
Souvent ignorées des scientifiques, les techniques d’optimisation des couches MPI
sous-jacentes aux applications peuvent s’avérer décisives en termes de performances.
Ce mois-ci, nous nous penchons sur les stratégies d’interaction avec les transports InfiniBand, avec à la clé un bug dans MVAPICH2 et un appel à témoins…
Jérôme Vienne, PhD
HPC Software Tools Group
Texas Advanced Computing Center (TACC)
Si les bibliothèques MPI (MPICH, Open MPI, Intel MPI, Mvapich2, etc…) suivent un standard, elles se caractérisent aussi par un ensemble de spécificités à bien connaître si l’on veut optimiser finement l’exécution des applications qui les utilisent. Dans notre article précédent, nous avons traité la question du placement des processus MPI et du choix des algorithmes utilisés pour les communications collectives. A cette occasion, nous avons vu que les choix techniques des développeurs des bibliothèques étaient parfois très différents, et que les ignorer pouvait nous priver d’importants facteurs d’accélération.
Ce mois-ci, nous allons nous pencher sur les possibilités offertes par les implémentations MPI lorsque que l’on exécute une application à grande échelle sur des connexions InfiniBand. Comme chacun sait, le nombre de cœurs présents au sein des clusters du TOP500 est en perpétuelle augmentation. Pour les scientifiques, c’est tout bénéfice : ces énormes ressources leur permettent de s’attaquer à des problèmes de plus en plus complexes. Mais le fait d’utiliser plus de cœurs augmente aussi la consommation mémoire pour chaque processus MPI…
Dans un tel contexte, réduire l’espace mémoire occupé par les processus devient critique. Mon expérience à TACC m’a permis de constater que beaucoup d’utilisateurs de nos grappes de calcul ignorent que le standard InfiniBand et son implémentation Mellanox proposent différents moyens pour aider à réduire cette consommation mémoire. Nous allons donc en regarder deux de plus près : l’eXtended Reliable Connection (XRC) et l’Unreliable Datagram (UD).
Au cœur d’InfiniBand
Année après année, InfiniBand s’est fait une place de choix dans la communauté HPC. En juin 2003, une seule configuration TOP500 l’utilisait ; à mesure que la technologie s’est développée, son taux d’adoption a progressé de façon constante, de sorte qu’en ce moment, elle équipe 205 systèmes, soit 41 % du classement. Il s’agit donc, sans conteste, de la principale architecture réseau haut performance disponible aujourd’hui.
En pratique, la rapidité des connexions InfiniBand permet de réduire la durée des phases de communication et, par conséquent, de limiter les temps d’attente au niveau des cœurs. Un réseau InfiniBand se distingue en effet par deux caractéristiques essentielles : une faible latence et une large bande passante, synonyme de débits élevés. Pour mémoire, la latence correspond au temps nécessaire à l’envoi et à la réception du premier octet, tandis que la bande passante mesure le débit maximal obtenu via l’envoi de messages de grandes tailles.
D’un point de vue technique, l’architecture InfiniBand définit quatre types de couches transport : Reliable Connection (RC), Reliable Datagram (RD), Unreliable Datagram (UD) et Unreliable Connection (UC). Les couches RC et UD étant les plus à même d’être utilisées par les applications MPI, c’est à elles que nous allons nous intéresser aujourd’hui. Nous négligerons volontairement la couche RD, qui n’est implémentée par aucun matériel (contrairement aux trois autres) et n’est pas utilisable avec MPI. UC, quant à elle, offre un mode connecté mais, outre que ce mode n’est pas d’une grande fiabilité, l’ordre d’arrivée des paquets n’est pas garanti. Bien qu’elle supporte les accès RDMA, la quantité mémoire nécessaire pour l’utiliser est identique à celle de RC, si bien qu’elle est finalement peu intéressante pour les bibliothèques MPI.
En termes de proportion d’usage, RC se taille la part du lion. Pour les développeurs, le choix de RC se justifie par sa fiabilité, par le fait qu’elle fonctionne en mode connecté et parce qu’elle est le transport qui offre le plus de possibilités sur InfiniBand (RDMA, opération atomique, etc.). Cela étant précisé, lorsque le nombre de processus MPI augmente, RC est aussi le mode de transport le plus coûteux en ressources. Pourquoi ? L’explication est simple : comme on est en mode connecté, chaque partenaire d’une communication doit établir une connexion dédiée nécessitant un espace mémoire de quelque Ko. C’est peu, mais lorsque l’on exécute des expériences à grande échelle, l’espace mémoire combiné peut très vite atteindre de l’ordre du Go par processus. Pour vous donner une idée, si l’on considère N nœuds chacun avec C cœurs, chaque processus MPI devra établir (N-1) x C connexions pour pouvoir communiquer avec les autres processus MPI. Pour faire face à ce problème, compte tenu de l’augmentation régulière du nombre de cœur par socket, Mellanox a développé l’eXtended Reliable Connection sur ses cartes ConnectX. XRC est donc disponible sur ces cartes et les suivantes, pour peu que l’on utilise la bibliothèque OFED (OpenFabrics Enterprise Distribution) en version 1.3 ou postérieure.
Priorité à l’eXtended Reliable Connection (XRC) ?
Dans les transports InfiniBand, il n’y a pas de distinction entre une connexion au niveau cœur ou au niveau nœud. L’idée d’XRC est donc d’autoriser une connexion unique entre un processus et un nœud entier, ce qui réduit le nombre de connexions nécessaires pour chaque processus MPI au nombre total des nœuds. En utilisant XRC, chaque processus MPI devra donc établir (N-1) connexions pour pouvoir communiquer avec tous les autres processus MPI.
La figure 1 permet d’apprécier cette différence. Au passage, il faut noter qu’XRC peut être utilisée avec la plupart des bibliothèques MPI dont bien sûr Open MPI, Mvapich2 et Intel MPI. Attention, dans ce dernier cas, elle ne fonctionne qu’avec les ressources OpenFabrics Alliance et non avec DAPL.
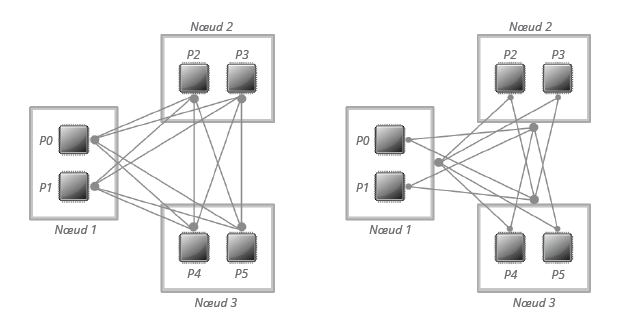
Fig.1 : Comparaison des connexions entre RC (à gauche) et XRC (à droite).
Au niveau performance, toutefois, les bénéfices ne sont pas flagrants. Si quelques gains peuvent être observés sur certaines applications dans la mesure où la quantité mémoire disponible est supérieure, nous ne pourrons malheureusement pas les quantifier de façon précise. Nous avions en effet prévu un certain nombre de tests basées sur Mvapich2 1.9, mais il s’avère qu’XRC présente un bug (en tout cas sur le cluster Stampede) qui rendrait les résultats inutilisables. La rédaction de cette article nous aura au moins permis de le détecter et de le reporter à l’équipe de développeurs. Cela étant, d’expérience, XRC reste coûteux sur les applications à très grande échelle impliquant un nombre élevé de cœurs ou de nœuds. Dans de telles conditions, et sous certaines réserves, il peut être recommandé d’utiliser la couche Unreliable Datagram, comme nous allons le voir maintenant.
L’Unreliable Datagram (UD)
Contrairement aux couches RC et XRC, UD est un transport non connecté, ce qui réduit le besoin en ressources mémoire pour les processus MPI. L’inconvénient, c’est qu’UD est beaucoup moins riche en fonctionnalités. Par exemple, RDMA n’est pas supporté et la taille des messages se limite à la valeur de la MTU. La bibliothèque MPI a donc plus de travail à faire, notamment pour gérer la segmentation, l’ordre et la retransmission des messages. En toute logique, le coût en performance n’est pas négligeable dans les contextes applicatifs mobilisant un petit nombre de nœuds et fonctionnant à partir de messages de grande taille.
Au contraire, pour les codes utilisant principalement des messages courts, la quantité mémoire requise pour chaque processus MPI reste quasiment constante lorsque l’on augmente la taille du système. Par ailleurs, sachant qu’il n’est plus nécessaire de perdre du temps à établir les connexions, UD permet d’obtenir de meilleurs performance lorsque l’on utilise beaucoup de nœuds.
Pour benchmarker cela, nous avons utilisé l’application SMG2000 compilée avec Intel MPI sur le cluster Stampede, en utilisant 4 096 cœurs et les paramètres suivants :
mpiexec.hydra –n 4096 … ./smg2000 -n 120 120 120 -c 2.0 3.0 40 -P 16 16 16
Activer UD avec Intel MPI implique de définir deux variables d’environnement :
export I_MPI_DAPL_UD_PROVIDER=ofa-v2-mlx4_0-1u
export I_MPI_DAPL_UD=enable
Pour rappel, Intel MPI supporte différents types de protocole de communication, mais elle est principalement optimisée pour DAPL.
Solveur multigrid parallèle, SMG2000 fait partie des “ASC Purple Benchmarks”, une série de tests développée par le Lawrence Livermore National Laboratory (LLNL). SMG2000 est structuré en trois étapes : “Struct interface”, “Setup phase” et “Solve phase”. La figure 2 montre la moyenne des temps d’exécution de chacune de ces étapes sur dix exécutions avec et sans UD.
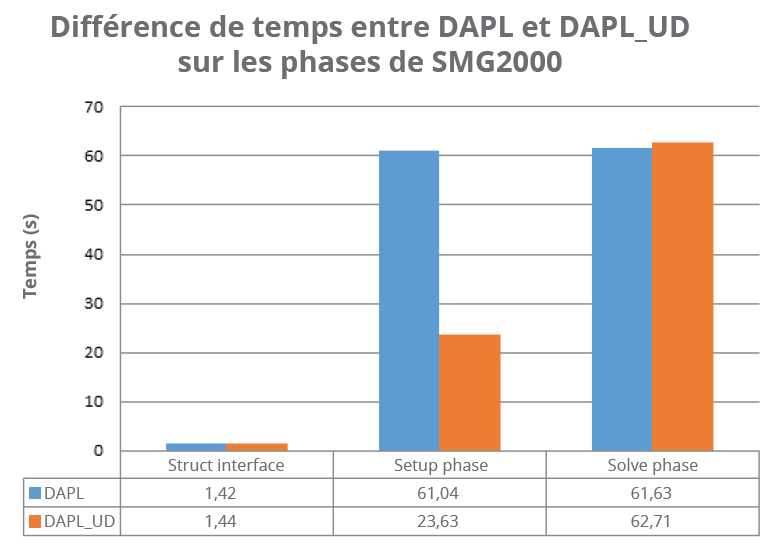
Fig.2 : Moyenne des temps d’exécution pour chacune des étapes de SMG2000, avec et sans UD..
Comme vous pouvez le constater, les temps d’exécution relevés pour la première et la dernière phase sont grosso modo identiques. En revanche, la différence est importante concernant la phase Setup. L’explication est simple : cette phase est principalement constituée de communications non bloquantes point-à-point de petite taille entre les différents processus MPI. UD ne nécessitant pas de connexion, l’envoi de messages est beaucoup plus rapide. Quand on sait que plus de 1 060 841 238 messages sont échangés, on peut comprendre que le léger gain de temps pour chaque communication se traduise au final par une accélération globale sensible.
Autre avantage lié à UD : en règle générale, le temps de démarrage des programmes MPI est beaucoup plus court. Un simple Hello World avec 16K cœurs peut prendre plus d’une 1 minutes 30 avec DAPL alors qu’il démarre en moins de 30 secondes avec DAPL_UD.
Qu’en est-il pour les applications utilisant des messages de grandes tailles ? La musique est tout autre. Les envois sur UD ne pouvant dépasser la taille MTU, les messages longs nécessitent plus de paquets, d’où un risque supérieur de perte de ces paquets. Dans un tel contexte, la consommation mémoire peut s’avérer, au cas par cas, nettement plus importante.
Conclusion temporaire
Cet article se proposait d’examiner deux approches différentes destinées à optimiser la scalabilité des applications sur réseau InfiniBand. Laquelle est la meilleure ? On l’a vu, tout dépend de votre bibliothèque MPI et de votre application. Si celle-ci requiert le passage de larges messages, XRC peut se révéler plus profitable à grande échelle, bien que nous n’ayons pu le tester valablement pour les raisons techniques mentionnées plus haut. En revanche, si les messages de votre applications restent de taille contenue, c’est-à-dire s’ils sont inférieurs à la taille de la MTU, UD peut se révéler meilleur, sous réserve que votre bibliothèque MPI le supporte. Et pour l’avenir ?
La nouvelle famille d’interconnexions Connect-IB de Mellanox propose un nouveau protocole appelé “Dynamically-connected transport”, dont l’objectif est précisément de réduire la consommation mémoire. Que donne ce protocole comparé aux deux autres dans les cas que nous avons évoqués ? Sachant que notre laboratoire n’a pas encore déployé les cartes ad hoc, difficile de le mesurer. Promis, dès que les conditions du test seront réunies, nous y reviendrons en détail. Dans l’intervalle, si vous-même êtes en mesure de benchmarker l’ensemble, nous sommes volontiers preneurs des résultats. Cette rubrique n’a-t-elle pas vocation à être un effort collaboratif visant à partager les meilleures pratiques de développement HPC ?
More around this topic...
Related articles


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















