
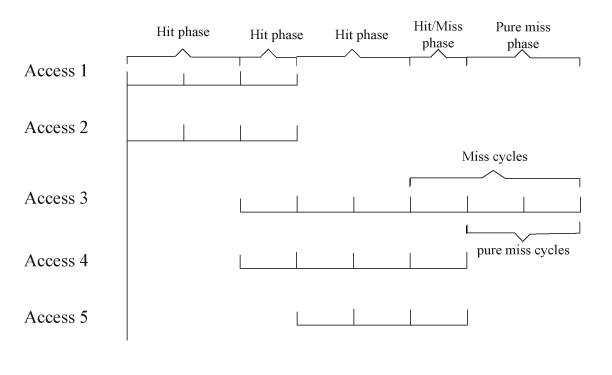
Fig. 1 provides a demonstration example to illustrate the “pure miss” and hit cycle concept. It contains five different memory accesses, and each access contains 3 cycles for cache hit operations. If it is a miss, additional miss penalty cycles will be required, and the number of miss penalty cycles is uncertain. Access 1, 2, and 5 are hit accesses; Access 3 and 4 are miss accesses. Access 3 has a 3-cycle miss penalty; Access 4 has only a 1-cycle miss penalty. When considering the access concurrency, only Access 3 contains 2 pure miss cycles. Though Access 4 has 1 miss cycle, this cycle is not a pure miss cycle, because it overlaps with the hit cycles of Access 5. Therefore, the (pure) miss rate of the five accesses is 0.2, according to our new definition of concurrent (pure) miss rate, instead of 0.4 for the conventional non-concurrent version. The reason for bypass misses whose cycles are overlapping with hit accesses is that this kind of miss accesses will not cause processor stall; the processor can continue processing with the hit accesses. According to Eq. 2, C-AMAT is 8 cycles out of 5 accesses or 1.6 cycle per access; whereas by Eq. 1 AMAT is 3 + 0.4 × 2 or 3.8 cycle per access. The difference between C-AMAT and AMAT is the contribution of concurrent data access. In this example, concurrency has doubled memory performance.
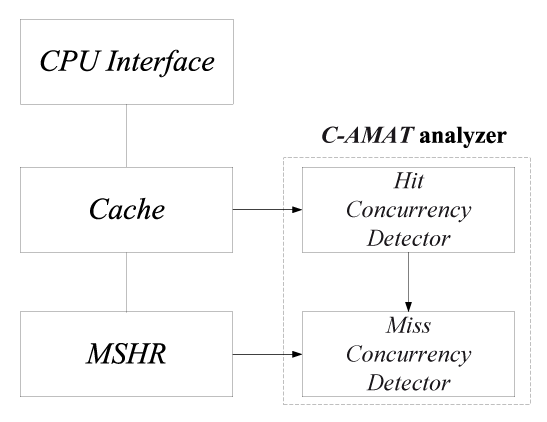
Fig. 2 shows a detecting structure of C-AMAT. The Hit Concurrency Detector (HCD) counts the total hit cycles and records each hit phase in order to calculate the average hit concurrency. The HCD also tells the Miss Concurrency Detector (MCD) whether a current cycle has a hit access or not. The MCD is a monitor unit which counts the total number of pure miss cycles and records each pure miss phase in order to calculate the average miss concurrency, pure miss rate, and pure miss penalty. With the information provided by the HCD, the MCD is able to tell whether a cycle is a pure miss cycle, and whether a miss is pure miss. With the miss information, the pure miss rate and average pure miss penalty can be calculated. These parameters can be measured at each layer of a memory hierarchy. Therefore, C-AMAT also can be measured at each layer of a memory hierarchy.
Please notice that the contribution of C-AMAT is not its measurement. The measurement can be obtained directly through APC [6]. The measurement of C-AMAT does not depend on the measurement of its five parameters. The value of the parameters is in performance analysis and optimization. The indispensable contribution of C-AMAT is that it gives a unified formulation to capture the joint performance impact of locality and concurrency. C-AMAT contains AMAT as a special case where memory concurrency does not exist, and provides a mean to evaluate and optimize the five performance parameters, individually or in combination. It provides a tool for design optimization.
Readers who are familiar with AMAT may recall that the average miss penalty of AMAT can be extended recursively to the next layer of a memory hierarchy. This recursiveness is true for C-AMAT as well. Eq. 3 shows the recurrence relation of C-AMAT1 and C-AMAT2. That is extending C-AMAT from the L1 level to L2 level. Please notice here that we have introduced a new parameter, ɳ1, and the impact of C-AMAT2 toward the final C-AMAT1 has been trimmed by pMR1 and ɳ1. pMR1 x ɳ1 is the concurrency contribution in reducing average memory (access) delay at the L1 level. ɳ1 only has one new parameter, Cm, which is the miss concurrency. Please notice that we use CM (capital M) to represent the pure concurrent misses and use Cm (little m) to represent concurrent misses. ɳ1 is a measureable parameter and has physical meanings. The number of misses occurred on L2 is Cm and the number of misses that matters to the L1 performance is CM. Similarly, the argument applies to pAMP and AMP. In a similar fashion as Eq. 3, C-AMAT can be extended to the next layer of the memory hierarchy.
Eq. 3 – \(C{-}AMAT_{1} = \frac{H_{1}}{C_{H_{1}}} + pMR_{1} \times ɳ_{1} \times C{-}AMAT_{2}\)
where
\(C{-}AMAT_{1} = \frac{H_{1}}{C_{H_{1}}} + pMR_{1} \times \frac{pAMP_{1}}{C_{M_{ 1}}}\) ,
\(C{-}AMAT_{2} = \frac{H_{2}}{C_{H_{2}}} + pMR_{2} \times \frac{pAMP_{2}}{C_{M_{ 2}}}\) ,
\(ɳ_{1} = \frac{pAMP_{1}}{AMP_{1}} \times \frac{C_{m{1}}}{C_{M{1}}}\)
APC is a performance metric and its value is the inverse of C-AMAT [1]. The correctness and measurement of APC are well studied in [6]. Therefore, the correctness of the measurement of C-AMAT is guaranteed. At the first look, APC (Access Per Cycle) seems to be very similar to the well-known metric IPC (Instruction Per Cycle). But, in fact, the cycle used in APC is completely different with the cycle used in IPC. They are different in definitions, and different in measurement. In APC, the cycles are memory active cycles. They are not CPU cycles, as used in IPC. So APC can also be named as APMAC (Access Per Memory Active Cycle). Also APC uses the overlapping mode to count memory access cycles. That is, if two or more data accesses occur at the same time, the cycle only increases by one. The two differences between APC and IPC are crucial. The replacement of CPU cycle with memory active cycle separates the APC measurement with the CPU performance. The separation makes applying APC on each level of a multi-level hierarchical memory system possible, and leads to a better understanding of the matching between computing systems and memory systems. This replacement represents the shift from the traditional compute-centric thinking to a data-centric thinking in studying memory systems. Overlapping is the concept of parallel data access and overlapping cycles is a measurement of parallel data accesses. C-AMAT introduces the concept of parallel memory systems and provides a tool for evaluating and designing parallel memory systems. C-AMAT has opened a new door to computer hardware development and algorithm design.
C-AMAT is a model calling for rethinking of memory and computing system design. It is simple and effective. It has a unified mathematical expression considering both data locality and concurrency, and is based on a rigorous analytical and mathematical proof. C-AMAT makes the contribution of concurrent data accesses toward the overall system performance measureable, and therefore provides a mean to optimize concurrent data accesses. C-AMAT calls for a rethinking of the design of computer architectures and algorithms to consider memory concurrency and to consider the interaction between memory concurrency and locality. C-AMAT will make a noticeable impact on the next generation of computers and their associated software development and algorithm design.
C-AMAT is a joint work of Dr. Dawei Wang and the author, and the application of C-AMAT is a joint work of Dr. Yuhang Liu and the author. Dr. Yuhang Liu provided valuable help in writing this article.
Dr. Xian-He Sun is a distinguished professor of Computer Science and the Chairman of the Department of Computer Science at Illinois Institute of Technology (IIT). He is an IEEE fellow, a guest faculty in the Mathematics and Computer Science Division at Argonne National Laboratory, and the director of the Scalable Computing Software laboratory at IIT. He is an editor of eight international professional journals, and has served and is serving as the chairman or a member of the program committee for numerous international conferences and workshops. His current research interests include parallel and distributed processing, memory and I/O systems, software systems for Big Data applications, and performance evaluation and optimization. He has published over two hundred research articles in the field of computer science and communication. Based on Google Scholar, his works have been referenced 2,694 times during the last five years since 2009 (1/16/2014 data).
More around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}
{kind=link}
{kind=link}