
Today we have multiple cores per socket and the vector sizes per thread are ever-growing. Therefore in HPC, you can no longer simply distribute your load onto the nodes and let them do their work sequentially – you usually use one or two more levels of parallelization. Here’s where accelerators come into play: If you have to do all that multithreading implementation – why not make it worthwhile? Why care about six or eight threads if we can have thousands? What if your application is limited by memory bandwidth rather than computation? Well, today’s accelerators have 200-300 GBs of memory bandwidth, so compared to around 50 GBs on the CPU…we’re still good, right?
But wait!
How about the fact that we need to copy our data back and forth between the main memory and the accelerator memory over a slow (5 GBs) PCI Express bus? Won’t this kill any kind of potential speedup we could get by using the higher memory bandwidth on the device? Well yes, that’s the biggest gotcha: We need to integrate as much of our program onto the device as possible, so that we can iterate while keeping most of the memory on the device. You come up with some simple formulas to figure out whether a speedup is possible.
But wait!
You notice a problem. Since in the past, creating new processes or threads has been expensive, your existing program has been parallelized as coarse-grained as possible. In parts of your code, you have a single big parallel loop going over your parallel domains X and Y, with lots of zero- or single dimensional sequential operations (several 10k code lines in a deep call graph) executed inside this loop. In the simple examples you’ve done for GPGPU code, be it CUDA, OpenCL or OpenACC, all you’ve ever seen are tight loops over a few hundred lines of code, tops. You learn that GPUs are not good with deep call graphs – its context switching is limited to kernels, so everything going on within a kernel (essentially a parallel loop) needs to be inlined. You’re trying to do this with an OpenACC enabled compiler, but at around the second call graph level you give up.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






Trending this week...
















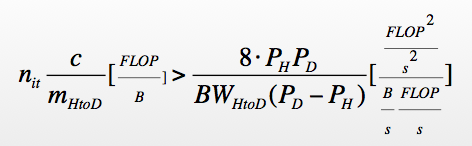{kind=link}
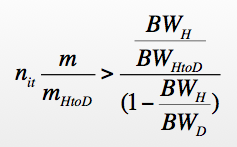{kind=link}
{kind=link}