
5 – CASE STUDY: SEAMLESS INTEGRATION OF SIMD AND THREADING
OpenMP 4.0 provides an effective model to exploit both thread- and vector-level parallelism to leverage the power of modern processors. For instance, Intel Xeon Phi coprocessors require that both thread- and vector-level parallelisms are exploited in a well-integrated way. While the parallelization topic is beyond the scope of this chapter, we highlight that the SIMD vector extensions can be seamlessly integrated with threading in OpenMP 4.0, either using composite/combined constructs (parallel for simd) or using them separately at different loop levels via OpenMP compiler support.
Listing 5.1 shows a Mandelbrot example that computes a graphical image representing a subset of the Mandelbrot set (a well-known 2-D fractal shape) out of a range of complex numbers. It outputs the number of points inside and outside the set.
<strong>#pragma omp declare simd uniform(max_iter) simdlen(32)</strong> uint32_t mandel(fcomplex c, uint32_t max_iter) { // Computes number of iterations(count variable) // that it takes for parameter c to be known to // be outside mandelbrot set uint32_t count = 1; fcomplex z = c; while ((cabsf(z) < 2.0f) && (count < max_iter)) { z = z * z + c; count++; } return count; } Caller site code:
int main() { ... <strong>#pragma omp parallel for schedule(guided)</strong> for (int32_t y = 0; y < ImageHeight; ++y) { float c_im = max_imag - y * imag_factor; <strong>#pragma omp simd safelen(32)</strong> for (int32_t x = 0; x < ImageWidth; ++x) { fcomplex in_val; in_val = (min_real + x*real_factor) + (c_im*1.0iF); count[y][x] = mandel(in_val, max_iter); } } ... } Listing 5.1 – An example of OpenMP parallel for and simd combined usage.
The function mandel in the example is a hot function and a candidate for SIMD vectorization, so we can annotate it with declare simd. At the caller site, the hot loop is a doubly nested loop. The outer loop is annotated with parallel for for threading, and the inner loop is annotated with simd for vectorization as shown in listing 5.1. The guided scheduling type is used to balance the load across threads since each call to mandel does a varying amount of work in terms of execution time due to the exit of the while loop. The performance measurement is conducted on an Intel Xeon Phi Coprocessor with the configuration information provided in Table 5.2.
System Parameters: Intel® Xeon Phi™ Processor
Chips: 1
Cores/Threads: 61 and 244
Frequency: 1 GHz
Data caches: 32 KB L1, 512 KB L2 per core
Power Budget: 300 W
Memory Capacity: 7936 MB
Memory Technology: GDDR5
Memory Speed: 2.75 (GHz) (5.5 GT/s)
Memory Channels: 16
Memory Data Width: 32 bits
Peak Memory Bandwidth: 352 GB/s
SIMD vector length: 512 bits
Table 5.2 – Target system configuration.
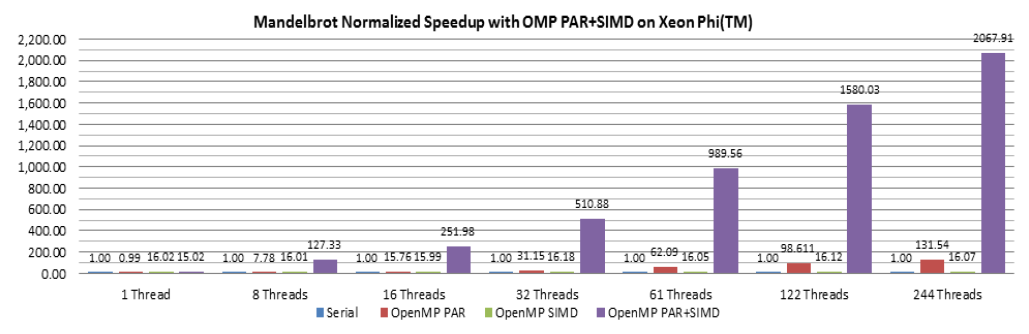
Figure 5.3 shows that the SIMD vectorization alone (options –mmic –openmp –std=c99 –O3) delivers a ~16x speedup over the serial execution. The OpenMP parallelization delivers a 62.09x speedup with Hyper-Threading OFF (61 threads using 61 cores) and a 131.54x speedup with Hyper-Threading ON (244 threads using 61 cores and 4 HT threads per core) over the serial execution. The combined parallelized and vectorized execution delivers a 2067.9x speedup with 244 threads. The performance scaling from 1-thread to 61-threads is close to linear. In addition, Hyper-Threading support delivers a ~2x performance gain by comparing the 244-thread speedup with the 61-thread speedup, which is better than the well-known 20%-30% expected performance gain from Hyper-Threading technology since the workload has little computing resource contention and the 4 HT threads hide latency well.
More around this topic...




In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}