
OpenCL promet la portabilité des codes HPC entre différentes architectures matérielles. Qu’en est-il réellement, en termes de performances ? A partir d’une vraie application, nous l’avons soumis à l’épreuve de trois accélérateurs haut de gamme (Intel, NVIDIA et AMD). Voici nos résultats…
François Bodin, PhD – CAPS Entreprise
Guillaume Colin de Verdière – CEA
Romain Dolbeau, PhD – CAPS Entreprise
De par sa disponibilité sur une large gamme de processeurs, OpenCL peut apparaître comme un excellent choix pour cibler plusieurs architectures matérielles à partir d’un unique code source. Cependant, sa sensibilité à l’électronique sous-jacente est un sujet qui en pratique nécessite d’être mieux compris. Cet article se propose de déterminer s’il est vraiment réaliste d’utiliser les mêmes sources OpenCL sur un ensemble de processeurs d’architectures différentes. Pour cela, nous avons travaillé sur les accélérateurs Intel Xeon Phi SE10P, NVIDIA Kepler K20c et AMD Radeon HD 7970, qui tous trois supportent OpenCL 1.1 et représentent une même classe de technologies.
Par ailleurs, notre étude repose sur une mini application, Hydro, qui se compose de 22 noyaux OpenCL générés par le compilateur OpenACC de CAPS. Le portage OpenACC de cette application sur les différents systèmes matériels a fait l’objet d’une attention particulière quant à la minimisation des transferts de données entre le processeur hôte et l’accélérateur.
Nous allons voir qu’une version bien choisie d’un même code OpenCL peut être exécutée sur ces trois plateformes sans dégradation significative des performances. Ce faisant, nous confirmerons l’utilité des techniques d’auto-tuning pour la recherche du meilleur compromis d’efficacité, sachant que développer des codes qui s’adaptent dynamiquement à une architecture n’est pas absolument nécessaire dès lors que la performance ultime n’est pas l’objectif.
Posons le problème
Peut-on réellement parler de portabilité de la performance ? A quels moments l’utilisation de techniques d’auto-tuning et de code adaptatif est-elle nécessaire ? Pour répondre à ces questions, il est important de déterminer l’impact en terme d’efficacité d’une seule version d’un même code sur différentes architectures d’une classe de technologies accélératrices équivalentes. La portabilité de la performance est définie ici comme étant, pour un code donné, la version la plus proche de celle la plus performante ou, en d’autres termes, la perte d’efficacité d’un code ciblant différents accélérateurs.
Nous avons donc décidé de travailler à partir d’Hydro, application suffisamment complexe pour mettre en avant des problématiques de performance concrètes. De simples noyaux de benchmarks tels que la multiplication de matrices ont volontairement été écartés car ils ont tendance à amplifier ou amoindrir les variations de rapidité. En choisissant un cas d’exemple réaliste, cet article vise à déterminer comment obtenir le meilleur compromis entre performance et portabilité sur un code typiquement applicatif. Et ainsi de répondre à une préoccupation majeure parmi les développeurs : beaucoup sont en effet prêts à perdre quelques pourcentages d’efficacité s’ils gagnent en maintenance et en simplicité de codage.
Travaux connexes
La communauté HPC est demandeuse de langages de programmation portables capables de cibler à la fois les processeurs parallèles et les accélérateurs. A cet égard, OpenCL et OpenACC ont montré leur disponibilité sur plusieurs architectures, et sont considérés comme des alternatives valables. Le problème, c’est que la plupart des recherches sur l’optimisation de code se sont concentrées presque exclusivement sur l’obtention de la plus grande efficacité.
Komatsu et al. [1] ont essentiellement comparé OpenCL à CUDA sur plusieurs architectures de processeurs. Leur travail illustre la nécessité d’avoir des optimisations spécifiques à une architecture lorsqu’il s’agit d’obtenir les meilleures performances. Les travaux de Rul et al. [2] analysent la portabilité de la performance d’OpenCL sur un ensemble de plateformes matérielles : CPU, FirePro, Tesla et Cell. Leur papier conclut que l’optimisation de code doit être réalisée pour chacune des architectures et que les techniques d’auto-tuning ([3][4][5]) peuvent contribuer à obtenir certains niveaux de performance portable. Ces techniques engendrent toutefois une complexification et un accroissement de la taille des codes, en raison des différentes versions [6] qu’elles impliquent. Dans la plupart des cas, l’accroissement de la taille du code pose un réel problème puisqu’il dépend à la fois de la taille de l’espace d’optimisation et du nombre de noyaux. Ce problème est encore plus flagrant avec de larges codes natifs dont la durée de vie s’étale sur une quinzaine d’années, soit plus de cinq générations de machines.
Il était trois architectures…
Nos trois processeurs de travail ont été choisis dans la même classe d’accélérateurs pour éviter des optimisations excessivement différentes et parce qu’ils peuvent être les cibles potentielles d’une application HPC. Rappelons leurs principales spécifications :
AMD Radeon HD 7970 – Basé sur l’architecture Graphics Core Next, il offre 947 GFlops en double précision avec une bande passante mémoire théorique de 264 GB/s. Les ressources de calcul sont divisées en 32 unités contenant chacune 4 SIMD incluant 16 FPU scalaires. La mémoire partagée locale, aussi appelée mémoire locale OpenCL, est partagée par les 4 SIMD d’une unité de calcul, ce qui est comparable à un multi-processeur CUDA. La performance double précision représente le quart de celle obtenue en simple précision.
Intel Xeon Phi SE10P : cette version de l’accélérateur x86 Intel contient 61 cœurs 64 bits superscalaires conventionnels travaillant en mode in-order. Capable d’exécuter 4 threads en HyperThreading, chacun de ces cœurs abrite une unité vectorielle de 512 bits. Avec une performance crête de 1 070 GFlops en double précision et une impressionnante bande passante mémoire de 352 GB/s, Phi embarque un OS Linux capable d’exécuter nativement des codes C et Fortran, contrairement aux deux autres architectures. La performance double précision représente la moitié de celle obtenue en simple précision.
NVIDIA K20c : issu de l’architecture Kepler, sa performance double précision atteint 1 170 GFlops avec 208 GB/s de bande passante mémoire théorique (sans ECC – que nous activerons néanmoins pour cet article). L’accélérateur utilise 13 “SMX” (Streaming Multiprocessor) pour 2 496 cœurs CUDA au total. La performance double précision représente le tiers de celle obtenue en simple précision.
Il faut noter que l’AMD 7970 ne requiert plus que le code soit vectorisé par le compilateur. Comme K20c, il exécute des instructions scalaires de manière répliquée sur beaucoup de petits cœurs. Phi SE10P, en revanche, nécessite que le code soit vectorisé pour qu’il puisse exploiter les larges registres SIMD. Heureusement, et contrairement aux précédents jeux d’instructions tels que SSE et AVX, Phi a la capacité de masquer certaines opérations vectorielles, ce qui simplifie la compilation des instructions conditionnelles en mode vecteur.
Les versions d’OpenCL disponibles sur les trois architectures ont chacune leurs spécificités. La plus évidente est la taille maximale des work-groups : elle est limitée à 256 work-items chez AMD tandis que NVIDIA et Intel la fixent à 1 024. Le nombre de work-groups requis pour atteindre de bonnes performances est également différent. K20c demande au moins 1 work-group par SMX avec 13 SMX aux maximum, et peut exécuter jusqu’à 16 work-groups sur chaque SMX avec quelques restrictions, soit un maximum de 208 work-groups au total. L’AMD 7970 exécute pour sa part de 1 à 10 work-groups par compute unit soit de 32 à 320 work-groups au maximum (avec certaines limitations également). Quant à Phi SE10P, il exécute chaque bloc dans un thread et nécessite 240 work-groups pour saturer ses ressources matérielles (un cœur est généralement réservé pour l’OS). Notez que d’autres restrictions – non détaillées ici car sans rapport avec notre objectif – s’appliquent pour chacune des trois plateformes.
Si le nombre de work-groups requis dépasse les capacités du système, les work-groups excessifs sont dynamiquement distribués à mesure que les ressources matérielles seront libérées. Ce constat est valable quel que soit l’accélérateur. Mais si cette distribution est réalisée matériellement sur les deux GPU, Phi SE10P l’exécute de façon logicielle, ce qui est plus coûteux. Toujours à propos de Phi, notez que le compilateur OpenCL fourni vectorise le code en groupes de 16 work-items dans leur première dimension locale et ce dans un ou deux registres vectoriels selon qu’il s’agit de simple ou de double précision.
L’application Hydro
Hydro est une mini application obtenue à partir du code RAMSES qui permet d’étudier les galaxies à grande échelle. Elle inclut des algorithmes classiques de calcul que l’on peut trouver dans beaucoup de codes des systèmes Tier-0. La version utilisée ici préserve l’algorithme d’origine qui résout des équations compressibles d’Euler en hydrodynamique et se base sur une méthode numérique en volume fini utilisant un schéma explicite de second ordre. Hydro compte environ 5 000 lignes de code et est disponible dans plusieurs versions dont une en pur C avec support OpenMP/MPI et OpenACC. C’est celle que nous utilisons dans cet article.
L’implémentation OpenACC compte 22 noyaux générés en OpenCL par le compilateur CAPS. Le gain de performance obtenu est relativement élevé sur les accélérateurs : on atteint environ 4X avec K20c, par exemple, par rapport à une version OpenMP/MPI tournant sur un CPU dual-socket Westmere. Dans la version accélérée, l’ensemble des noyaux est exécuté sur l’accélérateur. De ce fait, les communications représentent une part insignifiante des temps de traitement (les transferts sont réalisés au tout début et à la fin). Bien qu’ils constituent un réel problème dans nombre d’applications, les transferts nécessaires sont les mêmes pour tous les accélérateurs à mémoire non intégrée. Le coût des communications dépend donc principalement de la performance du bus PCIe et non du code OpenCL généré, si bien que nous le comptabiliserons pas.
Parce qu’elle applique aux accélérateurs une charge de calcul réaliste, Hydro se prête particulièrement à notre étude. Plus homogène qu’une série de noyaux benchmark, elle permet également d’obtenir le détail d’un profil de performance, chose quasiment impossible avec des applications industrielles tant leur niveau de complexité est élevé et les profils d’exécution nombreux. Par ailleurs, ses noyaux présentent des caractéristiques variées, avec des possibilités d’optimisation différentes même en ne considérant que la taille des work-groups. Certains de ces noyaux sont très calculatoires, d’autres se limite quasi-exclusivement à des accès mémoire. Enfin, bien que tous les noyaux bénéficient d’un bon parallélisme de données, celui chargé de la réduction prend un temps d’exécution significatif.
La taille de notre problème représente une grille de 4 091 par 4 091 avec des blocs de taille 1 000. Le choix d’un nombre premier pour définir la taille de la grille permet d’écarter tout comportement spécifique qui pourrait biaiser les résultats en faveur ou au détriment des caractéristiques de telle ou telle architecture (accès mémoire trop bien alignés, comportements de cache excessivement mauvais…). La taille du problème est également choisie de manière à remplir au maximum la mémoire de l’AMD 7970 en utilisant la configuration de blocs donnée – sachant que les deux autres architectures pourraient exécuter une taille de problème plus grande. Enfin, précisons que notre taille de bloc permet de scinder de larges domaines en blocs adéquats à un espace mémoire limité : de petites tailles de blocs optimisent le découpage de gros domaines alors que de larges blocs améliorent la performance sur des architectures à parallélisme de données. Une valeur de 1 000 est un compromis qui s’avère fonctionner de manière raisonnable sur toutes les architectures testées.
Principe de génération du code OpenCL
La version OpenCL des noyaux est produite par le compilateur OpenACC de CAPS, une technologie source à source capable de générer du code OpenCL à partir de versions C et Fortran. Ce compilateur supporte les directives OpenACC et un jeu de directives additionnelles dédiées à l’optimisation. Ces dernières permettent d’évaluer de manière efficace différentes versions OpenCL d’un même code. La version du compilateur utilisé projette l’espace d’itération des boucles sur l’espace d’itération « NDRange » d’OpenCL, faisant ainsi correspondre une itération de la bouche la plus interne à un work-item OpenCL. Les work-items sont groupés en work-groups dont la taille local size est soit paramétrable à l’aide de directives spécialisées, soit définie par défaut via une option du compilateur. Cette taille locale détermine le nombre de work-groups créés pour chaque espace d’itération. Elle joue énormément sur la performance du code, en tous cas pour Hydro. La configuration du noyau généré par le compilateur CAPS est appelée thread grid, une terminologie empreinte de celle utilisée par CUDA.
Enfin, afin de s’assurer que la génération de code en elle-même n’influe pas de manière trop importante, nous avons comparé la performance des noyaux OpenCL générés à celle des noyaux OpenCL développés au préalable. Les versions générées par le compilateur CAPS s’avèrent aussi performantes que celles écrites à la main lorsque exécutées sur Phi SE10P, voire plus performantes sur K20c. Il est à noter qu’une version CUDA du code n’améliore pas les performances sur K20c.
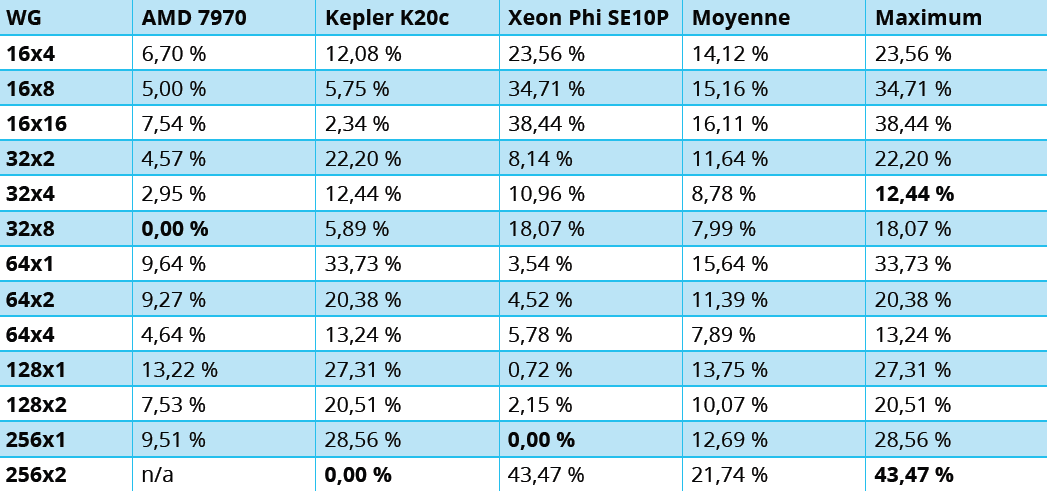
Différentes configurations de grilles ont été sélectionnées pour réaliser l’expérience, dont les résultats sont reproduits au tableau 1. L’ensemble de ces grilles peut être exécuté sur Phi SE10P et K20c, mais quelques configurations n’ont pas fonctionné sur AMD 7970. Les tailles locales des work-groups choisies pour cette expérimentation sont celles qui fonctionnent raisonnablement bien. Ont été écartées celles qui montraient de mauvaises performances sur les trois architectures ainsi que celles qui ne fonctionnaient pas sur le GPU AMD.
Évaluation
La première évaluation a traité du cas le plus simple, qui utilise les valeurs par défaut du compilateur sans jouer avec la génération de code. Dans ce cas, tous les nids de boucles sont transformés en noyaux OpenCL par le même procédé de “gridification” et avec la même valeur local size définie par défaut par le compilateur, à savoir 32×4. Les évaluations suivantes ont consisté de façon très simple à changer cette valeur au niveau de la ligne de commande du compilateur et pour tous les fichiers et noyaux de l’application.
La performance indiquée est une performance relative à la meilleure performance obtenue. Elle est notée “perte d’efficacité” (EL pour Efficiency Loss). De manière plus formelle, la valeur EL d’un code est défini par l’équation (temps d’exécution – meilleur temps d’exécution) / meilleur temps d’exécution. “Meilleur temps d’exécution” représente le temps relatif à une architecture donnée et “Temps d’exécution” celui mesuré pour une grille de threads donnée.
Les mesures d’EL en gras indiquent la meilleure configuration de grille pour l’accélérateur correspondant. En raison des contraintes matérielles évoquées précédemment, la configuration 16×32 n’a pas pu être exécutée sur le GPU AMD. Cette configuration est cependant conservée dans le tableau car elle est la meilleure que nous ayons trouvée pour K20c.
Pour déterminer la configuration optimale, certains voudront minimiser la perte d’efficacité parmi les 3 accélérateurs. La valeur 32×4 est celle pour laquelle la perte d’efficacité maximale est la plus faible (12,44 %). Cette configuration n’est cependant pas celle qui offre la meilleure performance quel que soit l’accélérateur choisi. A contrario, utiliser une configuration optimale pour un accélérateur donné montre une importante dégradation de la performance pour les autres accélérateurs. C’est le cas par exemple de la configuration 256×1 qui profite le mieux à Phi SE10P mais dégrade la performance de 29 % sur K20c. Dans l’autre sens, la configuration 16×32 optimale pour K20c est la pire pour Phi SE10P, avec 43 % de perte d’efficacité.
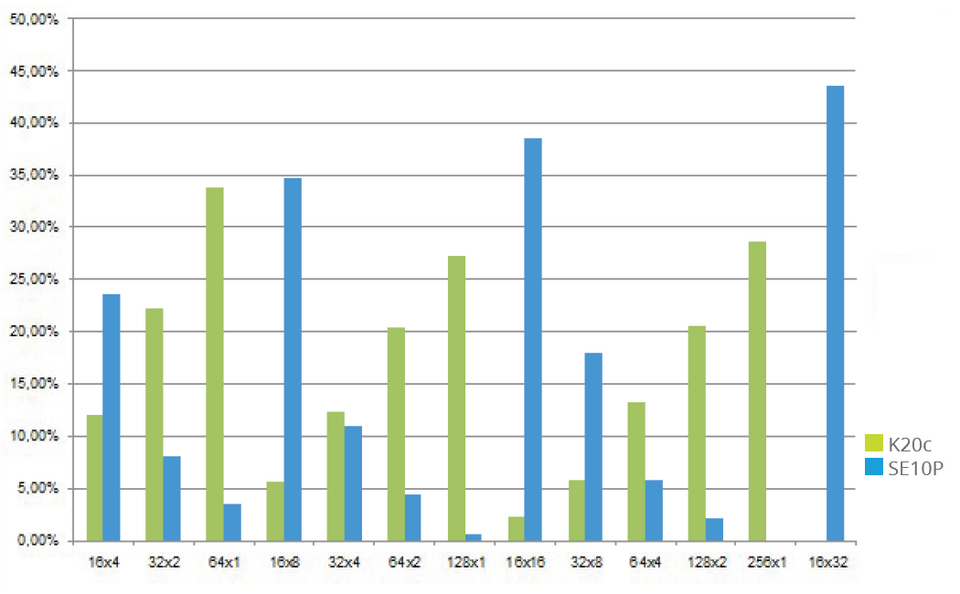
La figure 1 illustre la corrélation de performances entre Phi SE10P et K20c (les chiffres les plus faibles sont les meilleurs). Le graphique montre qu’incrémenter la première dimension des work-groups (16, 32, 64) dégrade les performances sur K20c et les améliore sur Phi SE10P. En conséquence, aucun des accélérateurs ne peut être utilisé pour prédire le comportement des autres.
Conclusion
Si OpenCL fournit une couche de programmation portable sur une large variété de technologies accélératrices, l’optimisation reste problématique lorsqu’un même code doit être déployé sur différentes plateformes. Ce que notre étude révèle, c’est que l’exécution d’une seule version de code sur plusieurs accélérateurs nécessite la recherche du meilleur compromis entre efficacité moyenne et meilleure performance. Le cas exposé ici démontre qu’obtenir une version portable d’un même code est possible si perdre 12 % d’efficacité peut être considéré comme acceptable.
Si la performance ultime n’est pas l’objectif, alors la portabilité peut être envisagée. On a également pu voir qu’il n’est pas indispensable d’intégrer du code auto-adaptif – lequel induit des temps d’exécution supplémentaires et complexifie les algorithmes. A partir des résultats obtenus, nous projetons de reconduire cette étude avec d’autres applications, de façon à identifier les contextes dans lesquels les codes auto-adaptifs sont véritablement nécessaires. Restez à l’écoute…
[1] K.Komatsu, K. Sato, Y.Arai, K. Koyama, H. Takizawa, and H. Kobayashi. Evaluating performance and portability of OpenCL programs. In The Fifth International Workshop on Automatic Performance Tuning (iWAPT2010), 2010.
[2] S. Rul, H. Vandierendonck, J. D’Haene, and K. De Bosschere. An experimental study on performance portability of OpenCL kernels. 2010.
[3] S. Grauer-Gray, L. Xu, R. Searles, S. Ayalasomayajula, and J. Cavazos. Auto-tuning a high-level language targeted to GPU codes. In Inpar 2012, 2012.
[4] T. Lutz, C. Fensch, and M. Cole. Partans : an auto-tuning framework for stencil computation on multi-GPU systems. ACM Trans. Archit. Code Optim., 9(4) :59 :1—59 :24, Jan. 2013.
[5] R. Miceli, G. Civario, A. Sikora, E. Cesar, M. Gerndt, H. Haitof, C. Navarette, S. Benkner, M. Sandrieser, L. Morin, and F. Bodin. Autotune : a plugin-driven approach to the automatic tuning of parallel applications. Proceedings para 2012 : workshop on state-of-the-art in scientific and parallel computing, Helsinki, Finland, June 10-13, 2012.
[6] H. Jordan, P. Thoman, J. J. Durillo, S. Pellegrini, P. Gschwandtner, T. Fahringer, and H. Moritsch. A multi-objective auto-tuning framework for parallel codes. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, SC12, pages 10 : 1-10 :12, Los Alamitos, CA, USA, 2012. IEEE Computer Society Press.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















