
The latency-bound problem
To evaluate our accelerators in this dimension, we chose to use an accessor to a lookup table, as lookups are not necessarily predictable by compiler and/or hardware. We kept the number of iterations small, in order to demonstrate latency in the read operations. Note that the index to the lookup table is the same for any number of entries, leading to a natural vectorization axis. For each product, we used the best possible size given the minimal work distribution. The pseudo-code is given in listing 3.
Three Kepler K20X implementations are provided:
1 – Naïve.
2 – Swapping the two loops.
3 – Using __ldg and processing entries by groups of eight.
Two Xeon Phi SE10P implementations are provided:
1 – Naïve.
2 – Intrinsic-based, with the loading of a complete 512-bit vector for each iteration.
The figures below highlight performance per problem size in achieved read bandwidth for the main array. Remark that Phi’s naïve implementation barely reaches 20 GB/s, a figure close to what could be reached by plain CPU setups. On the contrary, memory bandwidth in K20X is available even for smaller problem sizes.
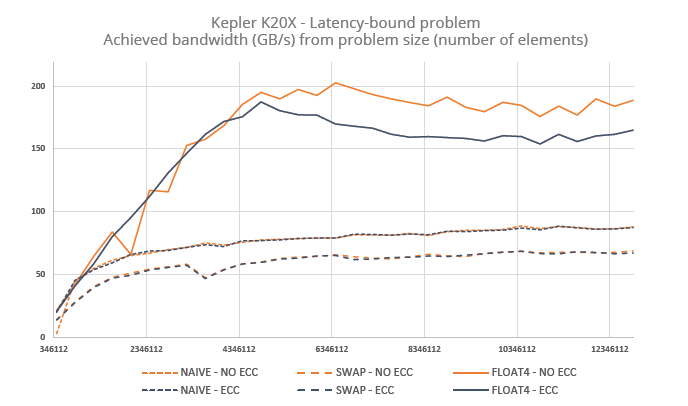
Fig. 3.A – Kepler’s SMXes being able to manage up to 8 blocks simultaneously, they can be viewed as hyper-threaded cores with 8 threads by core. That is why we used several problem sizes for our three implementations.
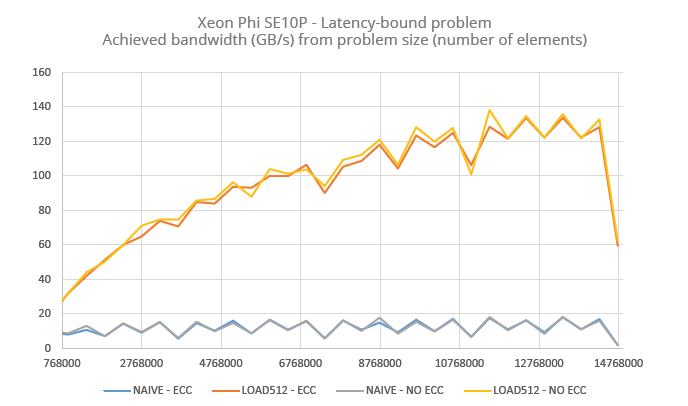
Fig. 3.B – Xeon Phi cores being able to run up to 4 threads simultaneously, we also used several problem sizes according to the hardware specs of the accelerator. Sharp dips can be remarked in the curves, for which we have no explanation.
Revisiting flops/memops
At the beginning of this article, Table 3 presented a comparison of performance figures based on the vendors’ official specs. The figures induced a flops/memops indicator that could be used to figure out whether an algorithm is compute- or memory-bound. Following our evaluation, it seemed pertinent to propose the same table again (Table 6 below) based on measured results.

Table 6 – Flops / memops ratios necessary to qualify a problem as compute-bound. The numbers are based on measured results and should be compared to those based on the vendors’ hardware specifications (between parentheses).
These results call for a few comments. First, the bandwidths we achieved are clearly lower than the theoretical ones. Is anyone surprised? Secondly, the advertised Gflops are not necessarily available, and counting fused multiply-adds as single flops seems more relevant when counting flops, since many algorithms do not map trivially on such operations. Last, the memory/compute ratios remain very high (and roughly similar in SP and DP): we need up to 35 floating-point operations per memory operation to be compute-bound. Regarding this particular point, take into account that if transcendental functions are to be used, algorithms might be compute-bound with Xeon Phi and memory-bound with Kepler.
EXCLUSIVE : Download the complete benchmark source code!
Several coding techniques have been discussed relating to the different implementations of our evaluation procedures. We thought it appropriate to clarify a few points about them.
• Vectorization – Changing an arithmetic operation on a scalar value into the same operation on a vector (fixed-size, preferably small) requires a complete refactoring of the algorithm and some additional branching management. The impact on code generation is heavy and performance of the generated code is highly dependent on the micro-library that makes use of intrinsics. Note that the effort has proved beneficial on both platforms. It should be worth your time on regular CPUs as well, especially when using AVX.
• Alignment – “Alignment” here stands for pointer dereferencing alignment. Memory should only be accessed by patterns of a certain size and at certain offsets. Enforcing alignment or “striding” is easy with small synthetic examples but often quite harder with real-life cases, especially when array indices derive from a complex computation. Our experiments showed that dynamically testing alignment with K20X comes at a reasonable expense. So does the use of gathers instead of aligned loads with Phi SE10P.
• Read-only assertion – When accessing memory, some assumptions can be made, for example that no other entity involved in the execution of the function/kernel will modify the data. In general, automating this assertion can easily be hinted by the programmer.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















