
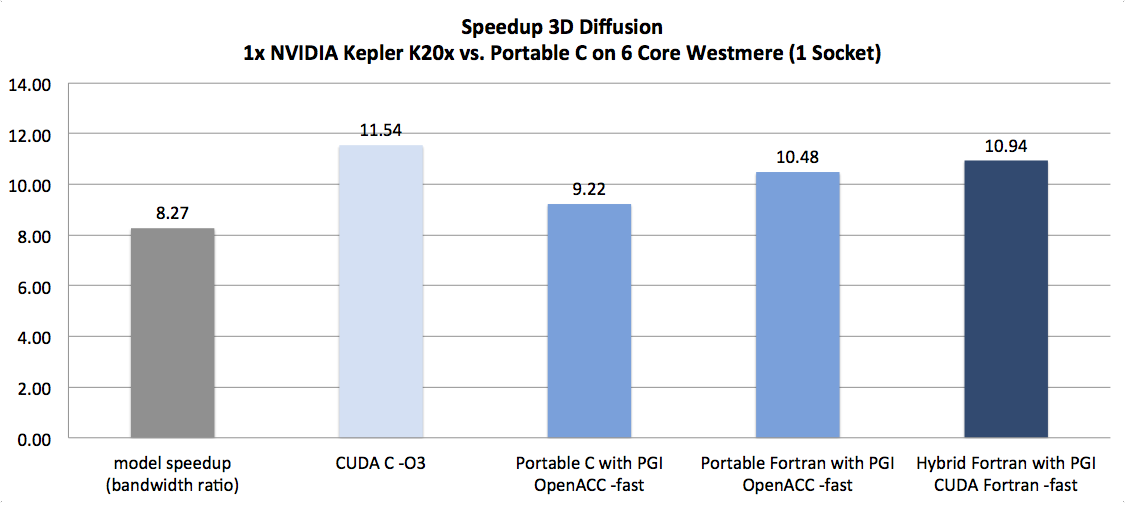
As HPC programmers and scientists know, porting CPU code to accelerators means portability and performance issues. To tackle them, a new approach called “Hybrid Fortran” is presented, based on an Open Source framework to create performance portable Fortran code for different parallelizations, including CUDA, OpenMP and OpenACC. Five different applications have been ported with good speedups, ease-of-use and CPU performance characteristics…
Here’s what HPC programmers are constantly looking for:
- Performance (on all current systems -and hopefully future ones too),
- Portability (who likes rewrites just because a new architecture comes along, right?), and
- Maintainability (just like in any other computer science field, code should be clean, so that it can be changed easily, preferably by those directly working with the applications).
The following is a tale of how these properties will affect your work if you decide to look into accelerator programming.
Suppose you are at the beginning of programming an HPC application. No problem, right? You know how the underlying machine works in terms of memory architecture and ALUs. (Or not? Well, that’s no problem either, because the compilers have become so good that I’m hearing, they will surely figure it out). You know what numeric approximation will be used to map your problem most efficiently. You know all about Roofline performance modeling, so that you can verify whether or not your algorithm performs on the hardware the way you’ve expected. And you know what you’re supposed to do when you encounter data parallelism. So – let’s sit down and do it!
But wait!
You hear that your organization is ordering a new cluster. In order to get closer to Exascale, this cluster will sport these fancy new accelerators. So all new HPC software projects should evaluate, if and how they can make use of coprocessors. You start reading up on the accelerator landscape. OpenCL, CUDA, OpenACC, OpenMP, ArrayFire, Tesla, Intel MIC, Parallela… Your head starts spinning from all this stuff – all these hardware and software tools have lots of overlap, but also significant differences. Most importantly, they’re very different from x86 CPU architecture. Why is that?
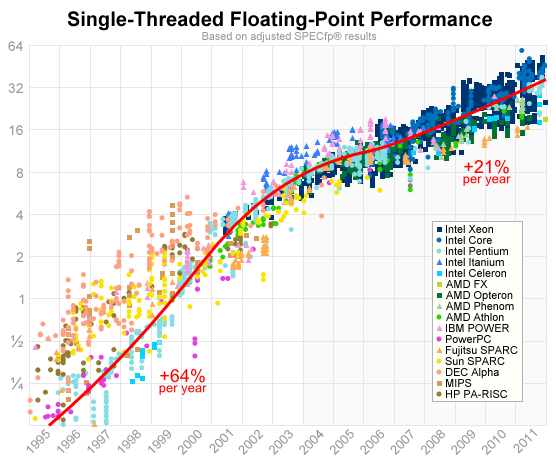
It essentially comes down to the fact that in 2005, the free lunch was over.
CPU vendors still claim to perform according to Moore’s law today. However, while in past decades you could simply compile your code for a new CPU, since around 2005 you are forced to rethink it. Processor clock rates have hit their limit, so in order to gain significant speedups, more parallelisms were introduced that you need to care about.
Michel Müller started doing GPGPU in 2010 during his master studies at ETH Zurich, when he became involved in the first feasibility study to port the COSMO weather model to GPGPU. In 2012 he went to the Tokyo Institute of Technology to get his hands on the TSUBAME 2.5 supercomputer for his master thesis, which he wrote as a guest at Professor Aoki’s renowned laboratory. Given the task to port the physical core of the next generation Japanese weather model, he essentially went through the thought-process as described in the article, which lead to the development of Hybrid Fortran. This work has been continued during his time at RIKEN Advanced Institute for Computational Science in Kobe, Japan and at Aoki laboratory, where Michel is currently employed.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}
{kind=link}