
Condition de linéarité
Le perceptron est simple, et donc facile à mettre en œuvre, mais il a une limite importante : seuls les problèmes linéairement séparables peuvent être résolus par celui-ci. En effet, les fonctions d’activation utilisées (généralement heavyside, plus rarement sigmoïde) présentent un seuil, séparant deux zones de l’espace.
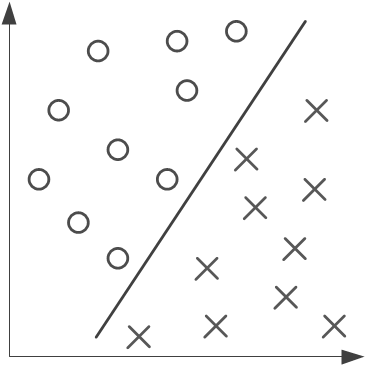
Imaginons un problème possédant deux classes, des croix et des ronds. Si les deux classes sont disposées comme suit, alors le problème est bien linéairement séparable. Une séparation possible est indiquée.
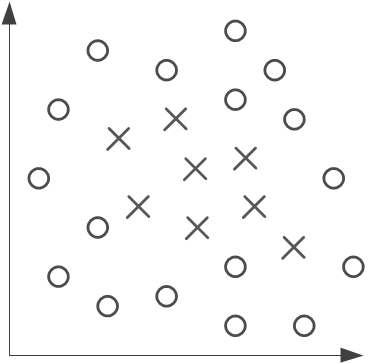
Au contraire, si les points sont présentés comme suit, les classes ne sont pas linéairement séparables et un réseau de type perceptron ne pourra pas résoudre ce problème.
Il faut donc, avant d’utiliser un réseau de type perceptron, s’assurer que le problème pourra être résolu. Sinon il faudra opter pour des réseaux plus complexes.
Réseaux feed-forward
Les réseaux de type “feed-forward” ou à couches permettent de dépasser les limites des perceptrons. En effet, ceux-ci ne sont plus limités aux problèmes linéairement séparables.
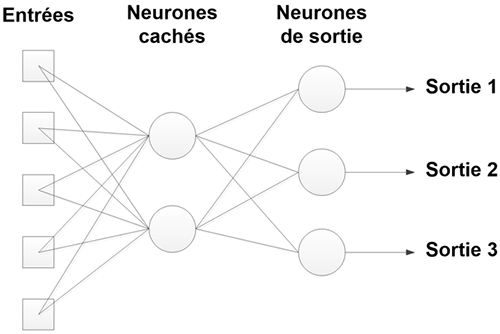
Ils sont composés d’une ou plusieurs couches cachées de neurones, reliées aux entrées ou aux couches précédentes, et une couche de sortie, reliée aux neurones cachés. On les appelle feed-forward car l’information ne peut aller que des entrées aux sorties, sans revenir en arrière.
Il est possible de trouver des réseaux avec plusieurs couches cachées, cependant ces réseaux apportent plus de complexité pour des capacités équivalentes à des réseaux à une seule couche cachée. Ce sont donc ces derniers qui sont les plus utilisés. On obtient le réseau suivant si l’on a 5 entrées et 3 sorties, avec 2 neurones cachés.
Dans ce cas-là, il faut ajuster les poids et seuils de tous les neurones cachés (ici 12 paramètres) ainsi que les poids et seuils des neurones de sortie (9 paramètres). Le problème complet contient donc 21 valeurs à déterminer. De plus, aucune règle ne permet de connaître le nombre de neurones cachés idéal pour un problème donné. Il est donc nécessaire de tester plusieurs valeurs et de choisir celle donnant les meilleurs résultats. Les réseaux utilisant des neurones de type perceptron sont dits MLP pour MultiLayer Perceptron, alors que ceux utilisant des neurones à fonction d’activation gaussienne sont dit RBF (pour Radial Basis Function). Les réseaux MLP et RBF sont les plus courants.
Apprentissage
L’étape la plus importante dans l’utilisation d’un réseau de neurones est l’apprentissage des poids et seuils. Cependant, les choisir ou les calculer directement est impossible sur des problèmes complexes. Il est donc nécessaire d’utiliser des algorithmes d’apprentissage. On peut les séparer dans trois grandes catégories.
Apprentissage non supervisé
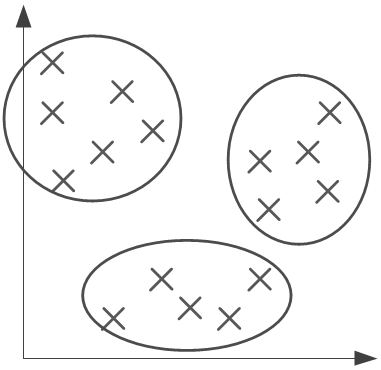
L’apprentissage non supervisé est la forme la moins courante d’apprentissage. En effet, dans cette forme d’apprentissage, il n’y a pas de résultat attendu. On utilise cette forme d’apprentissage pour faire du clustering : on a un ensemble de données, et on cherche à déterminer des classes de faits.
Par exemple, à partir d’une base de données de clients, on cherche à obtenir les différentes catégories, en fonction de leurs achats ou budgets. On ne sait pas a priori combien il y a de catégories ou ce qu’elles sont. On va donc chercher à maximiser la cohérence des données à l’intérieur d’une même classe et à minimiser celle-ci entre les classes.
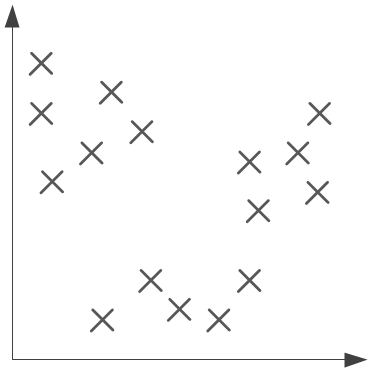
Imaginons que nous ayons l’ensemble de données suivant :
Si nous cherchions à déterminer des classes dans ces données, il serait possible de définir les trois suivantes :
De cette façon, on maximise bien la ressemblance entre les données d’une même classe (les points d’une classe sont proches) tout en minimisant les ressemblances entre les classes (elles sont éloignées entre elles). Les algorithmes d’apprentissage non supervisé sortent du cadre de ce livre et ne sont donc pas présentés.
Apprentissage par renforcement
Dans l’apprentissage par renforcement, on indique à l’algorithme si la décision prise était bonne ou non. On a donc un retour global qui est fourni. Par contre, l’algorithme ne sait pas exactement ce qu’il aurait dû décider.
Remarque : C’est par exemple de cette façon que les animaux (et les humains) apprennent à marcher : on sait ce que l’on cherche à obtenir (la marche) mais pas comment l’obtenir (les muscles à utiliser, avec leur ordre). Le bébé essaie de marcher, et soit tombera (il a faux), soit il arrivera à faire un pas (il a juste). Il finira par comprendre par renforcement positif ou négatif ce qui lui permet de ne pas tomber, et deviendra meilleur, pour pouvoir arriver à courir ensuite.
Dans le cas des réseaux de neurones, on utilise souvent cette forme d’apprentissage quand on cherche à obtenir des comportements complexes faisant intervenir des suites de décisions. C’est par exemple le cas en robotique ou pour créer des adversaires intelligents dans les jeux vidéo. En effet, on cherche alors un programme qui prendra différentes décisions l’emmenant à une position où il est gagnant.
L’apprentissage non supervisé peut se faire grâce aux métaheuristiques. En effet, elles permettent d’optimiser des fonctions sans connaissances a priori. Cependant, la technique la plus employée est l’utilisation des algorithmes génétiques. Ils permettent, grâce à l’évolution, d’optimiser les poids et de trouver des stratégies gagnantes, sans informations particulières sur ce qui était attendu.
Apprentissage supervisé
L’apprentissage supervisé est sûrement le plus courant. Il est utilisé pour des tâches d’estimation, de prévision, de régression ou de classification.
Dans l’apprentissage supervisé, un ensemble d’exemples est fourni à l’algorithme d’apprentissage. Celui-ci va comparer la sortie obtenue par le réseau avec la sortie attendue. Les poids sont ensuite modifiés pour minimiser cette erreur, jusqu’à ce que les résultats soient satisfaisants pour tous les exemples fournis. Cette approche est utilisée à chaque fois que les exemples sont présentés au réseau de neurones les uns à la suite des autres, sans liens entre eux.
C’est le cas en estimation où une valeur doit être calculée en fonction d’autres fournies : la consommation d’une maison en fonction de ses caractéristiques, la lettre dessinée en fonction des pixels noirs et blancs, la modification d’une valeur en bourse en fonction de son historique des dernières heures ou derniers jours, etc.
Remarque : On parle souvent de tâche de régression : il existe une fonction inconnue liant les entrées aux sorties que l’on cherche à approximer. Selon le type de réseau choisi, les algorithmes d’apprentissage supervisés sont différents. Les trois principaux sont vus ici.
More around this topic...
In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}