • Projets phares : Hawq |
| IBM Infosphere BigInsights | • Projet généraliste • Intégration avec le catalogue d’EMC (Greenplum) et VMWare (GemFire, SQLFire). | • Au départ issu du rapprochement d’EMC et de VMWare, GoPivotal a été cédé à Hortonworks. • Projets phares : Hawq |
| SPECIALISEES | ||
| MapR | • Projet avec stockage multi-sites. • Accès mixtes batch/aléatoire de type NFS. | • Distribution payante et supportée par l’éditeur. • MapRFS est une réimplémentation complète d’HDFS. • Amazon Web Services propose MapR dans son offre Elastic MapReduce, comme alternative à la distribution Apache. • Projets phares : Drill. |
| APPLIANCES & CLOUD | ||
| Microsoft Azure Hd Insight | • Projet sur le cloud pour une entreprise « Microsoft ». • Traitement de données stockées sur le cloud Azure. | • Cette distribution a été implémentée sur Azure en partenariat avec Hortonworks. Une compatibilité complète avec la souche open source est annoncée (à éprouver sur cas réel). |
| Teradata | • Projet nécessitant une architecture hybride (Hadoop, Teradata) avec des transferts à haut débit. • Intégration avec les autres outils de la suite Teradata (Aster, Intelligent Query). | • La distribution Hadoop embarquée est celle d’Hortonworks (HDP). |
| Oracle Big Data Appliance | • Projet nécessitant une architecture hybride (Hadoop, Oracle Database ou Exadata) avec des transferts à haut débit. | • La distribution Hadoop embarquée est celle de Cloudera (CDH). |
More around this topic...







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















{kind=link}
{kind=link}