
Is PCI Express destined to become a rival to interconnect systems such as Ethernet and InfiniBand? That, anyway, is the intent of two US companies, PLX Technology and A3Cube, both of which are preparing extensions to point-to-point PCIe links that would open the connector to data exchanges between servers – that is, not only within servers anymore.
The underlying idea is to eliminate part of the support electronics, thereby reducing the cost of clusters while providing the same levels of latency and throughput as Ethernet or InfiniBand. In other words, it would allow an Ethernet stream to flow through a PCI Express switch without having to pass through the entire Ethernet system stack.
A prerequisite for a real increase in energy efficiency, the reduction of active components makes this concept fairly obvious. CPU, memory, storage and communication devices – all of which impact computations and data flow – already communicate with PCI Express. It is therefore quite logical to try to bypass the translation / re-translation phases, to maintain the flow of data within a single channel, and thus to get rid of peripheral interconnect components that are both expensive to purchase and to use.
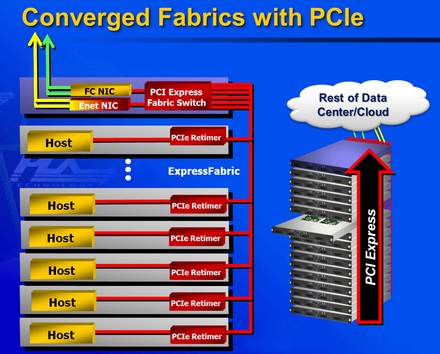
Considering that the system offered by PLX, ExpressFabric, consumes only 1 Watt and costs about $5 (compare that to an Ethernet interface that costs several hundred dollars and consumes up to ten Watts), the benefits add up quickly! But then, why haven’t we seen such alternatives earlier? Aside from emotional attachment to Ethernet and InfiniBand, the answer lies in the difficulty of implementation. The PCI Express standard does not allow such switches to be implemented without changing the software stack. Which is why PLX added its own extensions, compliant with the standard and capable of being used with existing PCI components.
With a first commercial implementation scheduled for the end of the year, ExpressFabric targets midsize systems of a few hundreds to a few thousands of nodes assembled in a maximum of eight racks. In terms of performance, simulations have shown a bandwidth similar to that of QDR InfiniBand. We’re expecting real-life benchmarks anytime soon.
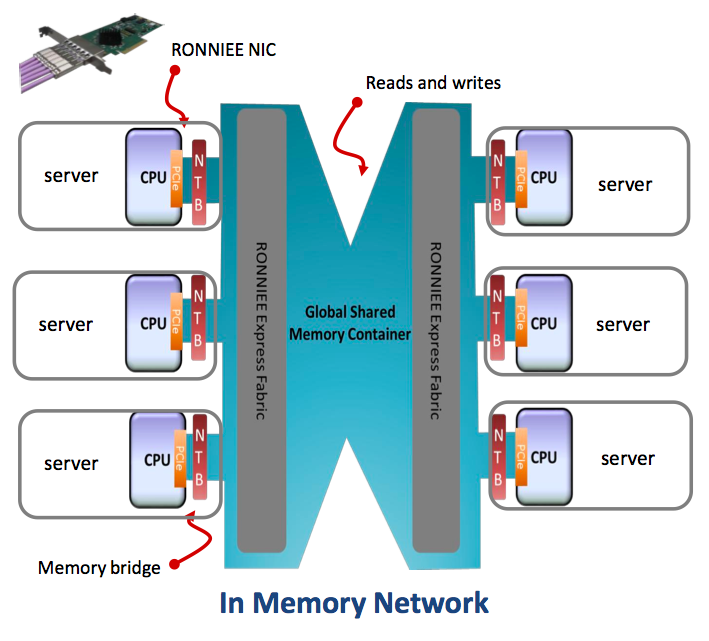
On A3Cube’s side, the approach is somewhat different and aims at larger systems than PLX. Rather than pass messages over PCI Express, A3Cube directly uses PCIe memory addressing to create TCP/UDP sockets. Thus, no additional latency and full compatibility with TCP/UDP applications.
The A3Cube PCI Express switch is embedded in a card, called Ronnie, which is identified like an Ethernet interface by applications. Positioned at the ends of racks and/or rows of racks, it is already marketed with a native MPI-2 stack. Several variants are also available to connect up to 64,000 nodes in a 3D torus topology. The tests carried out on a 128-node system showed a maximum latency of 10 ms between any node. Now the question is whether this level of performance will hold in less synthetic machines.
More around this topic...










© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}
{kind=link}