
A needle in a thousand haystacks
Let us now put ourselves in the post-experimental phase. For the IT team, the mission is to offer the best possible performance in accessing the databases that index the raw data. This is recorded in ROOT flat files, which are then stored in a hierarchical system called CASTOR (see our two detailed boxes). The context, as well as the processing, is thus almost identical to those of a large Big Data application. More and more, to extract pertinent information from the enormous mass of available data, datasets are run through starting from predictive analyses.
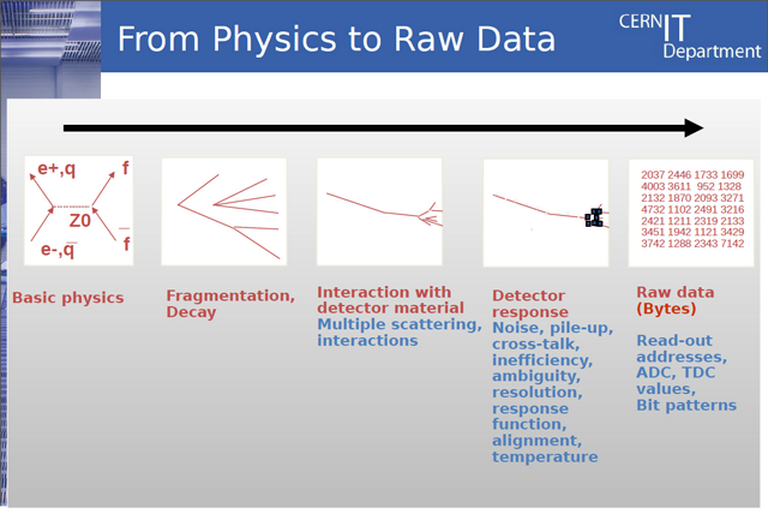
Fig.1 – The chain of collection for experimental data. In this direction, the operations primarily focus on the filtering by coherence, resolution and relevance. This filtering also has an important role to play with regards to the disambiguation of detected phenomena. At this stage, the throughput aspect takes precedence over the calculation aspect. (CERN document)
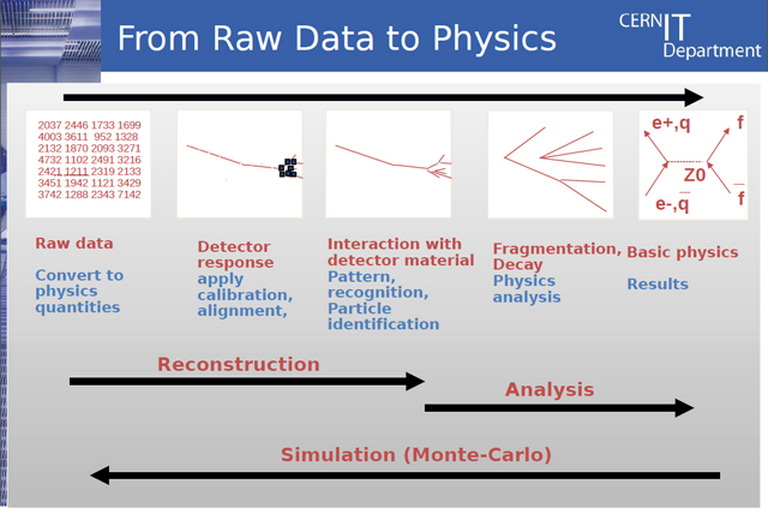
Fig.2 – In the other direction, the reconstruction of phenomena from the data initially collected also supports simulation analysis. It is in this sense that data operations are the most demanding from a computation standpoint. (CERN document)
In practice, the system rests on five “critical” functional pillars, as Eric Grancher, the Database Architect in the IT team, explains:
• 10 GbE connections, a standard technology that is both scalable and easy to manage. These connections allow using the same switches as in many other subsystems in the Centre and offer the advantage of being maintained by CERN’s network team, which provides 24/7 support.
• The Oracle dNFS file system, which offers several storage paths. dNFS has the particular feature that it bypasses the operating system, which results in an almost double performance level, with another advantage of weight: Oracle generates NFS requests directly from the databases, so the system requires almost no configuration or maintenance.
• Plain SATA disks coupled to a special cache technology that offers a level of performance comparable to Fibre Channel drives at a fraction of their cost. Considering the number of disks used in CERN (more than 64,000, see the box below) the cost aspect is really determining here.
• An instantaneous volume cloning technology that allows the creation of modifiable copies of datasets on the fly. This technology, called FlexClone, is of NetApp origin. The instantaneous aspect offers a second benefit in such a particular context: whatever the number of scientific teams working on a dataset, no data is duplicated.
• Lastly, the NetApp ONTAP 8 system, which enables the addition of storage bays and the displacement of data without interrupting the experiments in progress. This permanent continuity is one of the infrastructure’s strong points: it is a condition of maximum availability while the cluster mode makes it possible to fill all kinds of scaling needs.
When CERN started operation, the IT team chose a NAS-type architecture with SATA disks in RAID 1 – a surprising option compared to the more standard SAN FC alternative. However, after several years of intensive use, the statistics speak (by the voice of Eric Grancher): “Since 2007, we did not have any downtime connected with SATA disks, and we have not lost a single data block. Clearly, the reliability is as good as in FC technology.“
At the end of this introductory tour, the conclusion is that current technologies enable managing the most complex data and the most enormous volumes. If the case of CERN represents the paroxysm of scientific Big Data, the paths followed are certainly not the only ones possible. But they have the merit of efficiency, a quality acclaimed by all the researchers who have had the privilege of putting them into practice. Some technical issues mentioned along our visit call for a more thorough examination. That is the role of the boxes that complete this story.
The LHC for dummies
Among the particle accelerators at CERN, the Large Hadron Collider (LHC) is certainly the most famous. Inaugurated in 2008, it forms a 27 km (16.13 miles) long circle adjacent to the Franco-Swiss border, about 100 meters underground the Alps.
The ring consists of superconducting magnets and acceleration structures designed to increase the particles’ energy. Inside the ring, and then inside dedicated containers, the beams circulate in opposite directions. It is the magnetic fields from the superconducting magnets that guide them, the magnets being themselves cooled by liquid nitrogen and liquid helium so that their temperature remains at about -271°C. The infrastructure has been designed for the beams to collide in certain areas of the ring equipped with detectors. Several international teams are working on separate experiments involving specific detectors, which allows them to conduct collaborative studies on the material produced by the collisions. In cruise-mode, the LHC generates about 600 million collisions per second. Dedicated codes convert raw data into data objects for later analysis. Today, the annual volume of new exploitable information reaches in excess of 20 PB.
More around this topic...









© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















