
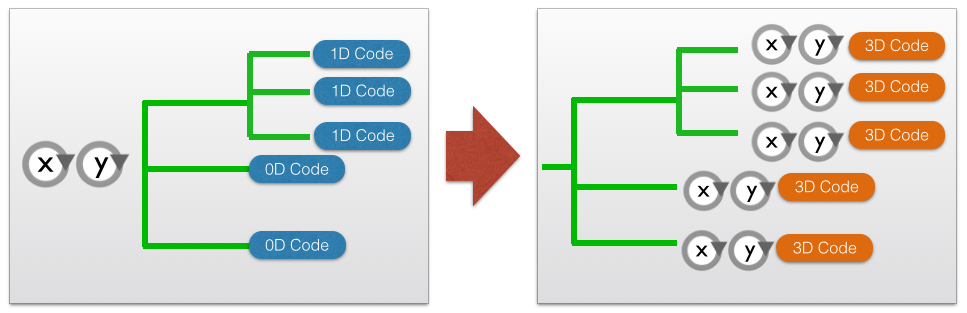
You come to the conclusion that the only way this code is going to be parallelized for GPGPU is by rewriting it with tight loops, passing 2D- or 3D data around instead of 0D or 1D. What you initially thought would be a simple act of wrapping code, turns into a major rewrite with almost 100% of the code inside the main iteration affected. Alright, that’s annoying – but you surmise that since the next cluster’s architecture has already been decided, it will have to be done anyway. (Surely you haven’t given up yet, have you?)
But wait!
While preparing for the next big cluster update is a swell thing, what about all the existing CPU-only clusters? They’ll still be operational for the next few years and your application is still needed on them. Plus, the scientists working with your software need to be able to constantly tweak it in order to fit their latest needs. If you simply let them use the old version on these machines, it will diverge from your nicely accelerated one pretty quickly. Furthermore, while talking to them you find out that they are not happy with your plans – why should the code now be written in higher dimensions – all that’s going to do is inserting x,y without any offsets anywhere in the code, in each array access and each declaration. All that manual labor just to serve the architecture – and who knows what new loop structure it’s going to take once the next big architectural change comes along – will we have to rewrite everything again? Then comes the final blow – you’re doing some tests with this new loop structure and you start seeing huge performance losses when executing this on the CPU. When analyzing it, you notice that:
- since this codebase is often memory bandwidth limited, cache performance is essential;
- passing around higher dimensional data flushes out the CPU cache between the procedures, so the cache’s effect goes down significantly;
- GPU and CPU have different optimal storage orders in this case – CPU likes Z-first, since lots of calculations over different values of Z are close together in the code. GPU meanwhile likes X-first, since all its little cores are reading and storing values in lock step – and X is mapped to their thread ids, which in turn is mapped directly to the hardware cores.
Essentially, you’ve come up with a portable solution, but it’s not performance portable. How are you going to explain to your users that they now have to write code in a more complicated 3D version so that it’s slower on their current machines? Isn’t there a better way? You remember Larry Wall’s three great programmer virtues: Laziness, Impatience and Hubris. Is it smart to do these code transformations by hand? It looks like it affects all basic properties of ideal HPC code negatively: Neither is it performance portable, nor is it very maintainable. Has no one come up with a better solution? Can’t the machine do this for you?
Yes. The machine can.
You start by googling keywords like Fortran GPU storage order, Fortran performance portable or Fortran GPGPU. Again and again you see one framework coming up. It’s Open Source and it’s called Hybrid Fortran, and it was created to solve exactly these issues that you’ve just run into.
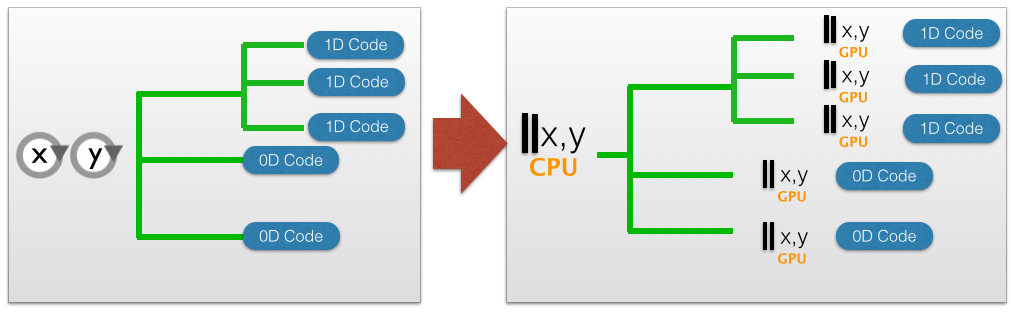
Do you see the big difference between the code transformation we talked about above, and the one introduced here? Yes – all your computational code stays the same, you can keep it in whatever low dimensionality you like – Hybrid Fortran takes care of the necessary transformations at compile-time (so there is no runtime overhead). There’s only two things you need to introduce in addition:
- Where is the code to be parallelized? (Can be specified for CPU and GPU separately.);
- What symbols do you need to be transformed in different dimensions?
Hybrid FORTRAN is simply a (python based) preprocessor that parses these annotations together with your FORTRAN code structure, declarations, accessors and procedure calls, and then writes separate versions of your code – once for CPU with OpenMP parallelization and once for GPU with CUDA Fortran.
But what about the performance?
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}
{kind=link}