
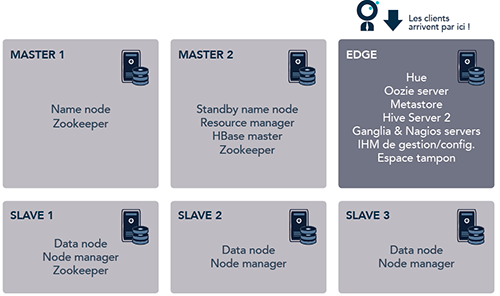
Des serveurs pour exécuter des services
Nous parlons beaucoup de services (name nodes, data nodes, resource manager, etc.), de serveurs et de nœuds, en utilisant les trois termes à tour de rôle. Ils ne sont pas toujours utilisés à bon escient dans la littérature Hadoop, mais nous avons choisi de respecter les usages, quitte à entretenir une certaine confusion. Explicitons-les.
- Un serveur est une machine (physique ou virtuelle) faisant partie du cluster. Facile.
- Un service est un processus qui tourne sur un ou plusieurs serveurs, et participant à l’architecture logicielle d’Hadoop. Pas d’ambiguïté.
- Un nœud est un serveur. Easy, sauf que… on parle de data nodes et de name nodes depuis le début. Ces noms sont trompeurs car ce sont bien des services ; ils ne sont jamais tous seuls sur un nœud. Dans la suite, un master node, slave node ou edge node est bien un serveur. Sur le web et dans la littérature, vous trouverez tout de même les confusions name node / master node et data node / slave node. Ce n’est pas gênant car le contexte empêche toute méprise.
Cette mise au point étant faite, on classe les serveurs en 3 groupes :
- Les master nodes exécutent les services centraux d’Hadoop, ceux qui se retrouvent en un exemplaire, voire deux quand ils sont redondés : name node et son backup, resource manager, HBase Master, etc.
- Les slave nodes exécutent les services nécessaires au stockage et au calcul : data node, node manager, régions HBase et containers éphémères créés par les traitements.
- Les edge nodes enfin portent tous les services périphériques qui servent à interagir avec le cluster, sans en constituer le cœur. On y retrouve les serveurs Oozie, Hive, les outils d’administration… ainsi que des espaces de stockage tampon (fichiers et SGBD) et des canaux d’accès comme FTP, SSH, etc.
Par simplicité, nous avons omis les composants plus techniques qui servent au fonctionnement interne du cluster (par exemple la gestion de la haute disponibilité, ou les agents de monitoring).
Les edge nodes ont un super pouvoir : on peut les multiplier sans toucher au cœur du cluster. Mais pourquoi le ferait-on ? Eh bien si plusieurs équipes ou services utilisent le cluster, il peut être intéressant que chacun ait « son » edge en propre. Chacun peut ainsi choisir ses versions ou patches d’outils périphériques, ajouter des outils tiers dont il possède la licence, ou disposer de son propre SLA vis-à-vis de l’exploitant. Tout en souplesse…
Serveurs physiques ou virtuels ?
C’est une question qui revient souvent. Parfois même, c’est la première question qu’on nous pose : pour beaucoup d’organisations, il est plus facile d’obtenir des machines virtuelles, mais Hadoop les supporte-t-il ?
Notre réponse est en général la suivante : oui mais il faut prendre des précautions. Des master et slave nodes virtuels font très bien l’affaire si on accepte le risque d’avoir des performances moindres en cas de contentions sur les châssis ou les disques partagés : ce risque est souvent acceptable pour un POC. Attention quand même, s’il y a d’autres applications sur le même châssis, elles peuvent pâtir de la gourmandise d’Hadoop en I/O disques et réseau – pensez à limiter les bandes passantes du cluster.
Les edge nodes, eux, sont moins sollicités que les masters et slave nodes : ils peuvent être virtuels. Dans le cas d’un cluster mixte virtuel et physique, cela complexifie un peu la configuration réseau, serveurs physiques et virtuels devant appartenir à un même réseau virtuel (VLAN) mais d’autres avantages équilibrent la balance. Ainsi, l’hyperviseur peut offrir des services de redondance avec basculement automatique, sur des serveurs qui sont importants car accédés directement par les utilisateurs.
Le dimensionnement
Quand il s’agit de dimensionner des infrastructures Hadoop, on peut jouer sur deux paramètres : la taille et le nombre des slave nodes. Ce nombre est au minimum de trois (le plus petit cluster de production viable est donc de 5 nœuds : 2 masters en haute disponibilité, et 3 slaves pour respecter le facteur de réplication d’HDFS).
Nous avons évoqué au début de ce document la notion de commodity hardware. Pour rappel, il s’agit des serveurs faciles à obtenir et de coût unitaire raisonnable, en général ceux qui sont au catalogue des standards de l’entreprise. L’idée est donc de choisir dans un tel catalogue, dans la mesure du possible en limitant les « personnalisations » qui rajoutent des coûts. L’éditeur de la distribution que vous aurez choisie aura certainement des abaques qui vous permettront de monter un cluster généraliste compatible avec nos hypothèses de départ. De ce point de vue, les préconisations des grands éditeurs diffèrent quelque peu mais heureusement se rejoignent sur l’essentiel.
Demain, les progrès d’Hadoop remettront ces chiffres en question. Un paramètre en particulier devra être revu : le dimensionnement de la mémoire. En effet, HDFS est en train de se doter de fonctionnalités de cache, afin d’accélérer l’accès aux fichiers fréquemment lus dans les traitements. Processus, traitements et caches vont ainsi se trouver en compétition pour la mémoire des slave nodes.
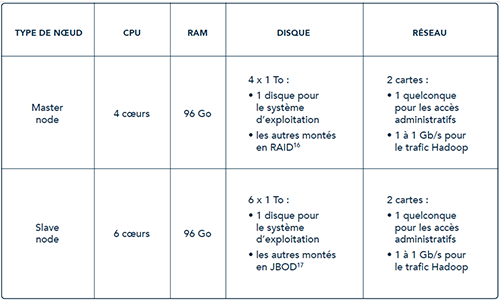
Des configurations matérielles moyennes pour démarrer sur Hadoop
Note :
- Redundant Array of Inexpensive Disks : plusieurs disques sont montés en redondance pour garantir de ne pas perdre de données en cas de défaillance d’un disque. Le name node, sur un master, maintient le plan du système de fichiers HDFS, plan qu’il ne faut surtout pas perdre.
- Just a Bunch Of Disks : plusieurs disques sont montés indépendamment pour totaliser un grand volume de stockage. On ne cherche pas à fiabiliser les disques comme avec du RAID, car HDFS réplique déjà naturellement les blocs de fichiers.
Pour des workloads plus compliqués
Les hypothèses généralistes, qui servent de base aux abaques ci-dessus, ne sont pas toujours suffisantes pour dimensionner correctement. Lorsque d’autres applications sont en jeu, il faut affiner. Comme il est impossible d’être précis en dehors de tout contexte, contentons-nous de donner quelques règles.
Selon le type de traitement envisagé, les besoins en ressources ne seront pas les mêmes. Ainsi, si HBase a besoin de mémoire pour être performant (mise en cache), Storm a surtout besoin de CPU.
L’affaire se complique encore lorsqu’un cluster « multi-usages » est mis en place, pour satisfaire des utilisateurs humains divers et des besoins applicatifs. Dans ces conditions, les sollicitations sont imprévisibles et les traitements variés, rendant difficile un dimensionnement pragmatique. Il faut analyser les besoins précis, leurs proportions dans le mix des usages, et faire des hypothèses de passage à l’échelle en appliquant des règles de 3. Quand les besoins s’opposent trop fortement, il n’est pas économique de dimensionner au pire, et on peut être amené à dédier des nœuds spécifiques du cluster à certains types d’applications. Les labels de YARN, récemment ajoutés, servent précisément à cela. Sinon, il reste toujours possible d’entretenir plusieurs clusters !
En tout cas une règle reste valable : que ce soit pour un cluster global ou des « bulles » de nœuds dédiés via les labels, la principale variable d’ajustement reste le nombre de slave nodes. Il faut bien sûr valider les hypothèses en suivant la consommation des ressources au jour le jour, et faire des projections pour s’assurer que le cluster est bien dimensionné pour les besoins qu’il sert. S’il s’avère trop juste, il est toujours possible d’ajouter des nœuds a posteriori – on n’est pas contraint d’investir tout de suite dans une configuration musclée en priant pour qu’elle suffise du premier coup.
Exemple de dimensionnement
Supposons que le besoin, tel qu’il est connu aujourd’hui, vous conduise à estimer une taille de données sur HDFS à 15 To, soit 3 x 15 = 45 To réels en tenant compte du facteur de réplication habituel. Après examen du catalogue, vous avez retenu deux modèles candidats :
- Le Modèle A, qui dispose d’un CPU quadricœur à 2,25 GHz, de 128 Go de RAM et pouvant accueillir 6 disques de 2 To chacun. Il vous coûterait 6.000 € à l’unité.
- Le Modèle B, qui dispose d’un CPU quadricœur à 2,5 GHz, de 256 Go de RAM, pouvant accueillir 10 disques de 1,5 To chacun, pour la modique somme de 8.500 € par serveur.
Pour stocker vos 45 To, il vous faudrait donc soit :
- 12 Modèle A pour un coût total de 72.000 €, avec 3 To réels de marge.
- 10 Modèle B pour un coût total de 85.000 €, avec 5 To réels de marge.
Vous décidez qu’une marge de 3 To est suffisante pour démarrer, il semble donc plus intéressant de choisir les Modèles A malgré les 2 serveurs de plus.
Après quelques semaines d’utilisation, les chiffres montrent que les 128 Go de RAM par nœud sont un petit peu justes compte tenu des traitements exécutés sur le cluster. On vous propose d’équiper les serveurs avec 192 Go de RAM à la place, pour un coût unitaire de 500 €. Cette quantité vous convient, et la facture révisée s’élève à 12 x 6.500 € = 78.000 €. C’est toujours moins cher que les 10 Modèles B : adjugé !
Et si un jour le cluster doit grandir, et que les Modèles A ne soient plus au catalogue pour cause d’obsolescence ? Aucune importance, Hadoop se satisfait très bien de serveurs hétérogènes.
Un peu plus de détails
Les indications ci-dessus sont volontairement très générales. Nous faisons un aparté pour expliquer grossièrement comment sont construites de telles abaques.
Il faut voir un cluster Hadoop comme un ensemble de ressources. Les CPU, mémoire et disques de chaque slave node vont coopérer pour mener à bien les traitements demandés. Pour que ces traitements soient efficaces, il faut limiter les goulets d’étranglement. La parallélisation sur plusieurs nœuds, par exemple avec un algorithme MapReduce, est un premier niveau d’optimisation ; encore faut-il que les serveurs eux-mêmes soient efficaces.
Un slave node va exécuter plusieurs containers en même temps, typiquement autant de containers que de cœurs de CPU présents sur la machine (moins 1 si on tient compte du système d’exploitation qui a besoin d’un cœur pour ses affaires). Au-delà, les containers se trouveraient bloqués par la pénurie de puissance de calcul.
Prenons l’exemple d’un traitement MapReduce. Chaque mapper va lire des données d’HDFS par blocs entiers. Sur un serveur donné, il faut éviter que les mappers ne sollicitent plus d’accès disque que ce que la machine est capable de fournir, pour éviter un goulet au niveau des contrôleurs disques. On doit donc veiller à brancher 1 à 2 disques par cœur de calcul (en tenant compte de l’hyperthreading) sur chaque serveur – d’où le montage en JBOD pour les data nodes. Chaque disque disposant de son contrôleur indépendant, il pourra en principe servir un mapper de manière exclusive.
En ce qui concerne la RAM, il faut raisonner là aussi par container. Un container est essentiellement une JVM, dont les besoins en mémoire seront la somme de deux paramètres :
- La « PermGen » : mémoire occupée par les classes Java du JDK et des frameworks Hadoop utilisés par le traitement (MapReduce ou Tez par exemple). Cette taille est incompressible, invariable pour un traitement donné, et peu élevée : inférieure à 1 Go.
- La « heap » : mémoire obtenue à la demande par le code des frameworks et du traitement, au fur et à mesure de son exécution. Elle dépend fortement de l’environnement : traitement mis en œuvre et données sur lesquelles il opère. Il n’est pas toujours facile de l’estimer à l’avance.
- Avec MapReduce, on configure séparément la heap des mappers et des reducers. On considère qu’une valeur de départ raisonnable est 4 Go pour les mappers et 6 Go pour les reducers, quitte à augmenter ces valeurs si des traitements échouent par manque de mémoire. En ajoutant les besoins de PermGen et un peu de marge, on arrive à un ordre de grandeur de 8 Go par container. Multipliez par le nombre de cœurs, ajoutez 1 Go pour le système d’exploitation, et vous obtenez la mémoire totale d’un slave node. La configuration fait intervenir quantité d’autres paramètres bien plus fins, comme les buffers de tri pour le shuffle & sort, ou les rapports entre mémoire physique (RAM) et virtuelle (débordement sur disque quand la RAM est pleine, au détriment des performances). Il s’agit de tuning élaboré à des fins de performances, spécifiques à une application, mais nous ne nous y aventurerons pas ici !
Pour le réseau, l’équation est plus simple et les choix plus réduits. Les slave nodes échangent des données en permanence, pour la réplication HDFS, lors du shuffle & sort… Pour cette raison, on part souvent sur des liens à 1 Gb/s, offrant un bon rapport performance / coût. Là encore, des applications spécifiques peuvent apporter des contraintes différentes. N’oubliez pas de dimensionner correctement les liens réseaux qui relient les racks entre eux : dans le pire des cas, ils devront supporter des échanges simultanés entre tous les serveurs du cluster. Pour un rack de 10 serveurs, on prévoit ainsi des switches top-of-rack de 10 x 1 = 10 Gb/s.
Pour aller plus loin, nous vous suggérons de visionner des présentations très poussées sur le dimensionnement des clusters Hadoop, par exemple http://fr.slideshare.net/Hadoop_Summit/costing-your-bug-data-operations, par des ingénieurs de chez Yahoo! Cette présentation combine les aspects techniques et financiers pour vous aider à trouver les configurations optimales.
More around this topic...







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















{kind=link}
{kind=link}