
The compute-bound problem
For this problem, we decided to work with an approximation of the expm1 function which, as many of our readers probably know, is extensively used in finance for discounting. The function approximation consists of one addition (add), two multiplies (mul) and five multiply-and-adds (madd). We composed the same function twelve times to get stable enough results for positive values below 1/3. This leads to 12 add, 24 mul and 60 madd operations per instruction, which can be safely assumed as being compute-bound. The pseudo-code is shown in listing 2.
It must be taken into account that not every algorithm can make full use of the madd operation. In this article, we consider madd to be one floating-point operation. Most architectures featuring either one-cycle madd or same cycle-count madd as add or mul, it is reasonable to view madd as a single flop. Moreover, algorithms reconstructing multiply-add instructions based on evaluation graph are well spread among compilers. In that respect, our raw compute power measurements must be viewed as half those of the official specifications.
Two Kepler K20X implementations are provided:
1 – A naïve version that processes floats one by one.
2 – A vectorized version that processes four elements at a time. In both cases, we tested performance in single (IEEE-754, 32 bits) and double (64 bits) precision.
The results reported Table 5.A show an excellent system usage ratio in double-precision, with or without vectorization. However, single-precision performance without vectorization is disappointing. The reason is simple: SMXes have 192 cores that can be organized in 6 batches of 32 units (each one processing a warp). The accelerator would then reach its highest level of performance when 6 warps execute instructions on the same cycle. But since we only have 4 warp schedulers, they would need to issue two instructions for the same cycle. In other words, using scalar operations in a naïve implementation does not allow the compiler and the hardware to take advantage of the available resources. However, switching to four floats per instruction, we reach a much higher system usage ratio (above 66%). These numbers confirm the interest of instruction level parallelism here.
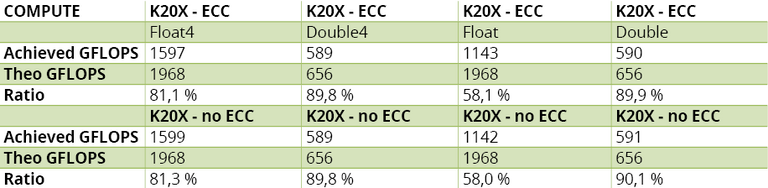
Table 5.A – Kepler K20X’s measured results to the compute-bound test.
Two Xeon Phi SE10P implementations are provided:
1 – Naïve processing.
2 – Vectorization based on intrinsics and using m512 registers. In this approach, we use two m512 registers per entry, i.e. 32 float entries per vector. This indeed yields better results, whereas going to four decreases performance. Note that given the in-order context, we also added some cache prefetching instructions to optimize the data feeds.
Numbers in Table 5.B show that performance improves when we ask the compiler to vectorize, but remain below what we get with a manual implementation. However, with intrinsics for vectorized code, we can make use of more than 80% of the hardware, a figure in the same range as Kepler’s. Last, we remark that the naïve implementation in double-precision is significantly slower than its K20X equivalent.
Looking at the SP graph (below), you can see that the naïve implementation on K20X yields excellent performance, even without ILP (Instruction Level Parallelism). As for the vectorized version, it is totally out of reach by our Phi SE10P sample. In double-precision, Kepler also outperforms Xeon Phi both in naïve and vectorized implementations. It must also be noted that Kepler’s naïve code is faster than Phi’s optimized version. The conclusion is that highly compute-intensive codes may benefit from GPUs. Now, let’s not forget that pure compute-bound algorithms are not so frequent. For instance, composing our function eight times only instead of twelve would have reset the evaluation code as memory-bound.
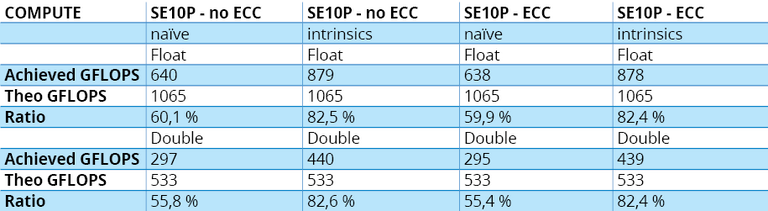
Table 5.B – Xeon Phi SE10P’s measured results to the compute-bound test.
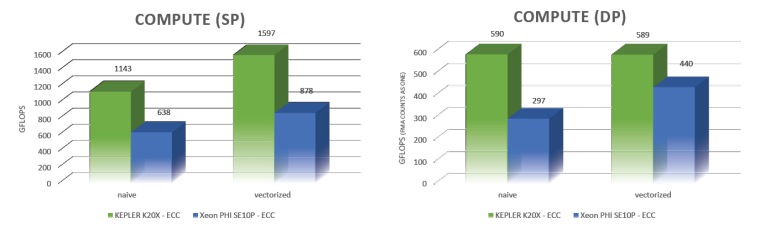
Fig. 2 – Kepler K20X’s and Xeon Phi SE10P’s measured results to the compute-bound test.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















