
D’accord, mais alors quid de la différence de syntaxe ?
GCC supporte aujourd’hui les deux syntaxes OpenACC et OpenMP avec le même code sous-jacent. Si pour quelques raisons que ce soit il devait y avoir fusion, elle serait basée sur la possibilité donnée aux utilisateurs de pouvoir migrer de larges codes sur les accélérateurs et d’y obtenir de bonnes performances. Comme je l’ai dit précédemment, le modèle OpenMP est plus restrictif pour exécuter tout un code OpenMP sur accélérateur. La portabilité d’OpenACC entre accélérateurs est ce qui peut légitimer sa continuation. Si on en arrive un jour à un point où tous les processeurs se ressemblent dans leurs grandes lignes architecturales, alors oui, il y aura motif à ce que les deux modèles fusionnent en un seul.
OpenACC vise à supporter des accélérateurs d’origines différentes mais chacun sait qu’ils ont tous leurs propres spécificités. Comment un modèle de programmation générique qui abstrait les processeurs peut-il assurer des performances élevées, ou tout du moins une efficacité suffisante ?
On ne doit pas attendre d’OpenACC qu’il fournisse des performances aussi bonnes que CUDA. En revanche, un code écrit à l’aide de directives peut être exécuté sur d’autres processeurs alors que CUDA n’est pas disponible sur d’autres architectures que celles de NVIDIA. Nous avons besoin d’un modèle qui approche les performances de CUDA. Il n’a pas à être aussi performant, juste suffisamment performant. Par exemple, des ingénieurs chez Cray ont pu atteindre 89 % de la performance d’un code CUDA avec OpenACC sur Titan. C’est donc pratiquement faisable. Vous passerez sans doute pas mal de temps à y parvenir, mais moins de temps que de programmer en CUDA directement. Et pour être tout à fait honnête, le standard OpenACC étant encore relativement jeune, la maturité des compilateurs peut aussi affecter les performances.
Mais revenons au sens exact de votre question concernant la performance et l’abstraction matérielle. OpenACC exprime trois niveaux de parallélisme au niveau de l’accélérateur. C’est probablement suffisant pour supporter les CPU multicœurs. Les codes s’exécutant sur un système hôte à base AMD, Intel ou ARM sont donc à même de profiter de cet unique modèle OpenACC. Pour les GPU et autres accélérateurs, ces trois niveaux de parallélisme avec vectorisation permettent d’exécuter les codes avec un niveau de performance satisfaisant.
On peut donc d’ores et déjà exécuter du code OpenACC sur des CPU multicœurs avec de bonnes performances ?
Les CPU multicœurs devraient être considérés comme des cibles OpenACC au même titre que les accélérateurs. Aujourd’hui, clairement, la plupart des utilisateurs exécutent du code OpenMP ou MPI sur l’hôte et du code OpenACC sur l’accélérateur. Mais nous espérons bien voir OpenACC utilisé partout dans un avenir raisonnable.
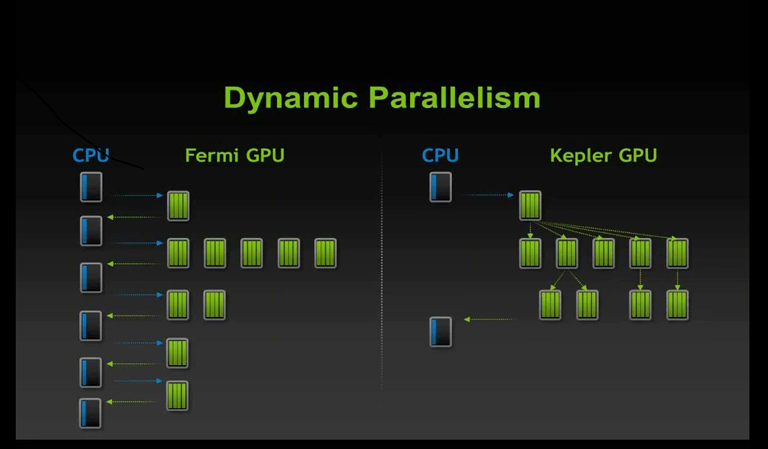
Prenons les “Nested OpenACC Regions” d’OpenACC 2.0, qui sont plus ou moins l’équivalent du “CUDA Dynamic Parallelism” introduit dans CUDA 5.0 sur Kepler. Quel est l’impact de ce type de fonctionnalité spécifique sur des accélérateurs autres que ceux de la famille Tesla ?
Pour bien comprendre le problème, deux éléments sont à prendre en compte. Le premier est la capacité à lancer un noyau depuis un autre noyau. Le second est la possibilité d’exprimer des structures comme des boucles triangulaires où la boucle interne s’exécute sur des plus petites régions que la boucle externe. Cette double fonctionnalité est utile sur les accélérateurs permettant le lancement de noyaux depuis d’autres noyaux. Aujourd’hui, les accélérateurs AMD, Intel et NVIDIA le supportent. Les fonctions que vous mentionnez sont donc aussi importantes pour AMD et Intel que pour NVIDIA.
Pour être tout à fait honnête, je n’ai pas étudié dans le détail comment ces “regions” se comportaient sur le MIC et, pour ce qui concerne AMD, CAPS ou PGI peuvent répondre à cette question de façon exhaustive. Bien entendu, tout dépend de la façon dont est implémenté le parallélisme imbriqué au niveau des compilateurs. Nous faisons attention à ce que l’implémentation entre les compilateurs produise un comportement commun et des résultats cohérents sinon uniformes. Vous le savez, il y a une sorte de course perpétuelle à la performance entre les compilateurs. Ce faisant, chacun cultive ses propres avantages et, par la force des choses, apporte ses propres forces au pot commun. CAPS, par exemple, utilise n’importe quel compilateur sur le système hôte et génère, à partir d’OpenACC, soit du code OpenCL soit du code CUDA. C’est une approche intéressante. Samsung, qui n’est pas membre d’OpenACC, a aussi choisi cette approche consistant à produire du code OpenCL à partir d’OpenACC pour ses processeurs. Ils ont utilisé GCC et ont rendu public le code source. Le support d’OpenACC 1.0 dans GCC FORTRAN est donc déjà réalisé et Samsung collabore maintenant avec les équipes de GCC pour y ajouter le support d’OpenACC 2.0.
OpenACC est supposé portable mais la performance ne l’est clairement pas. En guise d’illustration, une configuration particulière de gangs ou de workers dans un code OpenACC sera performante sur un accélérateur donné mais pourra être totalement inefficace sur un autre. Quel peut être alors le bon compromis entre portabilité et efficacité ?
C’est effectivement une autre bonne question à poser aux éditeurs de compilateurs. Je sais qu’il existe des macros (#define) qui permettent de changer la configuration par défaut du nombre de gangs et de workers pour un accélérateur par rapport à un autre. Mais ce n’est pas au développeur de gérer ces spécificités. Idéalement, on devrait laisser ce soin au compilateur, qui connait a priori la meilleure configuration à utiliser. Quand on essaye d’optimiser par soi-même, on est souvent surpris de voir avec quelle précision les compilateurs savent déterminer par eux-mêmes le bon nombre de gangs et de workers.
A ce propos, j’aimerais également mentionner l’initiative “fat binary” qui consiste à construire un binaire contenant les codes pour plusieurs architectures d’accélérateurs. PGI supporte cela. Vous pouvez donc créer un unique programme qui s’exécutera sur le système hôte avec ou sans GPU, que celui-ci soit d’origine NVIDIA ou AMD. C’est une excellente approche pour la production de logiciels commerciaux.
More around this topic...










© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















{kind=link}
{kind=link}