
Romaric David, UNISTRA.
(Cet article fait partie de notre dossier JDEV 2013 : Développer pour calculer)
Vue de loin, la performance de nos ordinateurs ne cesse d’augmenter. Cependant, à y regarder de plus près, cette augmentation de performance se traduit par une forte complexification des architectures (plusieurs cœurs par processeur, plusieurs niveaux de cache, unités vectorielles, présence d’accélérateurs…). Or, sans effort particulier de la part du programmeur (ou du compilateur), ces améliorations technologiques sont sans bénéfice sur les codes. Il est donc indispensable de comprendre le principe fonctionnel des architectures pour pouvoir en tirer le meilleur parti et ainsi améliorer les performances de son application.
L’atelier Performances a illustré, sur des exemples simples (notamment les Stream Benchmarks), quelques-uns des principaux mécanismes d’optimisation permettant d’augmenter la vitesse d’exécution d’un programme. Ont ainsi été mis en pratique par les participants et avec un bénéfice immédiatement
mesurable :
– le déroulage de boucles ;
– la vectorisation ;
– la restructuration des données pour bénéficier du cache.
Métrologie
L’atelier a également insisté sur les outils de métrologie, du plus simple au plus évolué. En effet, qu’est-ce qu’un programme performant ? La réponse spontanée pourrait être : “un programme rapide”. Ce n’est évidemment pas faux, mais si la vitesse d’exécution est le paramètre clé ressenti par l’utilisateur, rappelons que la consommation en ressources (mémoire, énergie) correspond aussi à un coût, coût financier dans les modèles de paiement à l’usage (cloud). De même, la consommation de ressources d’entrées/sorties (disque, réseau) touche directement l’écosystème d’une application.
Durant l’atelier, puis lors d’une école (http://calcul.math.cnrs.fr/spip.php?article233 ) sur l’optimisation de performances co-organisée par le Groupe Calcul et la Maison de la Simulation, nous avons présenté trois outils simples pour quantifier le comportement d’une application :
– mesure globale du temps par le système d’exploitation, à utiliser en première intention ;
– instrumentation par le compilateur puis analyse des traces d’exécution par le très versatile gprof ;
– analyse ligne par ligne avec gprof ou gcov.
La méthodologie proposée, centrée sur le temps d’exécution, permet une approche quantitative très précise (granularité : la ligne de code source) du déroulement d’un programme, et d’en identifier les points durs (“hotspots”).
Stratégie
Il y a encore 10 ans, l’architecture d’une machine de calcul typique se résumait grosso modo au schéma de la Fig. 1, où l’on observe une hiérarchie mémoire à double niveau de cache. Le principe de la mémoire cache est, rappelons-le, “loin des yeux loin du cœur” : les données les moins souvent utilisées sont laissées en mémoire classique alors que les données récemment utilisées sont placées dans les niveaux de cache proches (c’est-à-dire à accès rapide) du processeur. Problème : la taille du cache est quelques ordres de grandeur inférieure à la taille de la mémoire vive de la machine. Il est donc indispensable de gérer au mieux cet espace restreint. Pour cela, différentes stratégies existent.
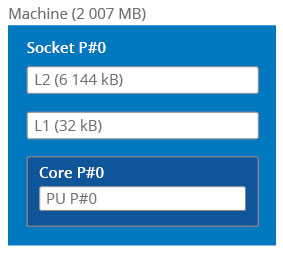
Fig. 1 – Architecture type d’un nœud de calcul datant d’environ 10 ans. La hiérarchie mémoire présente un double niveau de cache.
Aujourd’hui, l’architecture type d’un calculateur se rapproche davantage du schéma de la Fig. 2, où l’on remarque un niveau de cache supplémentaire. Conséquence : si les processeurs peuvent utiliser l’un la mémoire de l’autre, c’est au prix de latences plus importantes. À titre d’exemple, voici la durée des accès mémoires (en cycles CPU) en fonction de l’emplacement des données :
Cache L1 : 1 à 5 cycles
Cache L2 : 10 cycles
Cache L3 : 40 à 65 cycles
Mémoire DDR : 150 à 200 cycles

Fig. 2 – Architecture type d’un nœud de calcul actuel. La hiérarchie mémoire présente un niveau de cache supplémentaire, potentiellement inducteur de latence.
On le voit, aller chercher des données lointaines peut énormément pénaliser le processeur, qui va attendre leur arrivée pendant de nombreux cycles.
Optimisation
Après nous être appliqués à mesurer le temps d’exécution et le comportement mémoire de nos programmes, c’est tout naturellement que nous essayons d’accélérer les traitements en utilisant au mieux l’architecture des processeurs (présence d’unités vectorielles permettant de réaliser plusieurs opérations en un seul cycle) et en restructurant nos données.
Pour réduire le temps d’exécution d’un programme, savez-vous qu’il faut augmenter sa longueur ? Ce constat paradoxal est le résumé que l’on peut tirer de la technique du déroulage de boucle. En effet, en informatique, lorsqu’on apprend à écrire une boucle (par exemple pour parcourir toutes les cases d’un tableau), on factorise le code traitant une case du tableau et on répète le traitement pour toutes les cases. Cette mécanique a un coût : à chaque étape on vérifie que l’on se trouve encore entre les bornes du tableau. On peut diminuer le nombre de tests sur ces bornes en écrivant des boucles qui travaillent sur des tranches de tableaux plus importantes (4, 8 éléments).
Pour réduire le temps d’exécution d’un programme, on peut également y insérer des instructions spécialisées travaillant sur de petits vecteurs. Si le programme agit sur des types élémentaires (nombres entiers, nombres réels), ces transformations altèrent peu la lisibilité du programme. Enfin, nous avons montré qu’une bonne maîtrise de l’architecture des mémoires cache permet d’utiliser des structures de données qui en tirent le meilleur avantage.
Pour aller plus loin : http://devlog.cnrs.fr/jdev2013/t7a5
(Dossier JDEV 2013 : Développer pour calculer : article précédent | suivant)
More around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















