
To benchmark this, we have used the SMG2000 application compiled with Intel MPI on the Stampede cluster, using 4 096 cores and the following parameters:
mpiexec.hydra –n 4096 … ./smg2000 -n 120 120 120 -c 2.0 3.0 40 -P 16 16 16
Activating UD with Intel MPI involves the definition of two environment variables:
export I_MPI_DAPL_UD_PROVIDER=ofa-v2-mlx4_0-1u
export I_MPI_DAPL_UD=enable
To recap, Intel MPI supports different types of communication protocol, but it is mainly optimized for DAPL.
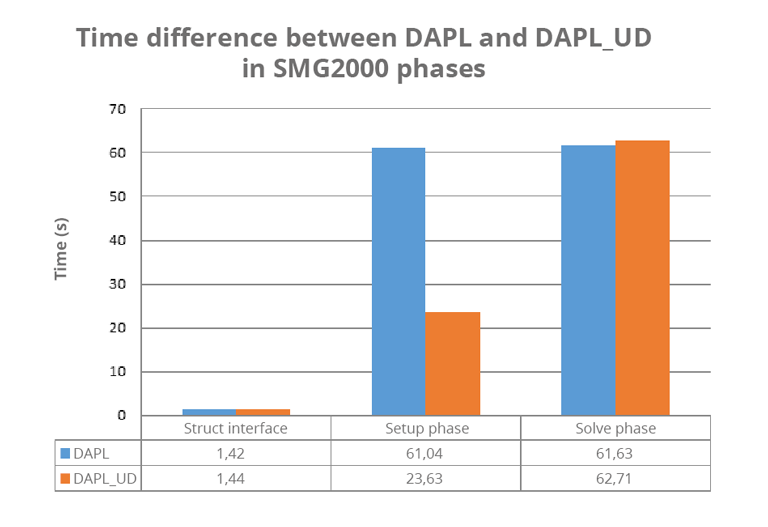
A parallel multigrid solver, SMG2000 is one of the “ASC Purple Benchmarks”, a sequence of tests developed by Lawrence Livermore National Laboratory (LLNL). SMG2000 is arranged into three phases: “Struct interface”, “Setup phase” and “Solve phase”. Figure 2 shows the average execution time of each of these phases in ten operations with and without UD.
As you can see, the execution times indicated for the first and last phases are more or less identical. However, the difference involving the Setup phase is significant. The explanation is simple: this phase mainly involves small point-to-point non-blocking communications between different MPI processes. Because UD does not require a connection, messages are dispatched very quickly. When you realize that 1 060 841 238 messages have been exchanged, you can see that the small time saving for each communication eventually translates into an appreciable overall acceleration.
Another advantage associated with UD: as a rule, the boot-up time for MPI programs is much shorter. A simple Hello World with 16K cores can take over one and a half minute with DAPL, whereas it starts in under 30 seconds with DAPL_UD.
What about applications using large messages? That’s quite another story. Since dispatches using UD cannot exceed the size of the MTU, long messages require more packets, with a greater risk that these packets will be lost. In view of this, memory consumption can turn out to be significantly greater, according to case.
Interim conclusion
This article set out to examine two different approaches intended to optimize the scalability of applications using the InfiniBand network. Which is better? As we have seen, it all depends on your MPI library and your application. If it needs to handle large messages, XRC may be more effective on a large scale, although we have not been able to test this properly for the technical reasons mentioned above. On the other hand, if the messages in your application are of modest size – that is, smaller than the MTU – UD may be a better option, provided that your MPI library can support it. And for the future?
Mellanox’s new family of Connect-IB interconnections offers a new protocol called “Dynamically-connected transport”, designed specifically to reduce memory consumption. How does this protocol compare with the other two in the instances we have cited? Given that our lab has not yet deployed the cards, this is difficult to ascertain. We will be returning to this in detail as soon as the test conditions are in place. In the meantime, if you can benchmark the system yourself, we would be glad to hear your results. After all, isn’t it the aim of this section to be a collaborative effort, sharing best practice in HPC development?
More around this topic...
Related articles


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}