
Fonctions d’agrégation
Il est possible d’imaginer plusieurs fonctions d’agrégation. Les deux plus courantes sont :
- La somme pondérée.
- Le calcul de distance.
Dans le cas de la somme pondérée, on va simplement faire la somme de toutes les entrées multipliées par leur poids. Mathématiquement cela s’exprime sous la forme :
Dans le deuxième cas, celui du calcul des distances, on va comparer les entrées aux poids (qui sont les entrées attendues par le neurone), et calculer la distance entre les deux.
Pour rappel, la distance est la racine de la somme des différences au carré, ce qui s’exprime donc :
D’autres fonctions d’agrégation peuvent bien sûr être imaginées. L’important est d’associer une seule valeur à l’ensemble des entrées et des poids grâce à une fonction linéaire.
Fonctions d’activation
Une fois une valeur unique calculée, le neurone compare cette valeur à un seuil et en décide la sortie. Pour cela, plusieurs fonctions peuvent être utilisées. Les trois plus utilisées sont ici présentées.
Fonction “heavyside”
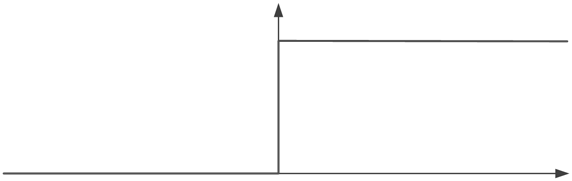
La fonction signe, ou heavyside en anglais, est une fonction très simple : elle renvoie +1 ou 0.
Ainsi, si la valeur agrégée calculée est plus grande que le seuil, elle renvoie +1, sinon 0 (ou -1 selon les applications).
Cette fonction permet par exemple la classification, en indiquant qu’un objet est ou non dans une classe donnée. Elle peut aussi être mise en place pour d’autres applications, mais elle reste parfois difficile à utiliser, car elle n’indique pas à quel point une valeur est forte. Elle peut donc ralentir l’apprentissage.
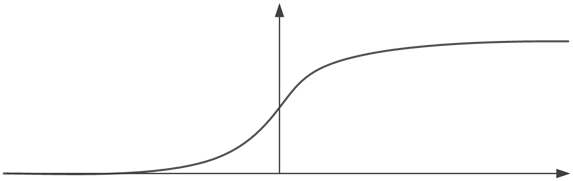
Fonction sigmoïde
La fonction sigmoïde utilise une exponentielle. Elle est définie par :
Elle est comprise entre 0 et +1, avec une valeur de 0.5 en 0.
Dans le neurone, la méthode est appelée avec x = valeur agrégée – seuil. Ainsi, on a une sortie supérieure 0.5 si la valeur agrégée est plus grande que le seuil, inférieure à 0.5 sinon.
Cette fonction permet un meilleur apprentissage, grâce à sa pente. En effet, il est plus facile de savoir vers quelle direction aller pour améliorer les résultats, contrairement à la fonction heavyside qui n’est pas dérivable.
La dérivée de la sigmoïde, utilisée lors de l’apprentissage, est :
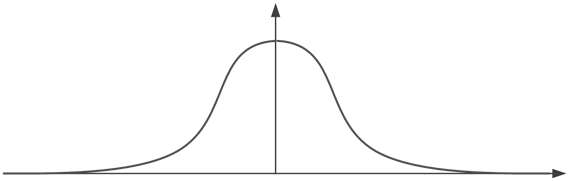
Fonction gaussienne : La dernière fonction très utilisée est la fonction gaussienne. Celle-ci, aussi appelée “courbe en cloche”, est symétrique, avec un maximum obtenu en 0. Son expression est plus complexe que pour la fonction sigmoïde, mais elle peut se simplifier sous la forme suivante, avec k et k’ des constantes dépendant de l’écart-type voulu :
Là encore, on utilisera la différence entre la valeur agrégée et le seuil comme abscisse.
Cette fonction étant aussi dérivable, elle permet un bon apprentissage. Cependant, contrairement aux fonctions précédentes, elle n’a qu’un effet local (autour du seuil) et non sur l’espace de recherche complet. Selon les problèmes à résoudre, cela peut être un avantage ou un inconvénient.
Poids et apprentissage : Les neurones formels sont tous identiques. Ce qui va les différencier, ce sont les seuils de chacun ainsi que les poids les liant à leurs entrées.
Sur des fonctions simples, il est possible de déterminer les poids et les seuils directement, cependant ce n’est jamais le cas lorsqu’un réseau de neurones est vraiment utile (donc sur des problèmes complexes).
L’apprentissage va donc consister à trouver pour chaque neurone du réseau les meilleures valeurs pour obtenir la sortie attendue. Plus un neurone a d’entrées donc plus il va y avoir de poids à ajuster, et plus l’apprentissage sera complexe et/ou long.
Perceptron
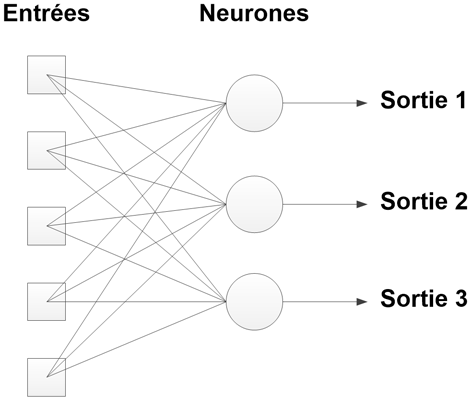
Le perceptron est le plus simple des réseaux de neurones. En termes de structure, un perceptron est un réseau contenant p neurones. Chacun est relié aux n entrées. Ce réseau permet d’avoir p sorties. Généralement, chacune représente une décision ou une classe, et c’est la sortie ayant la plus forte valeur qui est prise en compte. Avec 3 neurones et 5 entrées, on a donc 3 sorties. Voici la structure obtenue dans ce cas :
Le réseau possède alors 3 * 5 = 15 poids à ajuster, auxquels s’ajoutent 3 valeurs seuils (une par neurone).
More around this topic...
In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















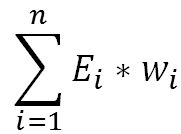{kind=link}
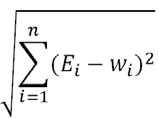{kind=link}
{kind=link}
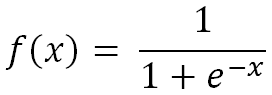{kind=link}
{kind=link}
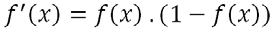{kind=link}
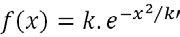{kind=link}
{kind=link}
{kind=link}