
Fujitsu Laboratories Ltd. announced the release of a new technology to streamline the internal memory of GPUs to support the growing neural network scale that works to heighten machine learning accuracy. According to Fujitsu, this development has enabled neural network machine learning to double its performance compared to previous technology.
In the recent years, the focus has been on technologies using GPUs for high-speed machine learning supporting huge volumes of calculations necessary for deep learning processing. But to make use of a GPU’s high-speed calculation ability, the data needs to be stored in the GPU’s internal memory. This, however, creates an issue where the scale of the neural network is limited by memory capacity. According to Fujitsu, its new technology improves memory efficiency. Upon commencement of learning, the technology analyzes the structure of the neural network and optimizes the order of calculations and allocation of data to memory, so that memory space can be efficiently reused. With AlexNet and VGGNet, image-recognition neural networks used in research, this technology was confirmed to enable the scale of learning of a neural network to be increased by up to roughly two times. Also, the reduction of internal GPU memory used was over 40%, making it possible to expand the scale of neural networks learning at high speed on one GPU and enabling the development of more accurate models.
The memory issue
Deep Learning has been gaining attention as a machine learning method that emulates the structure of the human brain. In deep learning, the more layers in a neural network, the more accurate it performs tasks, such as recognition or categorization. So to increase accuracy, the scale of neural networks has been growing lengthening learning times. Along with this, more attention is being placed on GPUs that execute computations with large volumes of data, and technology that accelerates the process by using multiple GPUs in parallel, as in supercomputers.
One method of increasing the scale of deep learning is to distribute a single neural network model across multiple computers and do the computations in parallel, but the volume of data that must be transmitted in exchanges between computers creates a bottleneck that greatly reduces learning speed. In order to take full advantage of the GPU’s high-speed calculation capability, the data needs to be stored in the GPU’s internal memory. However, as GPU memory is usually smaller than that of an ordinary computer, there is a limitation in the scale of neural networks capable of high-speed learning.
The Fujitsu solution
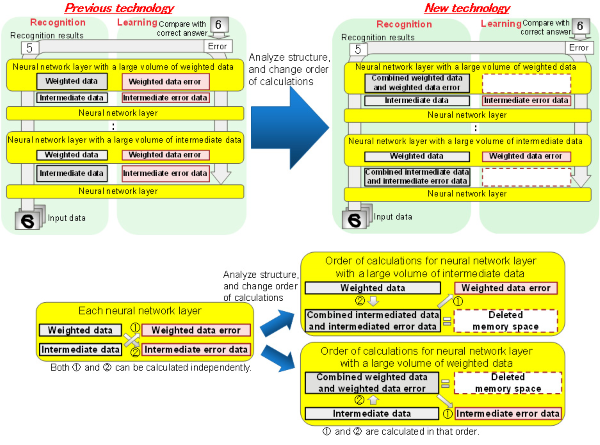
Fujitsu Laboratories have developed a technology to streamline memory efficiency in order to expand the scale of a neural network for computations with one GPU, without using parallelization methods. This technology reduces the volume of memory by enabling the reuse of memory resources; it takes advantage of the ability to independently execute both calculations to generate the intermediate error data from weighted data, and calculations to generate the weighted data error from intermediate data. When learning begins, the structure of every layer of the neural network is analyzed, and the order of calculations is changed so that memory space in which larger data has been allocated can be reused.
Fujitsu Laboratories will commercialize this technology as part of Fujitsu Limited’s AI technology, Human Centric AI Zinrai, by March 31, 2017. In addition, the company plans to combine this technology with its already announced high-speed technology to process deep learning through GPU parallelization, and further improve both technologies.
More around this topic...
Related articles











© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}