
Surapprentissage et généralisation
Lors de la phase d’apprentissage, il faut déterminer les critères d’arrêt. Ceux-ci permettent d’indiquer que le réseau a suffisamment bien appris les données fournies en exemple pour pouvoir ensuite être utilisé sur d’autres données. Cependant, il y a un fort risque de surapprentissage qu’il faut savoir détecter et contrer.
Reconnaître le surapprentissage
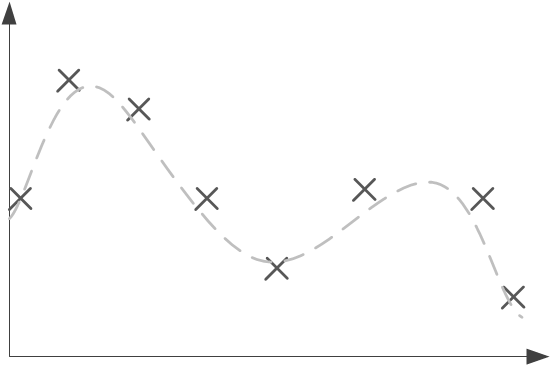
Le réseau apprend à partir des données qui lui sont fournies et va trouver une fonction globale permettant de limiter ses erreurs. Au départ, l’erreur sera forte, puis elle diminuera à chaque passage des données d’exemple et ajustement des poids. Cependant, à partir d’un certain seuil, le réseau va apprendre les points fournis et perdre complètement en généralisation, surtout si les données fournies sont légèrement erronées : on a alors du surapprentissage (ou over-fitting en anglais). Voici par exemple un problème simple, où il faut trouver la fonction généralisant les points donnés. Une bonne solution est proposée en pointillés.
Lorsque du surapprentissage apparaît, on peut alors se retrouver avec une fonction de ce type, qui passe par les points (l’erreur globale est donc nulle) mais perd complètement en généralisation :
Il est donc nécessaire non seulement d’évaluer la qualité de l’apprentissage, mais aussi la capacité de généralisation du réseau.
Création de sous-ensembles de données
Pour éviter le surapprentissage, ou au moins le détecter, nous allons séparer notre ensemble de données en trois sous-ensembles.
Le premier est l’ensemble d’apprentissage. C’est le plus important et il contient généralement 60 % des exemples. Il sert à l’algorithme d’apprentissage, pour adapter les poids et seuils du réseau.
Le deuxième ensemble, contenant environ 20 % des exemples, est l’ensemble de généralisation. À la fin de chaque passe, on teste l’erreur globale sur cet ensemble (qui n’a pas été utilisé pour changer les poids). Il nous indique à quel moment le surapprentissage apparaît.
En effet, si on trace au cours du temps l’erreur moyenne sur l’ensemble d’apprentissage et sur l’ensemble de validation, on obtient les courbes suivantes :
L’erreur sur l’ensemble d’apprentissage ne fait que baisser au cours du temps. Par contre, si dans un premier temps l’erreur sur la généralisation baisse, elle commence à augmenter lorsque le surapprentissage commence. C’est donc à ce moment-là qu’il faut arrêter l’apprentissage.
Le dernier ensemble est l’ensemble de validation. C’est lui qui permet de déterminer la qualité du réseau, pour comparer par exemple plusieurs architectures (comme un nombre de neurones cachés différent). Les exemples de cet ensemble ne seront vus par le réseau qu’une fois l’apprentissage terminé, ils n’interviennent donc pas du tout dans le processus.
Autres réseaux
Le perceptron et le réseau feed-forward sont les plus utilisés, mais il en existe de nombreux autres. Voici les trois principaux.
Réseaux de neurones récurrents
Dans un réseau de neurones récurrent, il existe non seulement des liens d’une couche vers les suivantes, mais aussi vers les couches précédentes. De cette façon, les informations traitées à une étape peuvent être utilisées pour le traitement des entrées suivantes. Cela permet d’avoir des suites de valeurs en sortie qui sont dépendantes, à la manière d’une série d’instructions pour un robot, ou un effet de mémorisation des pas de temps précédents. Ces réseaux sont cependant très difficiles à ajuster. En effet, l’effet temporel complique les algorithmes d’apprentissage, et la rétropropagation ne peut pas fonctionner telle quelle.
Cartes de Kohonen
Les cartes de Kohonen, ou cartes auto-adaptatives, contiennent une grille de neurones. Au cours du temps, chacun va être associé à une zone de l’espace d’entrée, en se déplaçant à la surface de celui-ci. Lorsque le système se stabilise, la répartition des neurones correspond à la topologie de l’espace. On peut donc ainsi faire une discrétisation de l’espace. Ces cartes sont cependant peu utilisées dans des applications commerciales, à cause de leur complexité de mise en place.
Réseaux de Hopfield
Les réseaux de Hopfield sont des réseaux complètement connectés : chaque neurone est relié à tous les autres. Lorsqu’on soumet une entrée au réseau, on ne modifie l’état que d’un neurone à la fois, jusqu’à la stabilisation du réseau. L’état stable est donc la “signature” de l’entrée. L’apprentissage consiste à déterminer les poids de manière à ce que des entrées différentes produisent des états stables différents, mais que des entrées presque identiques conduisent au même état.
De cette façon, si des erreurs entachent légèrement une entrée, elle sera quand même reconnue par le réseau. On peut ainsi imaginer un système permettant la reconnaissance des lettres, même si celles-ci sont abîmées ou moins lisibles. L’apprentissage dans ces réseaux se fait grâce à une variante de la loi de Hebb. Celle-ci indique qu’il faut renforcer la connexion entre deux neurones s’ils sont actifs en même temps, et diminuer le poids sinon.
More around this topic...
In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}
{kind=link}