
Well, see for yourself:
| Name | Performance Results | Performance Characteristic | Speedup HF on 6 Core vs. 1 Core [1] | Speedup HF on GPU vs 6 Core [1] | Speedup HF on GPU vs 1 Core [1] |
|---|---|---|---|---|---|
| Japanese Physical Weather Prediction Core (121 Kernels) | Slides Only Slidecast | Mixed | 4.47x | 3.63x | 16.22x |
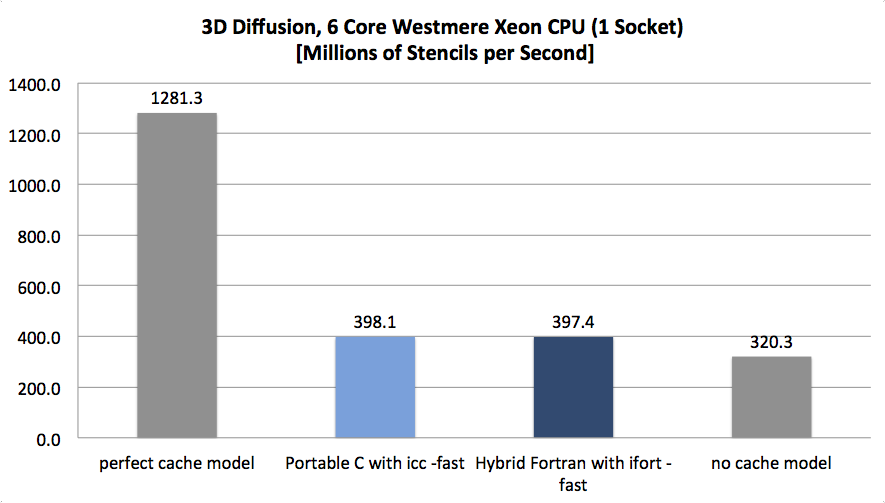
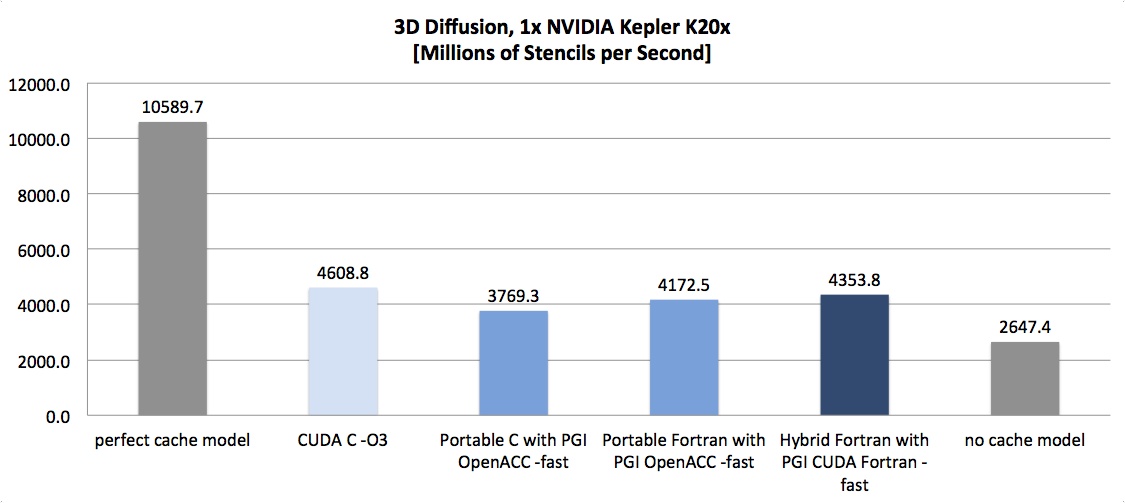
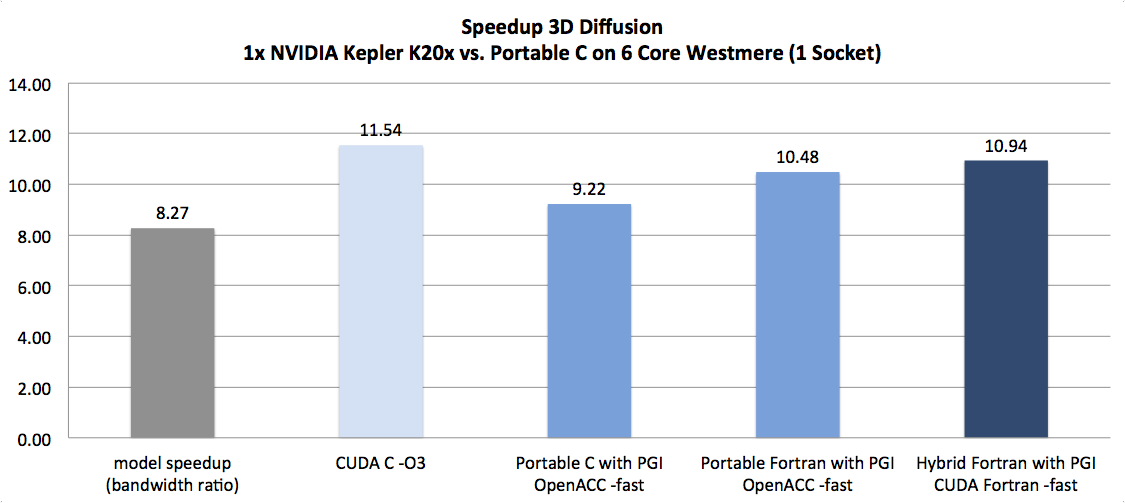
| 3D Diffusion (Source) | XLS | Memory Bandwidth Bound | 1.06x | 10.94x | 11.66x |
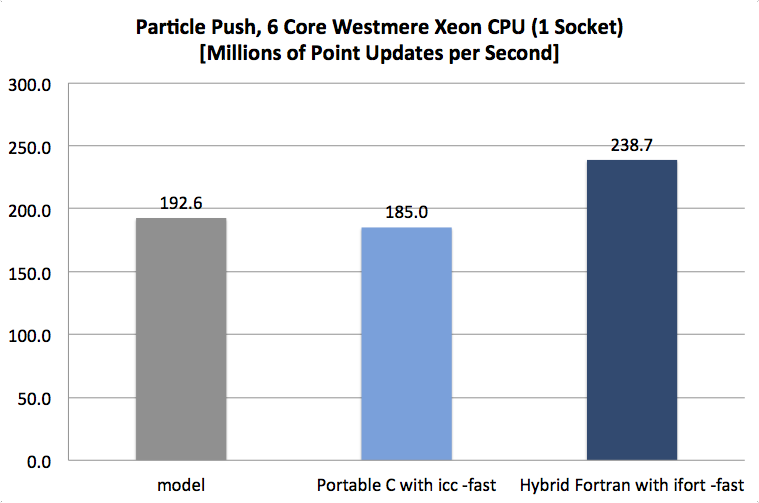
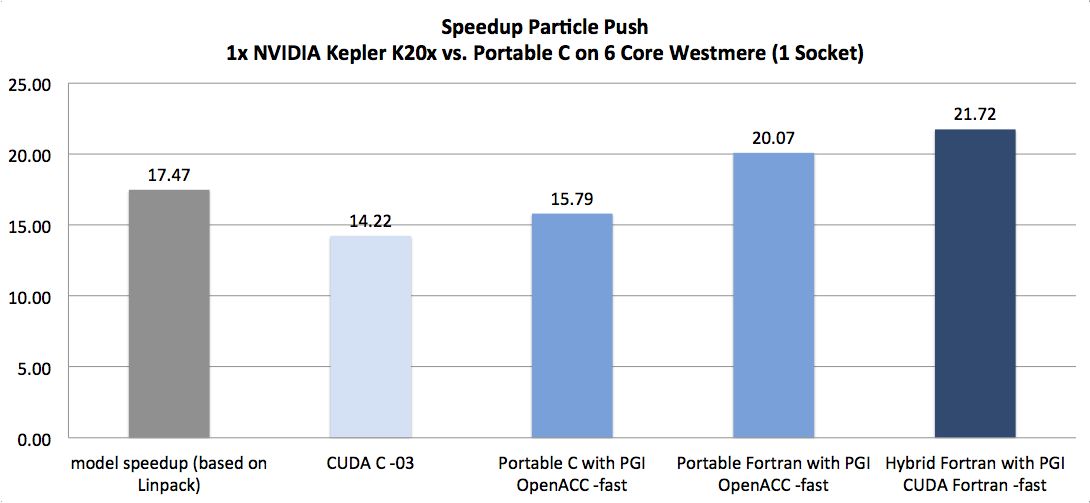
| Particle Push (Source) | XLS | Computationally Bound, Sine/Cosine operations | 9.08x | 21.72x | 152.79x |
| Poisson on FEM Solver with Jacobi Approximation (Source) | XLS | Memory Bandwidth Bound | 1.41x | 5.13x | 7.28x |
| MIDACO Ant Colony Solver with MINLP Example (Source) | XLS | Computationally Bound, Divisions | 5.26x | 10.07x | 52.99x |
[1] If available, comparing to reference C version, otherwise comparing to Hybrid FORTRAN CPU implementation. Kepler K20x has been used as GPU, Westmere Xeon X5670 has been used as CPU (TSUBAME 2.5). All results measured in double precision. The CPU cores have been limited to one socket using thread affinity ‘compact’ with 12 logical threads. For CPU, Intel compilers ifort / icc with “-fast” have been used. For GPU, PGI compiler with ‘-fast’ setting and CUDA compute capability 3.x has been used. All GPU results include the memory copy time from host to device.
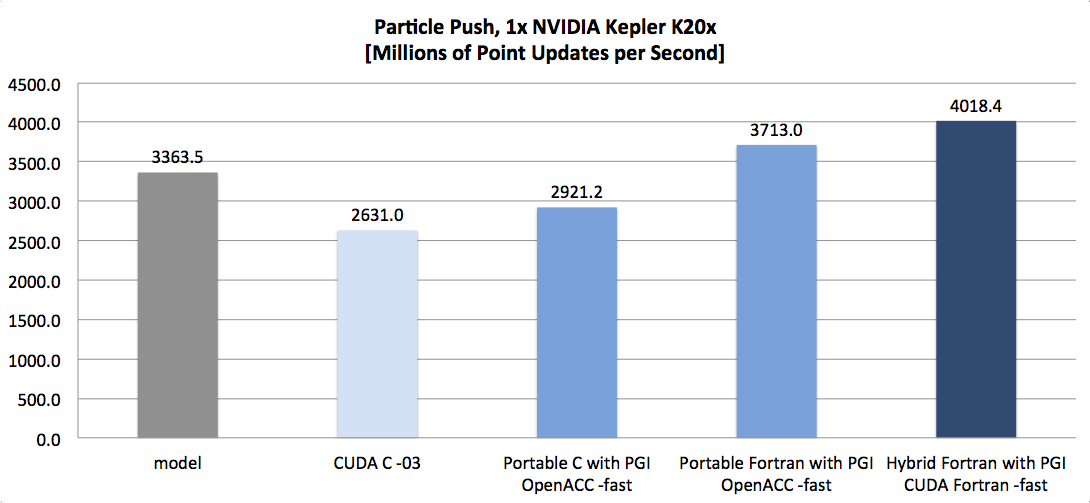
For the Diffusion and Particle Push examples, there is also a model analysis (see XLS links) as well as comparisons with CUDA C, OpenACC/OpenMP C and OpenACC Fortran available (see attachments at the end of this post).
But wait, there’s more!
You notice that in this framework, the portability goes even further.
First, hardware-specific properties such as the vector size have been abstracted away from the code by using a ‘template’ attribute for parallel regions. When new hardware with a different vector size comes along, your code only needs to be adapted in one place that defines the templates.
Next, the python preprocessor has the parallelization implementation completely separated from the parser. When a new architecture comes along with a different FORTRAN parallelization scheme (for example ARM multiprocessors with OpenCL), all that needs to be done is a new implementation class. As an example, here is the python class that implements the OpenMP parallelization scheme.
To conclude
You have found a solution to port your code that:
- works for all kinds of shared memory data parallelizations on GPU and CPU,
- enables the fastest portable code you can find thus far,
- comes within a few percent of the highest measured performance, both on GPU and CPU,
- requires the least amount of code changes for coarse grained parallelizations, i.e. allows scientists to keep their code in low dimensions, and
- can be adapted for new parallelization schemes without changing your code.
As the following figures demonstrate, we’re on to something here:
(NB: bars with a grey shade show the theoretical model; bars with darker blue shades show more portable results while lighter blue shades show more architecture specific results)
Happy hybrid Fortran programming!
Hybrid FORTRAN is available under LGPL licence on github.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}