
Démarrage du second supercalculateur de classe PETAFlop au centre d’informatique scientifique de l’université de Tsukuba
Le challenge
- Élargir les besoins des systems HPC pour soutenir «interdisciplinary Computational Science”, laquelle unit la science et de l’informatique.
- Exploiter la technologie de multiples processeurs many-core
La solution
- Processeurs Intel Xeon E5
- coprocesseur Intel Xeon Phi
- Outil de développement ‘Intel Cluster Studio XE’ vers les développeurs MPI et C ++ / Fortran
Les avantages
- Introduction du supercalculateur ‘COMA (PACS-IX)’ avec une performance de calcul crête de 1.001PFLOPS
- la recherche et le développement porte sur les prochains supercalculateurs de type many-core
Le centre d’informatique scientifique de l’université de Tsukuba, promeut la discipline « Interdisciplinary Computational Science », laquelle réunit la science et de l’informatique, a présenté « COMA (PACS-IX) », un supercalculateur d’une puissance de 1 001 PFLOPS, en fonctionnement dpuis avril 2014. L’unité centrale est composée de deux processeurs Intel Xeon E5, auxquels s’ajoutent 393 noeuds de calcul comportant chacun deux coprocesseurs Intel Xeon Phi pour former un cluster de calcul unique. C’est un véritable motif de fierté qua d’avoir réussi à atteindre la puissance record de 1 001 PFLOPS avec ce supercalculateur animé par des coprocesseurs Intel Xeon Phi.
Au centre d’informatique scientifique de l’univeristé de Tsukuba, en plus de promouvoir l’état de l’art en matière de recherche informatique, « HAPACS », le superordinateur qui est entré en usage en 2012 avec 1 116 PFLOPS qui s’appuie sur des accélérateurs GPU est utilisés vers le développement professionnel de l’informatique haute performance dans l’éducation des élèves et étudiants des cycles supérieurs.
Auto-promotion de la recherche scientifique en utilisant un ordinateur unique au Centre national d’information universitaire
Avec le Centre de Physique qui a été fondée en 1992, l’actuel Centre d’informatique scientifique a été restructuré et étendu en 2004. En 2010, il a été certifié en tant que centre de recherche par le Ministère de l’éducation comme « AISCI » (Advanced Interdisciplinary Computational Science Collaboration Initiative).
Actuellement, dans le cadre du « Programme conjoint d’utilisation multidisciplinaire » qui renforce la collaboration entre l’informatique et la science, il fournit les ressources informatiques pour les instituts de recherche à travers le pays, soutient la tenue d’ateliers interdisciplinaires de calcul pour la science, soutient l’invitation de chercheurs, supporte l’échange des étudiants et des chercheurs et la conduite de la recherche visant le développement de supercalculateurs extra scale.
Le Directeur adjoint et Président des opérations du Centre, M. Taisuke Boku, explique : « Son rôle est non seulement celle d’un centre informatique où des chercheurs scientuifiques peuvent utiliser des supercalculateurs, mais étant une Université nationale unique avec un grand nombre de enseignants et chercheurs de divers domaines informatiques, d’aider au développement d’applications et la recherche scientifique, et de promouvoir le développement de l’ordinateur lui-même, une fonction qui ne figure pas dans les centres informatiques d’autres universités. Ces initiatives sont définies comme « interdisciplinary Computational Science », et constitue une caractéristique majeure du Centre. Ce dernier est un lieu d’exploration en informatique avec un vaste champ d’applications. Cette discipline utilise un réseau à grande vitesse et des supercalculateurs ultraperformants comme principaux outils de recherche par des scientifiques issus de trois domaines. A savoir les chercheurs en sciences qui utilisent l’ordinateur, les data scientists qui font des recherches sur les données et le traitement des médias, et les chercheurs en informatique qui font de la recherche sur le matériel, les logiciels les algorithmes et la programmation.
Avec la construction d’un système commun de recherche au fil des ans, le Centre de recherches a également fait la promotion de la science fondamentale, de la simulation à grande vitesse, de l’analyse de données Big Data et la recherche appliquée en technologies de l’information. Actuellement, en utilisant « HA-PACS » et « COMA » nous visons une percée dans la recherche et le développement des sciences de l’informatique dans les domaines de la physique des particules, l’espace, la physique nucléaire, la matière, la science, la biologie et de l’environnement.
L’évaluation de la performance et l’adoption du coprocesseur Intel Xeon Phi
Ces dernières années, la puissance grandissante des processeurs a contribué à augmenter de manière significative la performance des clusters de PC massivement parallèles. Cependant, la méthode traditionnelle de simplement augmenter le nombre de nœuds par l’ajout de processeurs pour augmenter les performances de l’informatique a des limites en raison de l’espace et la puissance limitée. Au Centre de recherche de Tsukuba, figure un cours sur l’étude de la faible puissance des supercalculateurs à haute performance accélérés par des dispositifs arithmétiques concentrés sur les processeurs many-core (MIC) dans lequel plusieurs cœurs sont intégrés dans une seule puce. Intel a participé à la « Intel MIC Beta Program » initié pour l’évaluation de l’architecture du MIC et la recherche continue sur le réglage et l’évaluation de la performance. Le centre de recherche a décidé d’introduire COMA aussitôt après le lancement du coprocesseur Intel Xeon Phi.
Le coprocesseur Intel Xeon Phi possède 61 cœurs sur une seule puce. L’adjonction de ce coprocesseur à un CPU au travers du bus générique PCI Express permet d’atteindre des performances élevées. Ce coprocesseur fournit d’excellentes performances pour chaque watt. (M. Boku) Un autre avantage du coprocesseur Intel Xeon Phi, qui partage une même architecture que celle du processeur Intel Xeon, est son haut niveau de programmabilité.
M. Boku estime qu’« Il vient un sentiment de sécurité lorsque les applications peuvent être développées sans perdre les programmes existants et sans avoir à se souvenir de nouvelles choses. Tout comme les coprocesseurs classiques, ce coprocesseur peut être utilisé pour écrire des programmes en utilisant FORTRAN ou C ++ et Open MP, de sorte que l’élaboration de programmes pour l’avenir est possible ». En 2013, le centre de recherches de Tsukuba avait conçu le prochain supercalculateur en collaboration avec le Centre des Technologies de l’information de l’Université de Tokyo et a créé JCAHPC (Joint Center for Advanced High Performance computing), une organisation pour la coopération et la gestion. Pour l’exercice 2015, JCAHPC a introduit de très grands supercalculateurs de classe PETAFLOP sur le campus de Kashiwa du Centre des Technologies de l’information de l’Université de Tokyo. COMA, qui est pourvue d’un grand nombre de processeurs many-core, joue également un rôle en tant que système expérimental pour réaliser le développement de la recherche visant à créer le supercalculateur de la prochaine génération.
Assurer la performance avec un approche MIC basée sur deux unités CPUMIC et CPU
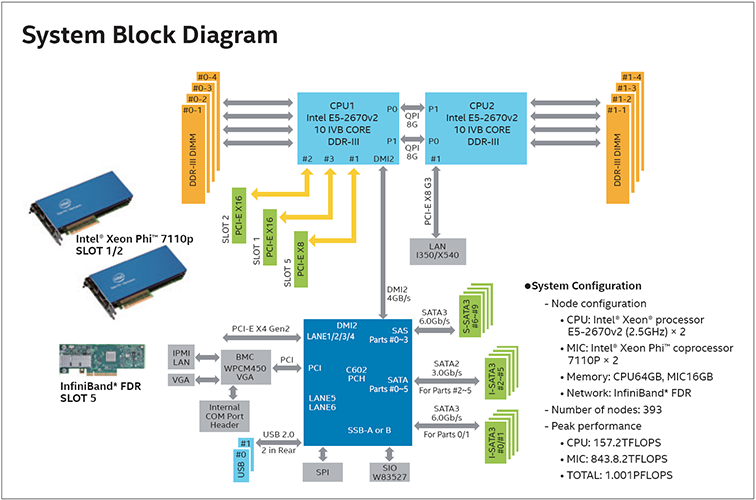
COMA, introduit par le Centre de recherches de Tsukuba une abréviation de «Cluster Of Many-core Architecture » Le terme est également dérivé du nom anglais Coma Berenice, ou « Chevelure de Bérénice », l’un des amas de galaxies typiques. Ce supercalculateur de gamme PACS de neuvième génération a donc hérité du suffixe en chiffres romains pour donner le nom de code PACS-IX. COMA est un système parallèle équipé de 393 nœuds de calcul où un nœud de calcul possède deux processeurs Intel Xeon E5-2670v2 (à 2,50GHz) ayant 10 cœurs par processeur et deux coprocesseurs Intel Xeon Phi 7110P avec 61 cœurs de processeur. La puissance de calcul d’un seul nœud est de 0,4TFLOPS pour le CPU, 2,147TFLOPS pour le MIC et 2,547TFLOPS ensemble. Les performances de calcul crête de l’ensemble du système est de 157,2TFLOPS par CPU, de 843,8TFLOPS par MIC et de 1 001 PFLOPS ensemble. En outre, tous les noeuds de calcul sont reliés à travers un réseau à grande vitesse (InfiniBand FDR), avec des performances dix fois supérieures à celles de Ethernet tout en autorisant l’exécution exécuter de traitements parallèles entre chaque nœud de calcul.
Le serveur de fichiers Lustre d’une capacité totale de 1,5 Peta-octets en RAID-6 est utilisé pour le stockage et par l’InfiniBand FDR, et permet d’accéder librement à tous les nœuds de calcul.
7110P et d’une carte réseau InfiniBand FDR, à côté d’un processeur Intel Xeon E5-2670v2, assurant la communication à grande vitesse entre le coprocesseur et la carte réseau. L’avantage est qu’un unique processeur Intel Xeon E5-2670v2 permet de soutenir la performance élevée requise ». (M. Boku)
Trois modes de fonctionnement pour soutenir le traitement parallèle des nœuds de calcul
Les calculs de COMA peuvent s’opérer selon trois façons différentes. A savoir CPU seul, MIC seul ou une combinaison de CPU et de MIC.
• CPU seul
Pour rester compatible avec les développements orientés multi-core (+ MPI) réalisés pour le supercalculateur “2K-Tsukuba” de la génération précédente, dont l’exploitation s’est arrêtée en Février 2014, les programmes exploitent 16 cœurs sur les 20 que compte le processeur Intel Xeon E5- 2670v2.
• MIC seul
Il est également possible d’utiliser quatre cœurs du processeur Intel Xeon E5-2670v2 et deux noyaux du coprocesseur Intel Xeon Phi 7110P (61 de base × 2). En profitant de la fonctionnalité de déchargement (offload) prévu par le compilateur Intel pour le déport d’exécution de certaines opérations sur les MIC.
• CPU + MIC
Ce mode exploite l’ensemble des ressources de calcul (CPU + MIC) au niveau de chaque nœud de calcul. Elle est adaptée à l’exécution de programmes hybrides dans le mode natif MIC ou en mode symétrique. L’outil de développement sous Linux « Intel Cluster Studio XE » est utilisé dans l’environnement de programmation, et les chercheurs utilisent le compilateur Intel Fortran / C ++, et la bibliothèque Intel MPI selon leurs besoins pour créer les programmes. M. Boku indique « Les compilateurs gratuits peuvent aussi être efficaces pour certains programmes. Nous avons développé un système d’application dans laquelle nous ne spécifions pas un produit particulier pour le compilateur ou une bibliothèque, mais à la place, permettre aux chercheurs de choisir librement d’utiliser le compilateur ou les bibliothèques de leur choix ». Utilisé pour le développement d’applications scientifiques dans des domaines tels que la théorie des particules et de sciences de la vie les supercalculateurs COMA peuvent être utilisés par des chercheurs dans tout le pays, sans aucun frais dans le cadre du programme conjoint interdisciplinaire pour soutenir la recherche scientifique de pointe dans les domaines de la science et de l’ingénierie informatique. Des dispositions ont également été prises pour son utilisation libre sous le nom de « programme HPCI » promu par le Ministère de l’Education, de la Culture, des Sports et de la Science et technologie, et sous l’égide du “programme d’utilisation générale à grande échelle” qui est utilisé par les chercheurs dans tout le pays et cela gratuitement.
Les chercheurs appartenant au Centre de recherches de Tsukuba mènent des recherches en utilisant les capacités de calcul parallèle à haute vitesse de « COMA » dans le développement d’applications de calcul scientifique dans différents domaines tels que la théorie des particules, les domaines de l’astrophysique, les sciences de la vie, les sciences physiques et les sciences des matériaux, l’environnement et l’informatique. Le Professeur Boku a ceci à dire sur l’endroit où utiliser le cluster GPU parallèle à grande échelle « HA-PACS », qui a démarré en 2012.
« Il n’y a aucune classification basée sur l’objet de la recherche. Les chercheurs peuvent choisir la discipline qu’ils souhaitent, et après un examen attentif de l’objet de la recherche, peuvent s’inscrire dans le cadre du programme de recherche interdisciplinaire. Mais HA-PACS nécessite le développements d’applications optimisées pour être exécutées sur une architecture GPU. Contrairement à HA-PACS, COMA lequel utilise l’architecture Intel est très générique, et peut exécuter un plus grand nombre de programmes sans développements spécifiques ».
En proposant des conférences sur le calcul haute performance à des étudiants diplômés de l’école, nous développons les compétences en matière de calcul selon les techniques du Centre de recherches. Ce dernier est également actif dans la formation des étudiants du Centre qui favorise la collaboration interdisciplinaire entre la science et l’informatique. Selon le professeur Boku, « Aujourd’hui, la réalité est que le Japon est en pénurie de chercheurs dans le domaine scientifique capables d’écrire leurs propres programmes, par rapport à la situation à l’étranger. Par conséquent, afin de développer les compétences de nos chercheurs afin qu’ils puissent écrire leurs propres programmes informatiques dans divers domaines de recherche, nous assurons la tenue de cours en calcul haute performance pour les étudiants de l’école en cycle d’études supérieures. Nous assurons également des cours intensifs sur l’introduction au calcul haute performance pour les 40 à 50 étudiants de l’école d’études supérieures chaque année ».
Le Center for Computational Science de l’Université de Tsukuba et le Centre de Technologie de l’information, Université de Tokyo ont mis en place le «Joint Center for Advanced High Performance Computing (JCAHPC)”
Le Center for Computational Sciences de l’ Université de Tsukuba et le Centre de technologie de l’information de l’Université de Tokyo ont mis en place un système de conception de supercalculateurs réalisé par les enseignants de ces deux institutions dans le Tokyo University Information Technology Center situé dans le Campus Kashiwa de l’Université de Tokyo depuis le mois d’Avril 2015, et ont commencé des activités pour préparer le lancement d’un nouveau supercalculateur. C’est la première fois une telle expérience a été menée au Japon pour mettre en place une telle installation afin d’exploiter et de gérer conjointement un supercalculateur.
Trois centres de recherche universitaire HPC
Le Centre pour les Sciences Informatiques de l’Université de Tsukuba et le Centre de Technologie de l’information de l’Université de Tokyo ont mis en œuvre des projets dans le passé pour définir des spécifications de supercalculateur communes pour chaque université à travers le « T2K Open Super Computer Alliance » composé de trois centres académiques de l’Université de Tokyo. Les spécifications de la T2K Open Super Computer Alliance visent à réduire les coûts d’approvisionnement et l’amélioration des performances du système grâce à la liberté du choix des fournisseurs, et ils sont formulés sur la base de la doctrine de la « transparence », qui représente l’ouverture appliquée au matériel et l’indépendance de l’utilisateur. La création de JCAHPC est une étape dans cette direction, et la conception et le développement ainsi que l’exploitation et la gestion des supercalculateurs à haute performance sont réalisés conjointement par les centres d’information des deux universités avec pour objectif de promouvoir la technologie et l’état de l’art de la science informatique.
Nouvelle politique manycore
Le cadre de la politique qui a été établi pour la conception et le développement des supercalculateurs ne suit pas les roadmaps informatiques existantes mais à la place, utilise des processeurs many-core pour concevoir des de pointe qui lient le système d’exploitation, le langage de programmation, les bibliothèques de calcul numérique et les autres technologies logicielles au cours du processus de conception et de développement.
More around this topic...







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















{kind=link}
{kind=link}
{kind=link}