
Quelles évolutions à terme ?
Constatant que trop d’énergie était dissipée sous forme de chaleur, les constructeurs ont arrêté la course au GigaHertz au tournant du siècle dernier. La bataille se joue désormais autour des processeurs multicœurs et des accélérateurs, notamment GPU. Mais pour Marc Baboulin, (Université Paris-Sud, INRIA), ces progrès engendrent une augmentation de l’hétérogénéité des architectures HPC, ce qui rend les calculateurs plus difficiles à utiliser. C’est dans ce contexte que s’inscrit MAGMA, bibliothèque numérique qui vise à conserver l’interface habituelle de Lapack tout en fournissant des algorithmes efficaces sur les nouvelles architectures. MAGMA consiste à placer la matrice sur le GPU pour réduire le goulot d’étranglement des communications GPU/CPU. Il s’agit d’un parallélisme de niveau BLAS qui remplace les appels aux BLAS par des appels à CUBLAS tout en gardant une conception Lapack. Cette technique permet de garder sur le CPU les tâches qui ne tirent pas avantage du GPU, donc d’utiliser l’un et l’autre en fonction de leur meilleur potentiel respectif. L’asynchronisme CPU-GPU est alors une nécessité.
Marc Baboulin n’est pas le seul à travailler sur la réduction des communications. Laura Grigori (INRIA) et son équipe en ont également fait une spécialité. Leur approche se fonde sur une nouvelle classe d’algorithmes d’algèbre linéaire issue de progrès théoriques récents dans le domaine. Ces nouveaux algorithmes Communication Avoiding permettent de minimiser le volume des communications (pour la bande passante) et le nombre de messages (pour la latence) mais ils nécessitent souvent d’effectuer des calculs supplémentaires, calculs toutefois largement compensés par les gains de temps. Laura Grigori précise que leurs modèles ne prennent pas (encore) en compte la distance entre les processeurs, élément qui peut impacter la durée des communications, mais qui augmenterait plus encore la complexité de l’optimisation.
Les volumes de données à manipuler et à calculer en contexte HPC posent enfin de véritables défis en matière d’estimation et de contrôle des erreurs d’arrondi. C’est ce à quoi travaillent Fabienne Jézéquel et son équipe (LIP6-UPMC), autour de la bibliothèque CADNA. Fondée sur la méthode CESTAC, CADNA exécute le même calcul trois fois avec différentes propagations d’erreurs d’arrondi : les chiffres qui diffèrent à l’issu des opérations sont considérés comme non significatifs. LIP6 travaille d’une part à gérer en parallèle ces trois exécutions sur les processeurs multicœurs, et d’autre part à permettre la validation numérique de codes parallèles utilisant MPI, CUDA ou encore OpenMP.
Le développement de bibliothèques en pratique
Le travail que représente le développement d’une bibliothèque logicielle, notamment pour le calcul, présente un certain nombre de spécificités. La dimension haute performance du HPC nécessite d’abord que l’outil en lui-même ne génère pas de pertes – ce qui ne pas de soi. Par ailleurs, l’intérêt général est de construire des bibliothèques sémantiquement les plus homogènes possibles, qui elles-mêmes s’appuient sur d’autres bibliothèques de façon à ce que les progrès se propagent naturellement. En termes de reconnaissance par les pairs – question importante compte tenu de l’investissement de temps – le développement d’un outil logiciel reste un excellent moyen de se faire connaître. FreeFem, par exemple, a au départ été développé pour des besoins de recherche internes. Aujourd’hui, il est utilisé par la communauté. Au final, la reconnaissance passe nécessairement par les publications, notamment pour apporter la preuve mathématique de faisabilité du code fonctionnel.
Cela étant, le fait que le code source ne soit généralement pas joint aux publications qui décrivent les résultats et les performances pose problème dans la mesure où il est impossible de refaire l’expérience et encore moins de rattraper les vingt années de développement pour les vérifier ! Le principe de réfutabilité de Popper est de facto violé. Il est donc nécessaire de mettre en place des démarches dans ce sens, avec des licences certes restrictives, mais qui respectent la démarche scientifique.
En ce qui concerne la durabilité d’un projet, Patrick Moreau (INRIA) propose le concept d’Open Source Readiness Levels (OSRL) – sorte de ligne de vie d’un logiciel. Il distingue 4 phases :
– à OSRL 1, seuls les collègues du créateur utilisent le logiciel ;
– à OSRL 2, une communauté d’utilisateurs externes se forme ;
– à OSRL 3, phase optionnelle, les mêmes utilisateurs qu’à ORSL 2 ont la possibilité de contribuer au logiciel ;
– à OSRL 4, les industriels se joignent au cortège, avec leurs exigences, notamment en termes de corrections de bogues !
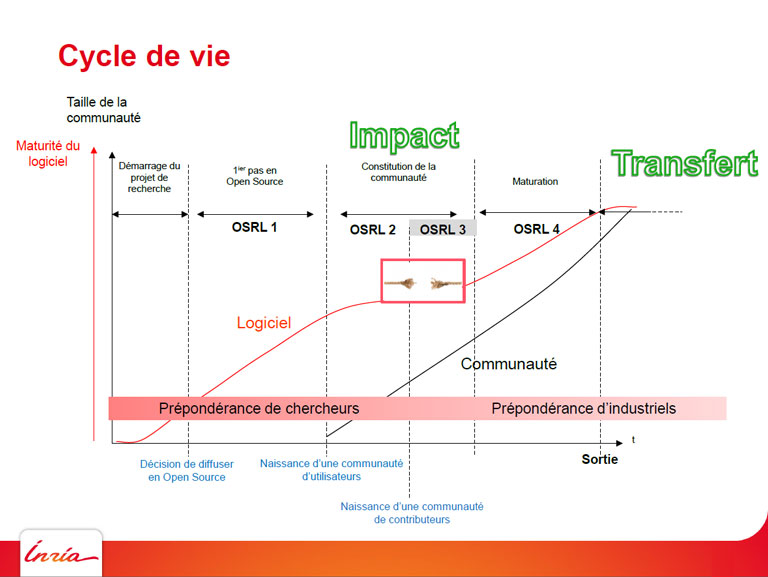
Le concept d’Open Source Readiness Levels (OSRL) formalisé par Patrick Moreau (INRIA) permet d’appréhender puis d’anticiper les grandes étapes du cycle de vie d’une bibliothèque logicielle.
La phase OSRL 4 est censée aboutir au transfert technologique, qui pour être géré correctement conduit à l’idée de création d’un consortium. Patrick Moreau conseille de faire simple, via une association type Loi de 1901 et un simple contrat d’adhésion. Il préconise également de protéger les marques et logos car ces éléments contribuent à la valeur du consortium.
La délicate question des licences
Les fondements du mouvement du logiciel libre sont les mêmes que ceux qui sont à la base du développement scientifique, à savoir la mise en commun des idées et découvertes dans le but de faire progresser la recherche et le savoir collectif. Le terme “logiciel libre” (en anglais free software) désigne donc tout logiciel garantissant à l’utilisateur les quatre libertés fondamentales suivantes :
– pouvoir exécuter (utiliser) le programme, pour n’importe quel usage ;
– pouvoir étudier le fonctionnement du programme (ce qui nécessite l’accès à son code source) et l’adapter à ses propres besoins ;
– pouvoir en redistribuer des copies ;
– pouvoir améliorer le programme (ce qui nécessite aussi l’accès au code source) et diffuser ces améliorations pour en faire profiter la communauté.
Il ne faut donc pas confondre logiciel libre avec logiciel gratuit (freeware) ni avec le concept de logiciel Open source. Le terme “Open source” désigne tout logiciel dont le code source est accessible à l’utilisateur, mais cela n’en fait pas pour autant un logiciel “libre”. Si tous les logiciels libres sont par définition Open source, tous les logiciels Open source ne sont pas forcément libres, c’est-à-dire qu’ils ne garantissent pas nécessairement l’ensemble des quatre libertés citées précédemment. Pour lever toute ambiguïté, les anglophones utilisent parfois le terme “free/libre open-source software” (FLOSS) pour désigner les logiciels à proprement parler libres. Dans tous les cas, comme le souligne Patrick Moreau, il est recommandé de se déterminer sur telle ou telle licence pour son code Open Source dès qu’on en sait assez sur la nature et la portée du projet.
More around this topic...








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















