
Simplification
As important of a transformation as any other in the journey to the modern data center, the simplification of data center systems and processes has the potential to revolutionize the way an IT organization operates and in the end, how it spends money. The simplification process needs to be a broad and sweeping one, yet inspected at the most granular level possible. Leave no stone unturned in the quest for removing complexity.
Complexity may, in fact, be the single costliest attribute of a data center. Think about the fallout from complexity in the data center: troubleshooting is a total disaster because the system has to be reverse engineered before troubleshooting can even begin; operating expenses increase as more staff is required to maintain the complex systems; new systems take ages to implement because of the rigidity of the environment. It’s plain to see that attention paid to the process of simplification in the data center can return immediate benefits.
A potential angle for approaching simplification in the data center that is applicable to many organizations is to look at the server and storage architecture. Is the management of these systems optimal? Are the systems scalable, agile, and efficient? In many cases, the answer to these questions is no. Because servers and storage are so foundational to the data center, beginning the simplification process with these systems can be a great starting point. While certainly not the only option, hyperconvergence is a great way for many organizations to achieve their goals for scalability, agility, and efficiency.
Eliminate Monolithic Storage Systems
It would be fair to speculate that migrating between storage platforms is on almost every IT administrator’s “Top 5 Things I Hate to Do” list. Maintaining storage systems is one of the most complex chores that every IT organization has to deal with. The status quo in the traditional data center for many years has been the monolithic storage array.
Unfortunately, everything about monolithic storage systems is painful, from the upgrades to the scaling challenges to the scope of failure domains.
But there’s good news!
In the modern data center, there is a better way to solve the storage problem. The solution is hyperconvergence. While hyperconverged infrastructure (HCI) is not a panacea, it’s quite a good fit for solving many of the problems exhibited by traditional data center architectures. Chapter 8 will discuss hyperconvergence in great depth, but for the purposes of this section, just understand that hyperconvergence is the “pooling of direct attached storage, flash and potentially local DRAM to create a distributed storage system.”
Rather than many servers pointing at a single storage target, the storage is spread throughout the servers. Software defined storage (SDS) tools allow that direct attached storage to be protected and managed as if it were one big array.
What does it look like to eliminate monolithic storage? The deployment of hyperconvergence for the sake of simplifying the data center overall is, not surprisingly, quite simple. Most manufacturers that offer a hyperconverged platform go out of their way to make the IT administrator’s experience simple. That makes removing the complex monolithic storage array even more attractive. By implementing HCI for a small subset of workloads, data can begin to be moved off the primary storage arrays and into the hyperconverged storage solution. The simplest way to approach this is to leverage SDS to abstract the current storage; this makes swapping the underlying storage is the next phase transparent to the workload.
Alternatively, it seems that finding a certain project that’s a good fit and deploying a hyperconverged system (rather than upgrading or scaling an existing legacy system) is a successful way for many IT organizations to begin the transformation. This strategy of finding a specific, well-fitting project and using it as a way to open the door for hyperconvergence can be referred to as opportunistic hyperconvergence. In other words, rather than a rip-and-replace transformation of the data center, you would do a new implementation or make the move to hyperconvergence as new systems are built and old systems that aren’t supported any more need to be replaced.
Implement Opportunistic Hyperconvergence
Opportunistic hyperconvergence comes in a few different flavors. The first is the one previously discussed — leveraging hyperconverged infrastructure for a specific project to prove its potential. A very common example of this is VDI. Because the nature of VDI workloads is so different from that of server workloads, it is preferred that they run in segregated infrastructures so that they don’t cause each other performance problems.
When an organization is looking to deploy a new VDI platform or do a refresh from a previous implementation, hyperconvergence can be a great fit because the workload is to be segregated anyway. Deploying a different infrastructure model for it doesn’t cause problems with the design for the rest of the data center. Once the business sees value from the VDI project, then it’s much easier to expand into other areas.
Keep in mind that VDI is only an example. Any project where the intention is already to deploy separate infrastructure is a perfect candidate for opportunistic hyperconvergence.
Another way you could practice opportunistic hyperconvergence is to place hyperconverged systems in new remote offices or at acquisitions. Since this infrastructure is outside of the main data center, it gives you the opportunity to evaluate hyperconvergence on a smaller scale. The potential challenge to this scenario is that some of the best benefits of hyperconvergence come with greater scale.
However, if the business is hesitant to try this new direction and a new remote office is being built, why not use that limited-risk opportunity to give hyperconvergence a shot? This outside-in approach is surprisingly easy to grow as internal support for the technology increases.
Because of the way most HCI platforms are designed, adding systems
in the main data center down the road and connecting them up with the nodes out in the remote office is a trivial process.
Management
It makes little sense to transform the details of the data center for the better if the big picture remains blurry. What will eventually make the SDDC shine in the eyes of the business is having a robust yet nimble grip on the entire data center by using a set of management tools that monitor and control the big picture. Insight is sought after more than gold in organizations today, but providing it is tricky. Taking appropriate action based on that insight is trickier still. The final component to transforming an old, tired data center into a modern data center is to bring new life to the management systems.
It’s critical when managing a data center to be able to get a top-to- bottom view of the entire infrastructure. All aspects of operating a data center are made more difficult by not having complete visibility. Being able to manage all the way through the infrastructure stack makes troubleshooting, maintenance, and design more fluid. It’s also important to begin to shift toward a hands-off approach where systems function without the need for IT’s intervention. This means investing in automation, workflow orchestration, and self-service provisioning. The modern data center accomplishes far more than the data center of the past but with less manual work required of the IT administrators.
This frees up staff resources to keep innovating and revitalizing the data center.
Full Stack Management
Because visibility through the stack is so important to the overall management picture, it’s vital that your hyperconvergence vendor of choice for transforming the data center provides the tools needed to get this visibility. The more parts of the stack that are under their control, the more insight can be gained. This is the challenge with traditional data centers. The storage system is completely unaware of the network system which is completely unaware of the compute system. Making decisions without all the relevant information is nearly impossible.
The only way to make truly beneficial decisions regarding workload optimization or failure protection is to have all the details.
Today, there seems to be two methods of full stack management, neither being more preferable than the other:
- The vendor providing the infrastructure components also provides the full stack management insights. This is something that can be delivered by hyperconvergence vendors due to the fact that all the components making up the infrastructure are a part of the HCI platform. However, this method risks some vendor lock in.
- A third-party tool aggregates data from all the components involved to create the big picture. In some cases, this may be the only option, and in those situations it’s certainly better to have a third party managing the full stack than no one at all. A potential disadvantage to the third-party tool is that the insight may not be quite as deep (though this isn’t always the case).
Key Features
The full stack management system (with all of its awareness of the subsystems) should provide, or at the very least enable, the implementation of three very important data center characteristics:
- Automation
- Orchestration
- Self-Provisioning
If it can accomplish these three things, the modern data center will have been realized. It would be preferable that the management system itself provides these functions, but if it doesn’t, it’s acceptable that it simply exposes APIs to allow other, better suited systems to interface with it in order to perform those roles in the environment.
Automation
Streamlined automation is the hallmark of the modern data center. There are two key reasons why automation is critical:
- Accuracy. Humans are notoriously inconsistent and fallible, while the opposite is true of computers. As developers say, sometimes it’s maddening that computers don’t make mistakes, because that means that if the code isn’t working, it’s probably your fault! Automation combats our ineptitude by performing repetitive tasks correctly every single time.
- Speed. Because a computer can execute code much faster than a human can interface with a computer, automation is also leveraged to complete tasks much faster than they could be completed by hand. Powerful automation is only possible (at least, without expending great amounts of effort) with a full stack management system that can monitor and control the big picture.
Orchestration
The second function the full stack management platform should provide or allow is orchestration.
Infrastructure automation (as mentioned previously) is a step in the right direction; however, the real value to the business comes from fully automating a business process. This is called orchestration.
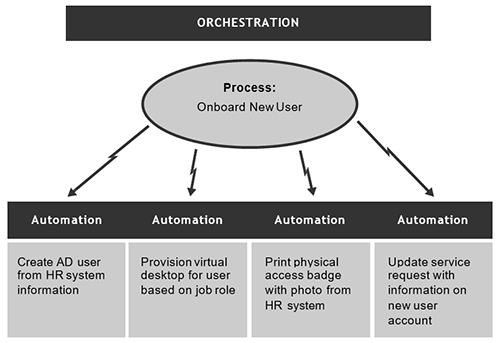
An example of a business process would be on-boarding a new user with regard to all of the systems that IT manages. Creating an Active Directory account can be automated. Orchestration of this is the workflow which kicks off all of the different automation tasks for creating the Active Directory account, creating a mailbox, adding the user to security groups and distribution lists based on department, provisioning a phone extension, tying an instant messaging/presence identity to an account and phone, and the list could go on. It’s easily conceivable that this process could take an hour to a couple of hours for an IT administrator to complete. This leaves the new user waiting and unproductive until the process is complete. In a large organization with thousands of employees, this single business process alone could add up to a few full-time employees’ worth of work each year.
However, orchestrating the on-boarding process so that it can be completed without human input would create dramatic savings, as well as allow the new user to get started almost immediately. Figure 6-3 illustrates the difference between automation (a smaller task) and orchestration (multiple automated steps carrying out a business process).
Orchestration at the infrastructure layer, enabled by the full stack management system, allows this same level of reduction in effort. The creation and destruction of Test/Dev environments as discussed at the beginning of this chapter could be easily orchestrated so that the entire process is completed without the need for human intervention. However, this can only be done with the right management tools.
Self-Service
The final thing a full stack management system should provide or enable is a self-service provisioning model.
This may be an Infrastructure as a Service (IaaS) platform, or it may be something not quite so complex. However, allowing properly entitled administrators or users to request provisioning of their own resources and then have the system handle it and charge it back to them is the only way the modern data center will be able to keep up with demand. Self-service provisioning of resources will be a direct follow-on of the management system’s ability to orchestrate, as fulfilling the request will likely involve a number of different processes and systems.
Conclusion
In this chapter, you learned about how to identify and address the low-hanging fruit in your organization and transform the data center.
Some of the potential starting points for this transformation that were discussed are: Test/Dev environments, ROBO environments, server virtualization, big data, disaster recovery, and VDI. The following are a few key terms and concepts to take away from this chapter.
Transforming a data center is only valuable for one reason, and it’s the same reason why the data center exists in the first place.
With that in mind, the first step to transformation is to take a hard look at which transformation choices will affect the bottom line.
- Address low-hanging fruit first. It’s wise to begin the data center transformation with a technology that is most familiar to the team, has specific value to the business, and is extensible into other areas of the data center.
- To successfully complete the SDDC portion of the transformation to the modern data center, the SDDC must be the new operational lens moving forward.
- When adopting an SDDC approach to transforming your data center, you can’t expect to change everything at once. The SDDC transformation is often a gradual process.
- Complexity may, in fact, be the single costliest attribute of a datacenter. Thus,is key.
Leverage new projects to implement opportunistic hyperconvergence, where the architectural change meets the least friction. - A successful data center transformation will include a shift in the paradigm of data center management to focus on: automation, orchestration, and self-service.
One of the major players in the data center transformation is software defined storage (SDS). The next chapter will take an in-depth look at what SDS is and how it works.
About the authors
Scott D. Lowe, James Green and David M. Davis are partners, ActualTech Media
Published with permission of Atlantis Computing
More around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}