
The memory-bound problem
The pseudo-code in listing 1 shows the global idea: we initialize and read an array of hundreds of millions of floats, sum-up values and store them in a smaller array, focusing on the read memory-bandwidth rather than the reduce algorithm details. Data is always read in the best possible way.
Three Kepler K20X implementations are provided:
1 – A naïve access to the data for accumulation, in a coalesced way. This first approach does not imply any modification to an existing code.
2 – We use 128-bits loads, reading floats by groups of 4 and doing this twice per thread. This approach requires both vectorization and alignment of the reading blocks (note that alignment can be tested at runtime for just a small overhead in compute performance).
3 – We use the __ldg intrinsic to spare the L2 cache, and take advantage of the texture cache channel. In addition to the modifications introduced with implementation 2, operations are performed in read-only mode.
The results reported Table 4.A show correct performance in the naïve implementation, with a penalty of only 15% (or 24% without ECC) compared to the optimal performance.
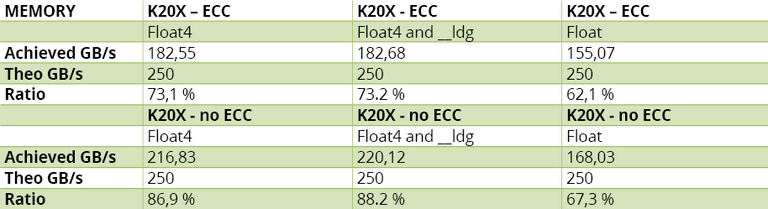
Table 4.A – Kepler K20X’s measured results to the memory-bound test.
Four Xeon Phi SE10P implementations are provided:
1 – A naïve approach where we let the compiler vectorize the code automatically.
2 – The same naïve implementation with vectorization explicitly disabled to simulate cases where the compiler cannot vectorize.
3 – We use the _mm512_i32gather_ps intrinsic to load data in an unaligned way. This requires vectorization.
4 – We use the _mm512_load_ps intrinsic to load data from aligned addresses.
Interestingly enough, the results reported Table 4.B show that the naïve implementation with vectorization enabled and hinted gives similar if not better performance than the gather version. Seems like the compiler does a fairly good job in this case. Implementation 2, which disables vectorization to see what kind of performance range can be achieved in a more complex example, reveals a performance penalty of (only) 5%.
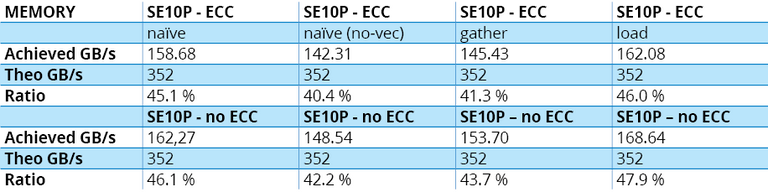
Table 4.B – Xeon Phi SE10P’s measured results to the memory-bound test.
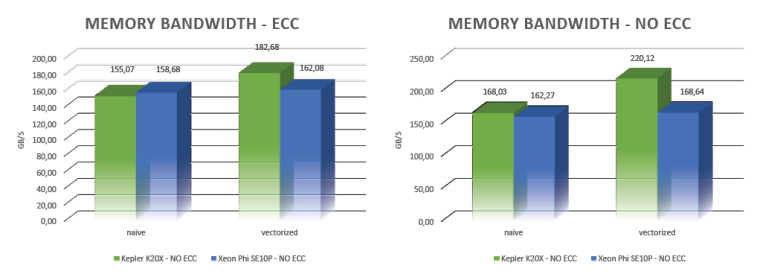
Fig. 1 – Kepler K20X’s and Xeon Phi SE10P’s measured results to the memory-bound test.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















