
The Evaluation and Validation Methodology
For single-node energy efficiency, we have measured a single Q7 board and compared the results against a power-optimized Intel Core i7 [10] laptop (Table 1), whose processor chip has a thermal design power of 35 W. Due to the different natures of the laptop and the development board, and in order to give a fair comparison in terms of energy efficiency, we are measuring only the power of components that are necessary for executing the benchmarks, so all unused devices are disabled. On our Q7 board, we disable Ethernet during the benchmarks execution. On the Intel Core i7 platform, graphic output, sound card, touch-pad, blue-tooth, WiFi, and all USB devices are disabled, and the corresponding modules are unloaded from the kernel. The hard disk is spun down, and the Ethernet is disabled during the execution of the benchmarks. Multithreading could not be disabled, but all experiments are single-threaded and we set their logical core affinity in all cases. On both platforms benchmarks are compiled with -O3 level of optimization using GCC 4.6.2 compiler.
The Single Node Performance
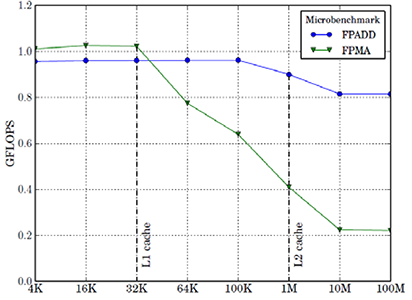
We start with the evaluation of the performance and energy efficiency of a single node in our cluster, in order to have a meaningful comparison to other state-of-the-art compute node architectures. In Figure 2 we evaluate the performance of Cortex-A9 floating-point double-precision pipeline using in-house developed micro benchmarks. These benchmarks perform dense double precision floating-point computation with accumulation on arrays of a given size (input parameter) stressing the FPADD and FPMA instructions in a loop. We exploit data reuse by executing the same instruction multiple times on the same elements within one loop iteration. This way we reduce loop condition testing overheads and keep the floating point pipeline as utilized as possible. The purpose is to evaluate if the ARM Cortex-A9 pipeline is capable of achieving the peak performance of 1 FLOP per cycle. Our results show that the Cortex-A9 core achieves the theoretical peak double-precision floating-point performance when the micro benchmark working set in the L1 cache (32 KB).
We also evaluate the effective memory bandwidth using the STREAM benchmark [10]. In this case, the memory bandwidth comparison is not just a core architecture comparison because bandwidth depends mainly on the memory subsystem. However, bandwidth efficiency, which shows the achieved bandwidth out of the theoretical peak, shows to what extent the core, cache hierarchy and on-chip memory controller are able to exploit chip memory bandwidth. We use the largest working set size that in the system. While it is true that the ARM Cortex-A9 platform takes much less power than the Core i7, it also requires a longer runtime, which results in a similar energy consumption the Cortex-A9 platform is between 5% and 18% better. Given that the Core i7 platform is faster, that makes it superior in other metrics such as Energy-Delay. Our single-node performance evaluation shows that the Cortex-A9 is 9 times slower than the Core i7 at their maximum operating frequencies, which means that we need our applications to exploit a minimum of 9 parallel processors in order to achieve competitive time-to-solution. More processing cores in the system mean more need for scalability. In this section we evaluate the performance, energy efficiency and scalability of the whole Tibidabo cluster.
The Cluster Energy Efficiency
For both Cortex-A9 and Cortex-A15, the CPU macro power includes the L1 caches, cache coherence unit and L2 controller [11]. Therefore, the increase in power due to a more complex L2 controller and cache coherence unit for a larger multicore are accounted when that power is factored by the number of cores. The memory power is overestimated, so the increased power due to the increased complexity of the memory controller to scale to a higher number of cores is also accounted for the same reason. Furthermore, a Cortex-A9 system cannot address more than 4 GB of memory so, strictly speaking, Cortex-A9 systems with more than 4 GB are not realistic. The remaining power in the compute node is considered to be overhead, and does not change with the number of cores. The board overhead is part of the power of a single node, to which we add the power of the cores, L2 cache and memory. However, we include configurations for higher core counts per chip to show what would be the performance and energy efficiency if Cortex-A9 included large physical address extensions as the Cortex-A15 does to address up to 1 TB of memory. The power model is summarized in these equations:
There are still no enclosures announced, and no benchmark reports, but we expect a better performance than ARMv7-based enclosures, due to an improved CPU core architecture and three levels of cache hierarchy. The Calxeda ECX-1000 SoC is built for server workloads: it is a quadcore chip with Cortex-A9 cores running at 1.4 GHz, 4 MB of L2 cache with ECC protection, a 72-bit memory controller with ECC support, five 10 Gb lanes for connecting with other SoCs, support for 1 GbE and 10 GbE, and SATA 2.0 controllers with support for up to five SATA disks. Unlike ARM-based mobile SoCs, ECX-1000 does not have a power overhead in terms of unnecessary onchip resources and, thus, it seems better suited for energy-efficient HPC. However, to the best of our knowledge, there are neither reported numbers for energy-efficiency of HPL running in a cluster environment (only single node executions) nor scientific applications scalability tests for any of the aforementioned enclosures.
Conclusion and Summary
In this paper we presented Tibidabo, the world’s first ARM-based HPC cluster, for which we set up an HPC-ready software stack to execute HPC applications widely used in scientific research such as SPECFEM3D and GROMACS. Tibidabo was built using commodity components that are not designed for HPC. Nevertheless, our prototype cluster achieves 120 MFLOPS/W on HPL, competitive with AMD Operton 6128 and Intel Xeon X5660-based systems. We identified a set of inefficiencies of our design given the components target mobile computing. The main inefficiency is that the power taken by the components required to integrate small low-power dual-core processors sets the high energy efficiency of the cores themselves. We perform a set of simulations to project the energy efficiency of our cluster if we could have used chips featuring higher performance ARM cores and integrating a larger number of them together. Based on these projections, a cluster configuration with 16-core Cortex-A15 chips would be competitive with Sandy Bridge-based homogeneous systems and GPU-accelerated heterogeneous systems in the Green500 list. These encouraging industrial roadmaps, together with research initiatives such as the EU-funded Mont-Blanc project, may lead ARM-based platforms to accomplish the recommendations given in this paper in a near future. In the future, more in-depth research will be conducted and simulated.
About the author
Yuwen Zheng is a researcher at the Shandong Women’s University, Jinan, 250300, China
Acknowledgements
The research work was supported by Shandong Provincial Staff Education office No. 2013-324.
References
[1] Forshaw, Matthew, A. Stephen McGough, and Nigel Thomas. “Energy-efficient Checkpointing in High-throughput Cycle-stealing Distributed Systems.” Electronic Notes in Theoretical Computer Science 310 (2015).
[2] Mulfari, Davide, Antonio Celesti, and Massimo Villari. “A computer system architecture providing a user-friendly man machine interface for accessing assistive technology in cloud computing.” Journal of Systems and Software 100 (2015): 129-138.
[3] Shukla, Surendra Kumar, C. N. S. Murthy, and P. K. Chande. “Parameter Trade-off And Performance Analysis of Multi-core Architecture.” Progress in Systems Engineering. Springer International Publishing, 2015. 403-409.
[4] Amin, Muhammad Bilal, et al. “Profiling-Based Energy-Aware Recommendation System for Cloud Platforms.” Computer Science and its Applications. Springer Berlin Heidelberg, 2015. 851-859.
[5] Bistouni, Fathollah, and Mohsen Jahanshahi. “Pars network: A multistage interconnection network with fault-tolerance capability.” Journal of Parallel and Distributed Computing 75 (2015): 168-183.
[6] Kaddari, Abdelhak, et al. “A model of service–oriented architecture based on medical activities for the interoperability of health and hospital information systems.” International Journal of Medical Engineering and Informatics 7.1 (2015): 80-100.
[7] Kenkre, Poonam Sinai, Anusha Pai, and Louella Colaco. “Real Time Intrusion Detection and Prevention System.” Proceedings of the 3rd International Conference on Frontiers of Intelligent Computing: Theory and Applications (FICTA) 2014. Springer International Publishing, 2015.
[8] You, Simin, Jianting Zhang, and L. Gruenwald. Scalable and Efficient Spatial Data Management on Multi-Core CPU and GPU Clusters: A Preliminary Implementation based on Impala. Technical Report 2015.
[9] Liu, Xiaoming, and Qisheng Zhao. “Cluster Key Scheme Based on Bilinear Pairing for Wireless Sensor Networks.” Proceedings of the 4th International Conference on Computer Engineering and Networks. Springer International Publishing, 2015.
[10] Singh, Balram, Shankar Singh, and Narendra Kumar Agrawal. “Mobile Agent Paradigm: A Tactic for Distributed Environment.”
[11] Mezhuyev, Vitaliy. “Metamodelling Architecture for Modelling Domains with Different Mathematical Structure.” Advanced Computer and Communication Engineering Technology. Springer International Publishing, 2015. 1049-1056.
More around this topic...
In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















{kind=link}
{kind=link}
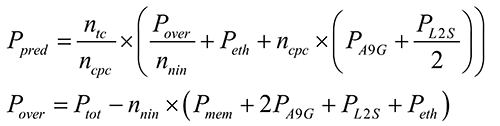{kind=link}