
Descente de gradient
La méthode de descente de gradient ne s’applique qu’à des réseaux monocouches de type perceptron (avec une fonction heavyside). Les poids sont optimisés par plusieurs passes sur l’ensemble d’apprentissage. Soit un réseau possédant X entrées, et N exemples. On note Si la sortie obtenue sur le énième exemple, et yi la sortie attendue. L’erreur commise sur un point s’exprime donc :
Au début de chaque passe, on initialise à 0 les modifications à appliquer aux poids wi
La variation est notée δwi
À chaque exemple testé, on va modifier celle-ci de la manière suivante :
Remarque : Si la fonction d’activation est différente de la fonction heavyside, il est possible de généraliser cette méthode. Pour cela, il faut multiplier la modification appliquée par la dérivée de la fonction choisie. Cette variation utilise donc l’erreur obtenue sur un exemple, mais aussi la valeur de l’entrée xi et une constante t appelée taux d’apprentissage. La modification d’un poids est donc plus importante si l’erreur est forte et/ou si l’entrée est importante.
Le taux d’apprentissage dépend lui du problème à résoudre : trop faible, il ralentit énormément la convergence. Trop grand, il peut empêcher de trouver la solution optimale. Ce taux sera généralement choisi fort au début de l’apprentissage puis sera réduit à chaque passe. Une variante consiste à diminuer le taux à chaque fois que l’erreur globale diminue, et de le remonter légèrement si l’erreur globale augmente.
Après avoir passé tous les exemples une fois, on applique la modification totale aux poids :
Les modifications ne sont donc appliquées qu’après le test de tous les exemples.
On peut donc résumer cet algorithme par le pseudocode suivant :
Tantque critère d'arrêt non atteint Initialiser les dwi
Pour chaque exemple :
Calculer la sortie si
Pour chaque poids :
dwi += taux * (yi - si) * xi
FinPour
FinPour
Pour chaque poids :
wi += dwi
FinPour
Si besoin, modification du taux
FinTantque
Algorithme de Widrow-Hoff
L’algorithme de descente du gradient converge, mais cependant il n’est pas très rapide. L’algorithme de Widrow-Hoff applique la même modification, mais au lieu de la faire après avoir vu tous les exemples, celle-ci est appliquée après chaque test. De cette façon, l’algorithme converge plus vite sur la majorité des problèmes. Cependant, selon l’ordre et la valeur des exemples, l’algorithme peut en permanence osciller entre deux valeurs pour un poids. Lorsqu’on applique cet algorithme, il faut faire attention à modifier l’ordre des exemples d’apprentissage régulièrement. Son pseudocode est donc :
Tantque critère d'arrêt non atteint
Pour chaque exemple :
Calculer la sortie si
Pour chaque poids :
wi += taux * (yi - si) * xi
FinPour
FinPour
Si besoin, modification du taux
Modification de l'ordre des exemples
FinTantque
Cet algorithme d’apprentissage est lui aussi limité à des réseaux de type perceptron (à une seule couche).
Rétropropagation
Les méthodes précédentes ne s’appliquent qu’aux perceptrons. Cependant, dans de nombreux cas, on utilisera des réseaux en couche (avec ici une fonction d’activation sigmoïde). Il existe un apprentissage possible : par rétropropagation du gradient (nommé “Backpropagation” en anglais).
On va donc corriger tout d’abord les poids entre les neurones de sortie et les neurones cachés, puis propager l’erreur en arrière (d’où le nom) et corriger les poids entre les neurones cachés et les entrées. Cette correction se fera exemple après exemple, et il faudra plusieurs passes (avec des ordres différents si possible) pour converger vers un optimum.
La première étape consiste donc à calculer la sortie de chaque neurone caché nommée oi pour un exemple donné. On fait ensuite de même pour les neurones de sortie. L’erreur commise est toujours :
Avec yi la sortie attendue et si celle obtenue.
L’étape suivante consiste à calculer les deltas sur les neurones de sortie. Pour cela, on calcule pour chacun la dérivée de la fonction d’activation multipliée par l’erreur, qui correspond à notre delta.
Il faut ensuite faire la même chose pour les neurones cachés, reliés chacun aux K neurones de sortie. Le calcul est alors :
En effet, ce calcul prend en compte la correction sur les neurones de sortie (dk) et le poids qui les relie. De plus, là encore, plus un poids est important et plus la correction à appliquer sera forte.
Lorsque tous les deltas sont calculés, les poids peuvent être modifiés en faisant le calcul suivant, où seule la dernière valeur change selon qu’il s’agit d’un neurone caché (on prend l’entrée) ou d’un neurone de sortie (on prend son entrée, c’est-à-dire la sortie du neurone caché) :
Le pseudocode est donc le suivant :
Tantque critère d'arrêt non atteint
Initialiser les di
Pour chaque exemple :
Calculer la sortie si
Pour chaque poids des neurones de sortie :
di = si * (1 - si) * (yi – si)
FinPour
Pour chaque poids des neurones cachés :
sum = 0
Pour chaque lien vers le neurone de sortie k :
sum += dk * wi vers k
FinPour
di = oi * (1 - oi) * sum
FinPour
Pour chaque poids du réseau :
Si lien vers neurone de sortie
wi += taux * di * oi
Sinon
wi += taux * di * si
FinSi
FinPour
FinPour
Si besoin, modification du taux
FinTantque
More around this topic...
In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















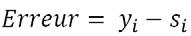{kind=link}
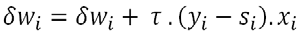{kind=link}
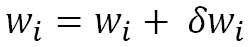{kind=link}
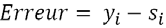{kind=link}
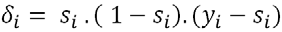{kind=link}
{kind=link}
{kind=link}