
C’est une autre façon de concevoir le parallélisme : rester dans un contexte x86 mais en multiplier les ressources (et en optimiser la logique) pour permettre tous les scénarios de dimensionnement. Techniquement, le pari est réussi.
Quand les ingénieurs d’Intel présentent Xeon Phi, ils le décrivent d’abord comme l’intégration logique de plusieurs cœurs CPU au sein d’un unique composant fonctionnel. De là découle son principal argument marketing : une approche de la parallélisation massive voulue comme ultra-polyvalente.
L’idée générale, pour le fondeur historique, c’est d’offrir à ses clients Xeon une voie d’évolution naturelle, permettant de capitaliser sur les efforts applicatifs déjà entrepris – sans changer de langage, de paradigme, de méthodologie.
Et en effet, concrètement, Phi est lui-même un cluster, animé par un Linux dédié, supportant pleinement l’organisation mémoire x86, l’arithmétique à virgule flottante IEEE 754 et les principaux langages de programmation scientifique que sont C, C++ et Fortran. A l’usage, la présence de Linux en interne permet l’implémentation d’une pile TCP/IP sur le bus PCI Express. On peut donc adresser le coprocesseur en tant que nœud réseau partout dans le monde, soit pour l’exécution en parallèle d’une tâche bien précise, soit pour le déport, à partir du ou des CPU adjacent(s), de tout ou partie d’une application hétérogène.
Un cluster dans votre cluster
En termes de dimensionnement, un seul CPU est capable de supporter de multiples accélérateurs Phi (jusqu’à 8). Une fois ceux-ci installés, ils communiquent de façon autonome, sans intervention du système hôte : en local via les interconnexions P2P du bus PCIe, à distance via des interfaces réseau de type Ethernet ou, de préférence, InfiniBand. La mise en abîme du concept de cluster est donc totale. Un gros calculateur embarquera de multiples Xeon Phi, chacun d’eux embarquant à son tour de multiples CPU x86. Voilà pour le décor extérieur.
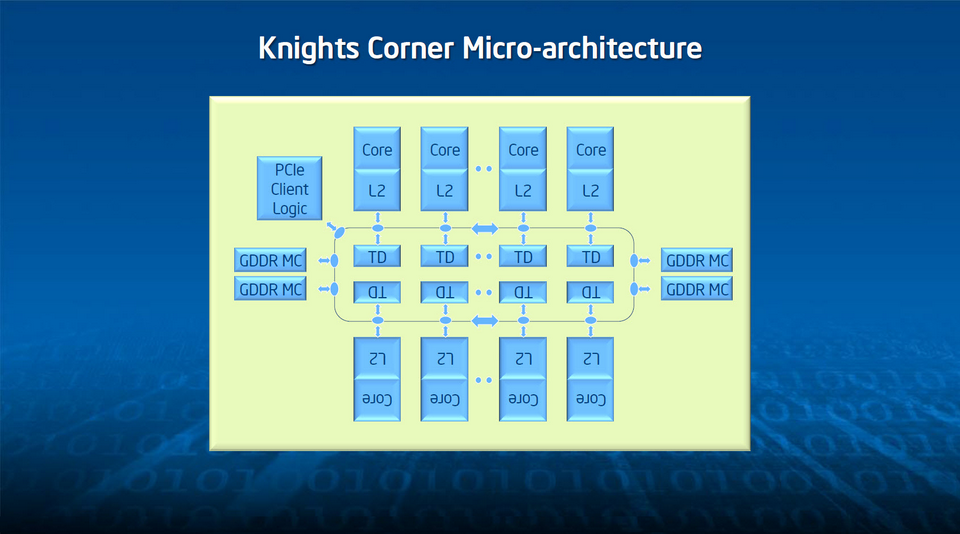
A l’intérieur, Phi se présente donc comme un agrégat de 60 cœurs discrets, fonctionnellement indépendants, réunis par un anneau de communication bidirectionnel, reliés à 8 contrôleurs mémoire double canal GDDR5 (à 5,5 GT/s) puis, enfin, à une interface bus commune. La description est longue, mais le concept globalement assez simple. Sauf qu’il a fallu adapter l’ensemble à des contraintes de collaboration fortes. Par exemple, chacun des cœurs offrant quatre threads matérielles, un mécanisme était indispensable pour permettre un adressage à plat le plus performant possible. Après avoir suivi plusieurs pistes, Intel a choisi un système d’index distribué dont l’implémentation est telle que toute adresse physique est mappée de façon unique via une fonction de hashing réversible. Cette solution, élégante dans son principe, offre un second avantage : elle induit des fonctions de gestion de cohérence globales que les seuls cœurs ne peuvent assurer localement.
Des instructions SIMD élargies
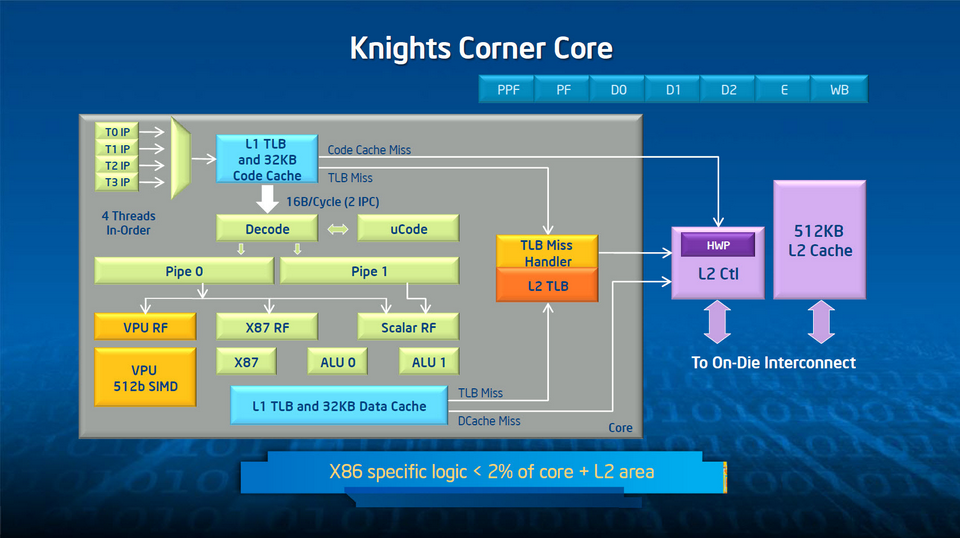
Descendons plus avant à l’intérieur d’un cœur pour y trouver un VPU (Vector Processing Unit) de 512 bits, un anneau d’interfaçage et un cache L2 privé. On remarque au passage que le support de l’architecture x86 proprement dit mobilise moins de 2 % de l’électronique – un coût raisonnable pour la compatibilité. C’est bien sûr le VPU qui fait tout l’intérêt d’un cœur Phi. Car sa largeur SIMD se révèle particulièrement efficace en charges de travail parallèles. Une seule opération suffit pour encoder ce qui, traditionnellement, nécessite plusieurs dépenses d’énergie : accès, décodage, exécution d’instructions multiples. Il a fallu pour cela lui ajouter un registre de masquage, de façon à permettre l’exécution prédictive, et câbler les fonctions d’indexation pour les vecteurs de tailles différentes.
Point à noter, le VPU des cœurs Phi dispose en plus d’une Extended Math Unit (EMU) dédiée au traitement des fonctions transcendantales. Celles-ci sont donc exécutées de façon vectorielle et bénéficient de toute la bande passante interne.
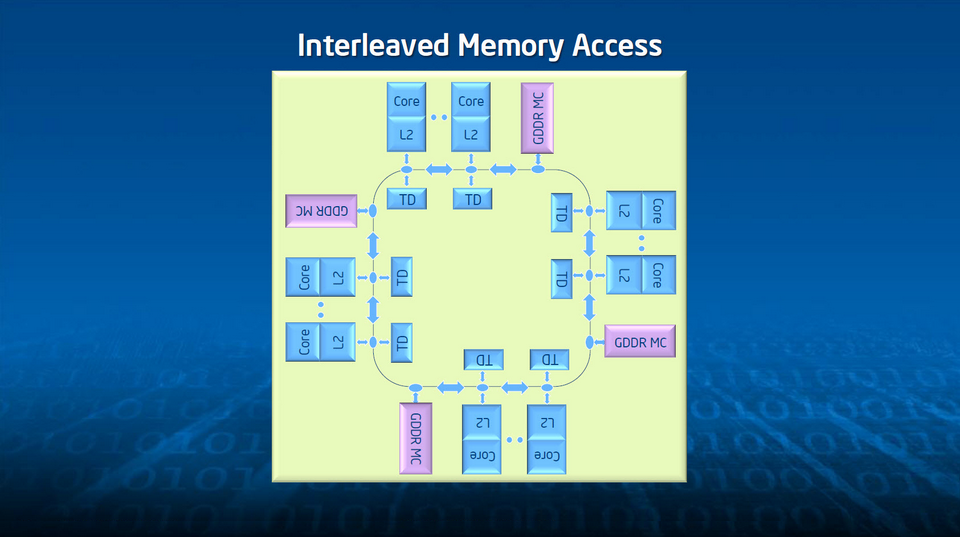
Contrairement à un accélérateur Kepler, l’architecture interne de Phi n’est fondamentalement spécialisée. Elle ne reflète pas les processus logiques de parallélisation propres par exemple à l’environnement CUDA. Pour ce qui touche aux interconnexions, cette généricité se traduit sous la forme d’un anneau bidirectionnel lui-même composé de cinq anneaux distincts pour chaque direction. Le premier, le plus consommateur de ressources, est logiquement l’anneau des données. Pour supporter la charge mémoire d’un fonctionnement à plein régime, Intel l’a dimensionné à 64 bits. Vous l’aurez deviné, les quatre autres, plus étroits, servent à l’adressage et au contrôle de flux. Pour la petite histoire, sur les premiers prototypes Xeon Phi, un seul anneau d’adressage et un seul anneau de contrôle étaient implémentés par direction. Mais lors des montées en charge, à partir d’une trentaine de cœurs mobilisés, les goulets d’étranglement étaient tels que le ingénieurs ont dû les doubler.
Le bénéfice, ici, est que le gros des opérations induites par un cache-miss se déroule sur les petits anneaux, avec par conséquent un niveau de latence contenu et une certaine économie de moyens. Typiquement, les échanges se résument à un seul bloc de données, deux requêtes d’adresses et deux messages de confirmation. Cela ne signifie pas qu’on doive renoncer à une certaine rigueur de programmation, mais on peut quand même y voir un légère tolérance dans certains cas de codage non encore totalement optimisé.
De l’importance des différents caches
Autre point distinctif de Phi par rapport à un accélérateur GPU, l’architecture MIC capitalise beaucoup plus sur l’organisation, la dimension et l’utilisation des caches. Au niveau externe, la carte embarque des contrôleurs périphériques permettant par exemple de paralléliser le chargement et le stockage. Un prefetcher à 16 canaux augmente lui aussi le taux de hits de façon importante. Mais c’est véritablement dans la hiérarchie des caches que réside un des principaux facteurs de performances de Phi (d’où l’importance de bien la connaître pour bien la programmer – voir pour cela notre premier dossier développement Xeon Phi à la fin de ce numéro).
Ainsi, les 60 cœurs disposent chacun de deux caches L1 (32 Ko pour les instructions, 32 Ko pour les données) et d’un cache L2 unifié de 512 Ko. Intel précise qu’ils atteignent, respectivement, 15 et 7 fois la bande passante de la mémoire globale de l’accélérateur, et que leur efficacité énergétique est elle aussi nettement supérieure.
C’est là un point très important pour l’appropriation de Xeon Phi dans une optique à long terme. Quel que soit le processus de portage ou d’optimisation de code, il est fondamental de commencer par la gestion des caches (affinité des données, dimensionnement des vecteurs et tableaux de données) pour assurer à l’applicatif un maximum de scalabilité. La route de l’exascale, rappelons-le, passe par une diminution tous azimuts de la consommation électrique. Sur un déploiement d’envergure, cette “simple” optimisation prend tous son sens.
Priorité à l’efficacité énergétique
C’est d’ailleurs toute la dimension alimentation qu’Intel a soigné sur Xeon Phi. Le discours officiel étant que toutes les tâches ne doivent pas nécessairement passer par lui – qu’en fonction de leur degré de parallélisation, un CPU Xeon peut suffire à les exécuter – il était nécessaire que l’accélérateur puisse passer de façon dynamique de l’éveil à la veille et inversement, sans incidence sur le comportement général du système hôte.
Pour ce faire, l’alimentation est en quelque sorte gérée cœur par cœur – seule voie possible pour assurée une optimisation à la fois automatique et programmable. Il suffit que les quatre threads d’un des 60 cœurs aient terminé de s’exécuter pour que celui-ci voit son horloge déconnectée. Après un intervalle paramétrable, si l’activité ne reprend pas, c’est le cœur lui-même qui est déconnecté.
Cette répartition de l’alimentation étant autonome, elle doit également prendre en compte la possibilité que tous les cœurs soient déconnectés à un instant donné. Lorsque c’est le cas, et qu’après un certain intervalle programmable aucune activité ne reprend, ce sont cette fois les index d’adressages, les interconnexions, les caches L2 et les contrôleurs mémoire qui sont stoppés (au niveau horloge). A cet instant, le driver hôte peut, selon son paramétrage, choisir de placer Phi dans plusieurs niveaux de veille (idle, sleep…). Au maximum, la GDDR est placé en mode self-refresh et la logique PCI Express reste en état d’attente d’un signal de réveil.
Premiers tours de chauffe
Fort de ces spécifications, Phi confirme donc sa complémentarité avec Xeon et, donc, son identité véritable : celle d’un coprocesseur, destiné à prendre le relais du CPU lorsque certaines conditions applicatives sont réunies. L’objectif sera donc d’abord de créer ces conditions puis de les affiner progressivement de façon à ce que l’accélérateur fasse jouer ses ressources au maximum. Pour quel bénéfice ? Il existe bien sûr autant de contextes particuliers que d’applications, de sorte que l’énoncé du gain de puissance escomptable reste toujours un peu factice. Néanmoins, les quelques exemples synthétiques livrés par le fondeur sont intéressants.
Le premier est un cas d’école. Considérez la boucle suivante :
!$OMP PARALLEL do PRIVATE(j,k)
do i = 1, 20
offset = i*128
do j = 1, 5000000
!dir$ vector aligned
do k = 1,128
fa(k+offset) = a * fa(k+offset) + fb(k+offset)
end do
end do
end do
Exécutée en mode sériel sur un système Xeon “de base”, elle livre un résultat en environ 67 secondes. Avec l’ajout des directives de parallélisation (en gras dans le code), on passe à 0,46 secondes sur le même système Xeon de base, à savoir une augmentation des performances de l’ordre de 145X. Si, ensuite, on ajoute un Xeon Phi au système, le gain pécédent est encore multiplié par 2,3, avec une exécution en 0,2 secondes. Globalement, le facteur d’accélération atteint 340.
C.Q.F.D.
Sur des benches plus globaux, les chiffres sont évidemment plus raisonnables. Qu’il s’agisse de SGEMM, DGEMM ou de Linpack, ils se situent en moyenne aux alentours de 2,4X par adjonction d’un Xeon Phi standard à un Xeon E5-2680, avec dans les trois cas un taux d’utilisation de Phi compris entre 75 et 85 %. A signaler, l’utilisation de Phi en contexte d’applications financières simple précision (BlackScholes, Monte-Carlo…), révèle des facteurs de gain pouvant quant à eux atteindre 10X.
Pour Intel, ces résultats sont en ligne avec le cahier des charges confié aux ingénieurs – et surtout avec ceux qu’annonce la concurrence, qui du même coup voit l’approche coprocesseur validée. Mais l’essentiel est qu’ils sont grosso modo corroborés par les premières prises en main réalisées par des clients indépendants. L’honneur est donc sauf, cette première itération de Phi se révélant d’emblée compétitive face aux nouveaux accélérateurs NVIDIA et AMD.
Reste maintenant l’épreuve du terrain, en environnement applicatif réel, dans l’infinité des contraintes techniques propres à chaque projet. Nous y reviendrons très en détails dans nos prochains numéros.
More around this topic...








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}