
Issus en droite ligne des premières cartes Tesla lancées en 2006, les nouveaux accélérateurs NVIDIA Kepler franchissent aujourd’hui un palier décisif en termes de performances, d’autonomie et d’efficacité énergétique. En voici les coulisses.
Il faut reconnaître à NVIDIA le titre de précurseur de l’accélération GP-GPU. Depuis 2006, avec une belle constance, le fondeur n’a cessé de développer le concept et de fournir les outils nécessaires à son exploitation, à partir d’une stratégie conciliant l’explosion des performances de ses puces graphiques et la demande croissante de puissance de la part de la communauté HPC. D’où l’importance de la nouvelle architecture Kepler et de ses deux premiers représentants, les processeurs GK110 et GK104S, dédiés respectivement aux calculs en double et simple précision. Forte de cette nouvelle offre, la plateforme GPGPU de NVIDIA voit sa compétitivité clairement réaffirmée. D’abord sur le plan technique, bien sûr, tant les innovations sont nombreuses et leurs bénéfices réels, comme nous allons le voir dans les paragraphes suivants. Mais également sur un plan stratégique, ce qui est peut-être plus important encore, dans la mesure où choisir Kepler en équipement revient à choisir CUDA en développement.
Ce qui frappe, quand on découvre Kepler en profondeur, c’est l’ampleur et l’ubiquité de l’évolution technologique qui la sépare de l’ancienne architecture Fermi. On a l’impression que, dans tous les compartiments du jeu, NVIDIA a poussé les ressources de parallélisation au maximum possible aujourd’hui, avec une cohérence d’ensemble au final bien supérieure. Comme si Fermi avait été le terreau initial et Kepler, implémentant en hard plusieurs années de progrès appliqués, la concrétisation d’une certaine maturité.
Tour de force industriel
Si l’on examine les spécifications pures, le premier chiffre qui frappe, c’est celui des 7,1 milliards de transistors intégrés, qui font de GK110 le processeur le plus dense à ce jour. La puissance maximale en DP ainsi obtenue atteint 1,31 Tflops, soit plus de deux fois celle de l’ancien accélérateur M2090, avec par exemple un niveau d’efficacité en calcul DGEMM amélioré de 33 %. Mais cette débauche d’électronique ne fait pas tout. S’il suffisait d’empaqueter des portes logiques, ça se saurait. C’est plus en profondeur que résident les véritables innovations de Kepler.
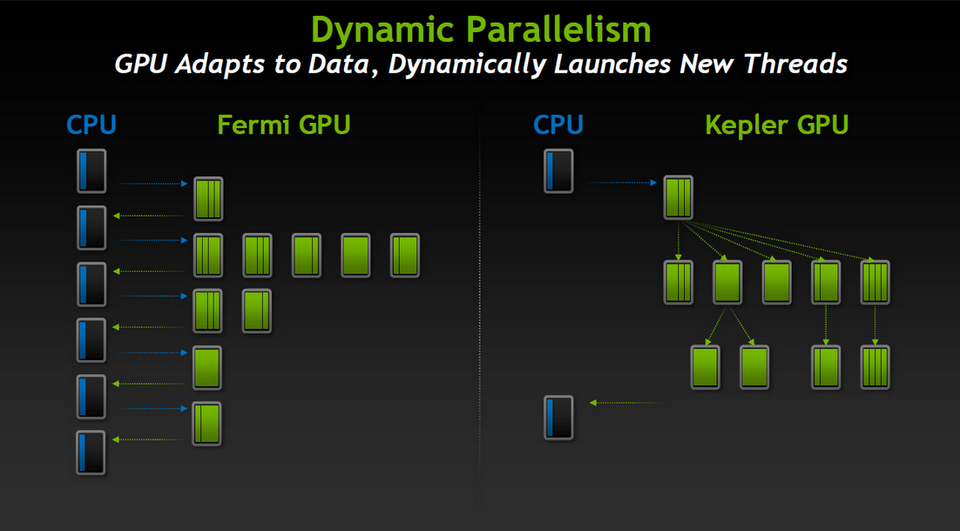
Plusieurs dispositifs architecturaux visent en effet à augmenter l’efficacité à l’intérieur du périmètre de l’accélérateur puis à rendre celui-ci plus autonome, pour limiter autant que possible les latences inhérentes aux échanges avec le reste du système hôte. Le premier de ces dispositifs se nomme parallélisme dynamique. Grâce à lui, le processeur graphique est dans une large mesure libéré du CPU hôte qui n’a plus à jouer le chef d’orchestre en permanence. Une fois les instructions reçues, le GPU ne dépend plus que de lui-même. Il sait répartir les traitements pour in fine synchroniser les résultats de façon optimale.
Automatiser la parallélisation
En pratique, GK110 imbrique les threads sur plusieurs niveaux hiérarchiques pour mieux les paralléliser. Cette automatisation, obtenue par l’intégration de contrôleurs de coordination dédiés, permet au développeur de gagner sur deux tableaux. D’une part, celui de la facilité. L’exécution de tâches moins structurées et plus complexes est accélérée grâce à une meilleure répartition des threads, les cycles d’horloge étant mis à profit pour les calculs plutôt que pour les échanges avec le CPU. D’autre part, celui de la productivité. Le déport sur le GPU des opérations et de leur suivi libère le CPU, ce qui laisse la machine hôte disponible pour d’autres travaux cependant qu’elle calcule. Cette autonomie apporte un troisième avantage que nous détaillerons plus loin : l’amélioration du ratio performances / Watt global (celui du système hôte), d’où des possibilités de scalabilité accrues.
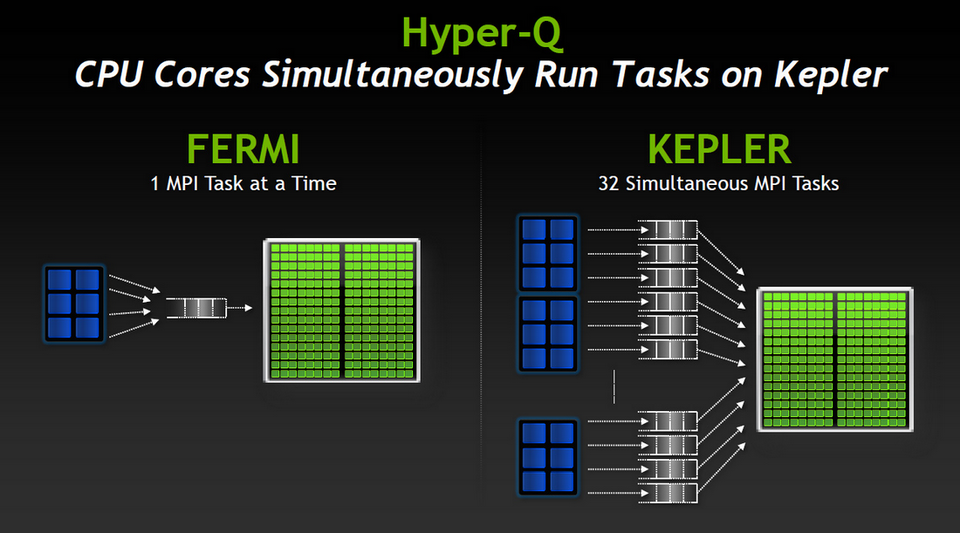
C’est également ce à quoi concourt Hyper-Q, autre innovation structurelle de Kepler. Hyper-Q porte à 32 le nombre de files d’attente d’instructions par GPU, ce qui autorise plusieurs CPU à lancer autant de calculs sur un seul accélérateur en parallèle, là où précédemment l’exécution était séquentielle. La gestion des files d’attente est assurée par une “Grid Management Unit”, qui gère à la fois la répartition des tâches entre CPU et GPU et les priorités d’exécution côté GPU. Cette technologie est très utile dans des contextes de type cluster, où chaque nœud peut être composé de plusieurs cœurs CPU et d’un ou deux accélérateur GPU.
Polyvalent et bidirectionnel, Hyper-Q achemine aussi bien des flux CUDA que des processus MPI (jusqu’à 32 simultanés, contre un seul avec Fermi), ce qui ne limite pas l’avantage à quelques scénarios applicatifs particuliers. De plus, il s’accommode de directives simples ajoutées aux algorithmes non encore parallélisés. On peut donc bénéficier d’une accélération dès la mise en service, sans effort particulier sur les codes sources existants. On aura tout loisir, ensuite, d’affiner le code pour tirer le maximum de son infrastructure matérielle.
Un GPU plus autonome
Gagnant en indépendance, CPU et GPU voient leur rôle mieux défini, donc leur sollicitation explicite plus efficace. Côté GPU, cela se traduit par la possibilité de ne recalculer que des portions d’algorithmes en cas de besoin. Dans de nombreux modèles, notamment en mécanique des fluides, l’altération des paramètres globaux n’aura ainsi pas d’incidence sur les performances d’ensemble. L’objectif, c’est bien sûr de faciliter la simulation d’hypothèses multiples. L’intérêt de cette autonomisation du GPU ira d’ailleurs croissant à mesure qu’augmentera, chez les successeurs de GK110, la densité en transistors.
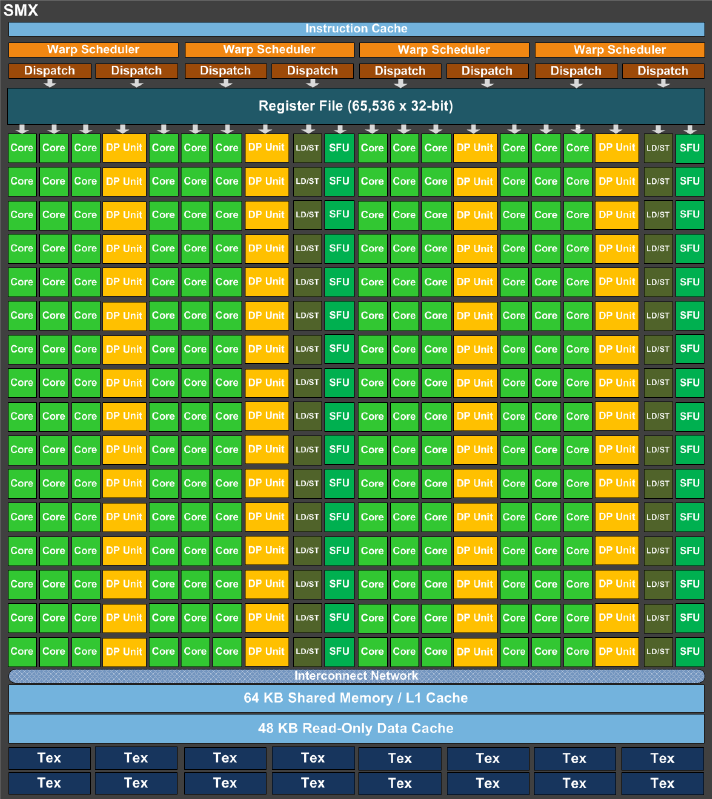
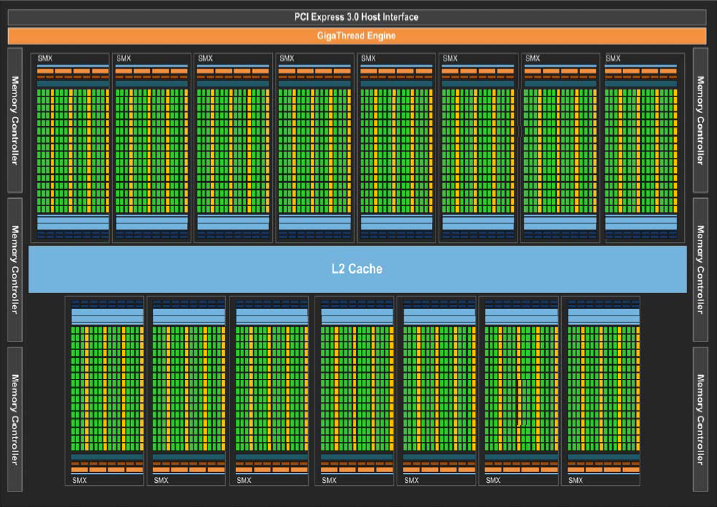
Troisième technologie mise en œuvre par Kepler, SMX (pour Streaming Multiprocessor eXtreme) est peut-être l’évolution la plus déterminante par rapport à Fermi. C’est là, en effet, que se situe le plus gros progrès en matière de parallélisation pure. Rappelons que la performance d’un accélérateur GPU est en grande partie liée au nombre de transistors qu’il intègre. Mais cette densité brute ne constitue pas en soi une condition suffisante. Il a fallu structurer l’ensemble de façon optimale. Le résultat, c’est 15 unités SMX dans chaque processeur GK110, avec pour chacune de ces unités 192 cœurs simple précision, 64 cœurs double précision, 32 processeurs fonctionnels spécifiques (SFU – Special Functions Units) pour les opérations complexes et enfin 32 processeurs LD/ST (Load/Store) dédiés à la gestion des piles. Par rapport à Fermi, ces chiffres sont grosso modo en augmentation d’un facteur 4 à 8.
Sus au cycle d’horloge !
Pour accompagner ces nouveautés, NVIDIA a également dû optimiser un certain nombre d’aspects périphériques. Ainsi, pour assurer une répartition et un traitement optimaux des threads au sein de chaque unité SMX, ces dernières intègrent un pool de quatre schedulers nommé Quad Warp – chaque Warp constituant un ensemble de 32 threads parallélisées. Couplés à huit répartiteurs d’instructions, les schedulers sont capables de traiter jusqu’à quatre Warp comptant chacun deux instructions indépendantes par cycle d’horloge.
Cette organisation favorise en premier lieu les opérations déjà fortement optimisées comme l’instruction FMA (Fused Multiply Add), qui exécute en un seul cycle le calcul du produit de deux nombres en double précision, l’addition d’un troisième et l’application d’un arrondi déterminé. Particulièrement efficace, cette opération se retrouve beaucoup en calculs matriciel, polynomial, scalaire et vectoriel, d’où son importante en environnement HPC. Signalons à ce propos qu’Intel intègrera cette instruction dans le jeu d’instructions SIMD de ses deux futures microarchitecture Haswell (courant 2013) et Broadwell (en 2014). Chez AMD, les architectures PileDriver (2011) et Bulldozer (2012) l’intègrent déjà.
Nouvelles instructions, nouvelle mémoire cache
Au niveau mémoire cache, NVIDIA a également revu l’organisation des hiérarchies avec au bout du compte un doublement de la bande passante. Le cache L1 de 64 Ko peut être partitionné par voie logicielle entre données (16, 32 ou 48 Ko) et instructions (48, 32 ou 16 Ko). Il est complété par 48 Ko de cache distincts réservés aux données, en lecture seule. Celui-ci existait déjà dans Fermi mais n’était pas directement accessible. Outre l’accélération des accès, l’intérêt de cet espace est de dissocier le cache L1 des opérations portant sur les registres. Stockage temporaire des résultats et transfert des données n’empiètent ainsi plus l’un sur l’autre. Un cache L2 partagé de 1536 Ko complète l’ensemble, servant d’espace commun aux échanges entre unités SMX. Cadencé à environ deux fois celui de Fermi, il s’avère selon les premiers tests déterminant pour le traitement des données dont les adresses ne sont pas connues à l’avance, comme c’est typiquement le cas avec les solveurs physiques, le ray tracing ou encore les multiplications matricielles.
Dans le même ordre d’idée, le jeu d’instructions a été revisité dans un souci d’efficacité. Comme on vient de le voir, des méta-instructions comme FMA bénéficient maintenant d’un traitement en un cycle d’horloge. Les échanges entre threads ont également été facilités, grâce notamment à une nouvelle instruction Shuffle. Au lieu de mobiliser des registres pour passer des données d’une thread à une autre, Shuffle réalise cette opération en une seule fois, ce qui évite les allers-retours avec la mémoire centrale. Plus intéressant, des paramètres peuvent être passés pour assurer la transformation des données concernées : ces données peuvent ainsi être indexées (bloc de x données à partir du y-ième), reportées (shuffle up / down) ou échangées (XOR). A priori, le gain immédiat apporté par ces traitements dynamiques se situe aux environs de 6 %.
Les ressources exposées aux threads ont également été revues à la hausse, chacune accédant désormais à 255 registres (contre 64 pour Fermi). Les développements antérieurs à Kepler, souvent limités par ce facteur, bénéficient là aussi d’un potentiel d’accroissement de performance important. Par exemple, dans certains contextes applicatifs s’appuyant sur QUDA (la bibliothèque chromodynamique quantique de Lattice), le taux de registres mobilisés pour les échanges est en chute libre, d’où des gains en rapidité pouvant atteindre un facteur 5.
Les interconnexions aussi
Terminons notre revue de détails avec GPUDirect, nouvelle technologie d’interconnexion dont la philosophie emprunte autant à l’infiniband d’Intel, orientée réseau, qu’à l’HyperTransport qu’utilise AMD pour les échanges inter-processeurs. Evolution indispensable compte tenu du niveau de performance interne à l’accélérateur, GPUDirect offre une voie d’échange rapide qui ne mobilise ni le CPU, ni la mémoire globale. La particularité de GPUDirect est d’être également opérationnel en réseau, ce qui rend possible le transfert direct de données entre un accélérateur local et un autre accélérateur distant. Logiquement, les bénéfices sont multiples : le débit entre mémoire et GPU(s) reste constant, les transactions entre CPU(s) et GPU(s) réduites et, de ce fait, la disponibilité du système hôte améliorée. Mais ce n’est pas tout. La fonction RDMA (Remote Direct Memory Access) dote également les dispositifs périphériques externes – stockage SSD, interfaces réseau fibre et Infiniband… – d’accès privilégiés aussi rapides que simultanés, notamment vers plusieurs GPU au sein d’un même nœud ou d’une même armoire physique. Cet effort de parallélisation s’étend donc au-delà de l’accélérateur lui-même, un progrès que ne manqueront pas d’apprécier ceux qui savent où se situent les plus retors des goulets d’étranglement.
En conclusion, Kepler s’inscrit dans une sorte de rupture par rapport aux générations qui la précèdent. Pour résumer, disons qu’elle n’a pas besoin d’aller plus vite pour être plus rapide. La fréquence de référence n’est ainsi plus celle du shader mais celle du GPU. Preuve d’un équilibre interne réussi, GK110 révèle à TDP constant (225W, ou 235W sur K20x) une efficacité énergétique trois fois supérieure à celle de son prédécesseur, tout en offrant des performances doublées. Pour des raisons de process de fabrication, il sera sans doute rare de trouver des cartes Kepler dont 100 % des cœurs seront réellement opérationnels. Mais même avec quelques nœuds défectueux, la promesse sera très largement tenue.
Un vaste catalogue d’applications compatibles
A l’heure où nous publions, la majorité des applications et bibliothèques compatibles Tesla supportent Kepler dans ses trois implémentations (K10, K20, K20x). L’arrivée de la nouvelle architecture a donc été préparée bien en amont par les équipes de NVIDIA. Téléchargeable au format PDF sur le site du fondeur, le catalogue complet compte deux grosses centaines de références dans tous les domaines, de l’analyse numérique de base à la chimie moléculaire en passant par la CAO, l’animation ou la finance. Il n’y a donc pas de risque, a priori, à adopter Kepler tout de suite.
Et si vous aviez encore un doute concernant l’un de vos composants logiciels, la procédure de vérification est (relativement) simple, bien qu’elle dépende de la version du toolkit CUDA utilisée. L’idée est de valider que vos applications peuvent exposer des versions PTX de chaque kernel – versions dédiées au support automatique de Kepler et de ses prochaines mises à jour. Pour cela, il convient de télécharger le dernier pilote CUDA, de spécifier les bonnes variables d’environnement et de lancer une recompilation. Plus de détails sur http://docs.nvidia.com/cuda/kepler-compatibility-guide/index.html.
Testez Kepler chez vous !
Kepler vous tente mais vous hésitez, pour des raisons techniques ou de retour sur investissement ? C’est à vous qu’a pensé NVIDIA avec son programme TestDrive, une façon simple et efficace de démontrer la réalité de son discours sur le papier.
Si vous disposez d’un applicatif accéléré en GPU, un code source compatible Fermi par exemple, la marque vous propose de le tester sur un cluster K20 distant. Il suffit pour cela de remplir un formulaire en ligne, de suivre les instructions de téléchargement (upload) qui vous seront envoyés, puis d’exécuter le code.
Selon la configuration de vos sources, certaines adaptations seront peut-être nécessaires. Pour l’heure, le banc de test est déjà préchargé avec les bibliothèques CUDA, ArrayFire, AMBER, NAMD, GROMACS, LAMMPS, Quantum Expresso et TeraChem.
More around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}