
PREMIERE PARTIE – LES PROMESSES ET LES CONTRAINTES
L’arrivée de «Phi» bouleverse le paysage de la programmation HPC. Sa spécificité – une architecture x86 native – en fait à la fois un complément idéal à Xeon et un concurrent crédible aux accélérateurs GPU. Pour autant, adopter Xeon Phi ne va pas sans efforts…
• Articles complémentaires : Les meilleures voies d’optimisation
Cet article inaugure une série consacrée à la programmation de Xeon Phi. Le choix d’une architecture HPC par rapport à une autre étant par nature stratégique, il nous a paru indispensable de commencer par l’évaluation de son potentiel de performances et de ses contraintes techniques. De ce fait, cette introduction reste légère en code source. Elle a néanmoins pour but de constituer une base de référence pour les articles qui suivront – et de vous permettre d’adopter le premier coprocesseur Xeon massivement parallèle avec le plus d’efficacité possible.
Prise en mains
Que nous dit Intel ? D’une part, que Xeon Phi augmente la programmabilité de Xeon en lui apportant un support de vectorisation étendu et une efficacité énergétique qui maximise les possibilités de scaling. D’autre part, que Xeon Phi a pour avantage concurrentiel une architecture x86 native synonyme d’adaptation plutôt que de véritable portage des sources. Doit-on en conclure qu’avec l’adjonction d’un simple coprocesseur, les performances de classe HPC s’offrent à nos applications ? Non, bien sûr, la réalité est plus subtile. Un certain nombre d’aménagements restent nécessaires pour exploiter de façon optimale les 60 cœurs disponibles. Sans ces aménagements, nous allons le voir, le gain effectif plafonne assez vite.
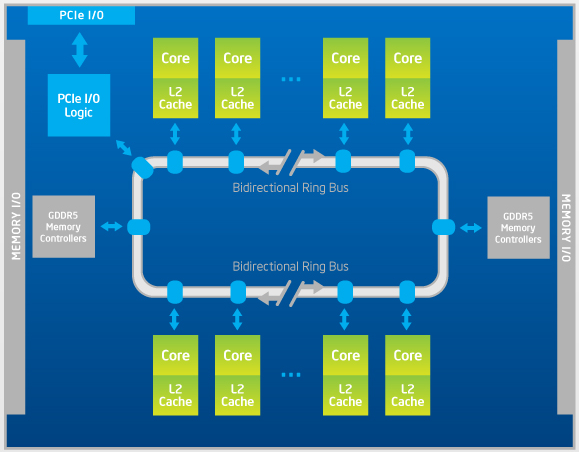
Pour comprendre pourquoi, commençons par un petit tour du propriétaire. Dans un système Xeon classique, plusieurs processeurs sont connectés pour former un cluster. Au-delà de leur propre mémoire cache, ils bénéficient d’un accès commun et cohérent à la mémoire centrale. Phi, quant à lui, est un système multiprocesseurs à lui tout seul. Il exécute son propre OS (un Linux dédié téléchargeable), expose à ses cœurs internes une même mémoire partagée, dispose de sa propre adresse IP et passe par le bus PCIe pour communiquer avec les autres éléments du système – ce qui explique que sa mémoire cache est totalement autonome.
On apprécie mieux cette relative indépendance structurelle – et le surcroît de ressources disponibles d’un coup – via une petite session terminal. La commande ssh mic0 nous amène sur la première carte Phi du système, après quoi un simple /proc/cpuinfo liste à l’écran les caractéristiques de chacun des processeurs virtuels disponibles. Ne vous étonnez pas si la liste est longue : le système en recense 240, soit 60 cœurs à 1 GHz multipliés par 4 threads matérielles pouvant accéder aux 512 Ko de cache L2 partagé. Au passage, notez que rien n’interdit, à partir de notre fenêtre de terminal, l’exécution de commandes, de scripts ou de programmes MPI sur tout ou partie de l’arsenal.
Les dessous de l’affaire
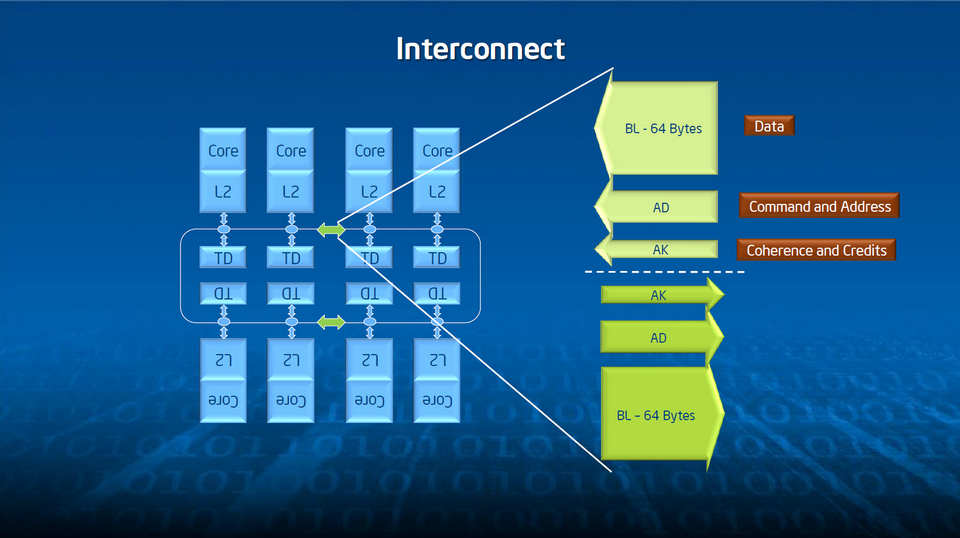
Filons la métaphore du propriétaire et examinons brièvement les fondations de l’architecture. Pour remarquer d’abord que, si l’on reste bien totalement compatible x86, la logique spécifiquement x86 (hors cache L2) n’occupe qu’environ 2 % de l’électronique de Phi. Le reste est constitué du support 64 bits, des quatre threads matérielles par cœur, de la gestion de l’énergie, des interconnections en anneau bidirectionnel et de la logique liée aux instructions SIMD 512 bits.
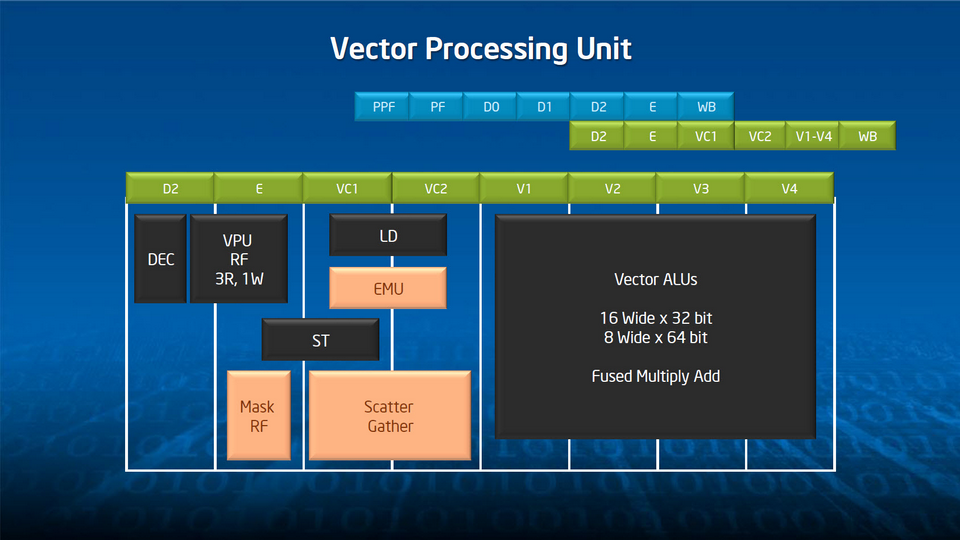
Point important, les quatre threads matérielles sont typiquement utilisées pour compenser les latences liées à l’architecture in-order des cœurs. C’est pourquoi, en développement, on gagne quasiment toujours à utiliser au minimum deux threads par cœur. Ne l’oubliez pas : le bénéfice de cette discipline sera nettement plus important que celui qui résulte de la mobilisation des hyper-threads avec un Xeon classique.
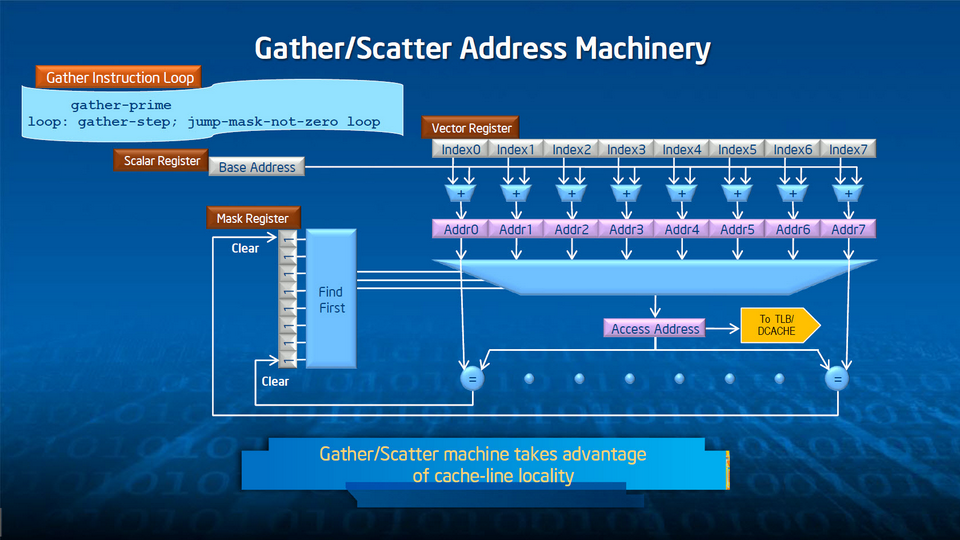
Pour en tirer le meilleur parti, Intel a doté Xeon Phi d’instructions spéciales qui complètent, dans une optique de programmation HPC, le jeu d’instructions x86-64. D’abord, comme mentionné plus haut, les vecteurs de 512 bits remplacent avantageusement les jeux d’instructions traditionnels du monde Intel – MMX, SSE ou AVX – par nature plus étroits. Ensuite, les cœurs sont câblés pour traiter de façon optimisée un certain nombre d’opérations mathématiques : fonctions réciproques, logarithmiques, exponentielles et racines carrées. Enfin, le système de gestion du stockage en mémoire interne (8 Go de GDDR5) a lui aussi fait l’objet d’un certain nombre d’attentions (indexation, streaming..), de façon à ce que la bande passante, annoncée à 320 GO/s, soit maximale à l’intérieure de la carte coprocesseur dans son entier.
100 threads minimum
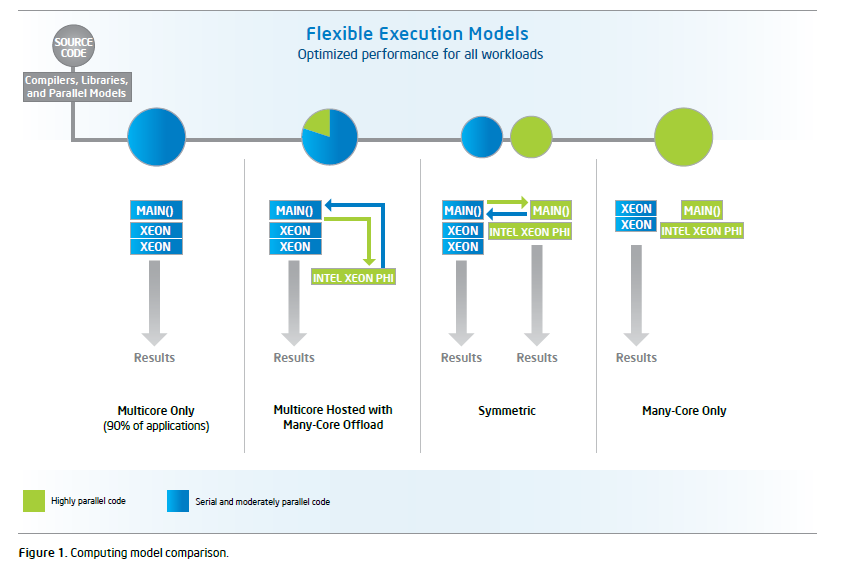
Cette check-list nous amène à la conclusion suivante : le gain en performance ne sera véritablement sensible qu’à condition que les applications puissent exploiter un haut degré de parallélisme. Concrètement, cela signifie qu’en deçà d’une centaine de threads, l’utilisation d’un Xeon Phi ne se justifie pas pleinement – c’est-à-dire qu’un (ensemble de) Xeon classique(s) devrait suffire à exploiter l’application concernée avec un ratio performances / coût + contraintes optimal.
En contexte de développement réel, à partir d’un source existant pour ne pas dire legacy, ce seuil d’une centaine de threads ne pose pas de réel problème. Les techniques et les outils abondent – de l’utilisation de OpenMP au do concurrent de Fortran en passant par des compilateurs tiers – qui permettent paralléliser les algorithmes sans trop d’effort. Typiquement, on applique une directive, un mot-clé ou un modèle (template) à une boucle itérative pour en dériver à l’exécution autant de threads que l’on souhaite. Le listing 1 (en C et en Fortran) montre deux exemples élémentaires mais déjà très efficaces de création de threads sur une boucle OpenMP. En général, on terminera cette première passe d’optimisation par un travail de restructuration ou d’alignement plus en finesse pour maximiser les gains en performances. Au final, la lisibilité générale du programme n’en sera pas dramatiquement affectée.
Evaluer scaling et vectorisation
Ce principe fondamental étant posé, faire exploser le compteur de threads ne servira à rien si l’application elle-même n’est pas structurellement conçue pour une exécution massivement parallèle. C’est d’ailleurs la raison pour laquelle Intel recommande d’évaluer son éventuelle capacité à être parallélisée avant d’investir dans Xeon Phi. Avec la règle de base suivante : même si les opérations scalaires prédominent sur les opérations vectorielles, il y aura un bénéfice effectif à l’utilisation de Xeon Phi à condition que les opérations multithreads prédominent sur les opérations monothread. Ce qui semble au premier regard vérité de La Palice est à lire de la façon suivante : pour atteindre un degré de performance équivalent, Xeon Phi demande plus de parallélisme que Xeon. Un développeur averti en vaut deux…
Comment procéder à cette évaluation ? En commençant par déterminer trois points fondamentaux :
- l’application telle qu’elle existe aujourd’hui atteint-elle les capacités de scaling maximales de Xeon classique ?
- l’application utilise-t-elle de façon intensive des données vectorisées ?
- l’application serait-elle susceptible de profiter d’une bande passante mémoire supérieure à celle offerte par Xeon classique ?
Concernant le premier point, quelques tests relativement rapides suffisent à mesurer les capacités de dimensionnement. A commencer par un simple graphe de performances, réalisé avec différentes configurations de threading (généralement de 1 jusqu’au nombre de cœurs présents sur le système) sur un système Xeon classique uniquement. Ces configurations s’obtiennent facilement en paramétrant l’exécution de l’application, par exemple avec la directive OMP_NUM_THREADS en mode OpenMP. Si le graphe ne montre pas une corrélation forte entre gain en rapidité et nombre de threads (ce nombre étant lui-même, rappelons-le, fonction du nombre de cœurs Xeon classiques disponibles sur le système hôte), cela signifie qu’il reste un certain nombre d’ajustements possibles sur le code source avant d’atteindre les limites du système Xeon classique existant – et donc avant que le passage à Xeon Phi soit apporte un réel bénéfice.
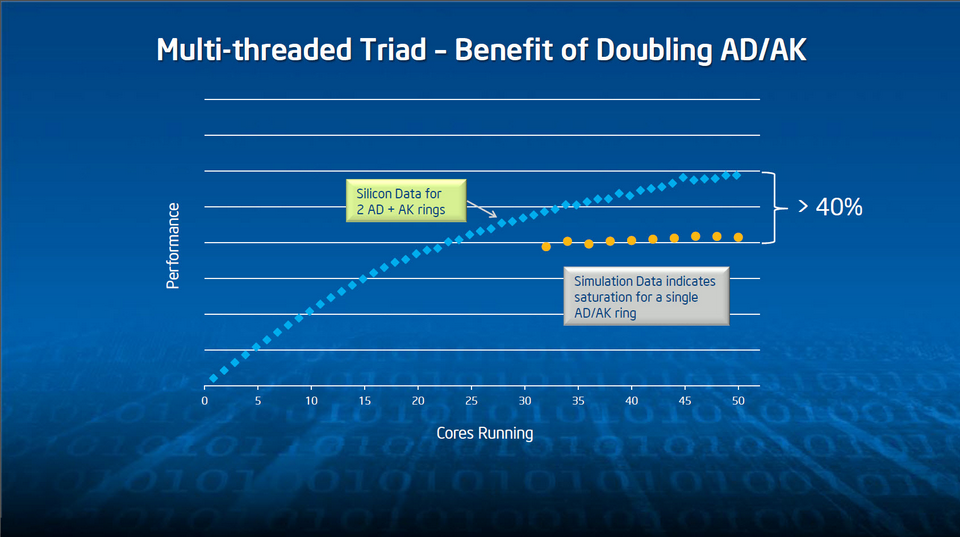
Concernant le deuxième point, l’approche la plus efficace consiste à compiler l’application avec et sans vectorisation. Les compilateurs actuels le permettent assez facilement, surtout si vous utilisez leurs fonctions d’auto-vectorisation. Si les différences de performances ne sautent pas aux yeux, la première étape est peut-être d’augmenter le degré de vectorisation du source. Sachez à cet égard qu’une majorité de bibliothèques mathématiques restent vectorisées quel que soit le mode de compilation de l’application qui les appelle. Par conséquent, le temps d’exécution des routines mathématiques doit être considéré comme du temps avec vectorisation. C’est un élément à ne pas négliger, Xeon Phi n’étant réellement efficace que sur les instructions vectorielles.
Enfin, concernant les éventuels bénéfices d’une bande passante mémoire plus large, n’oubliez pas au préalable de vérifier que votre programme n’abuse pas de références trop éloignées et qu’il profite intelligemment des différents niveaux de mémoire cache disponibles sur Xeon classique (cf. nos deux encadrés Les meilleures voies d’optimisation et La mémoire cache est votre amie). Avec une application de type MPI, l’idéal est que le ratio communication / calcul ne soit pas trop élevé – ce qui se mesure sans trop de douleur avec un simple profileur – celui d’Intel, par exemple ! En théorie, il est toujours judicieux de chercher à rapprocher temporellement les opérations de communication et d’entrées/sorties, d’une part, et les calculs d’autre part. Un coprocesseur, qui permet justement de décharger sur de multiples cœurs les opérations de logistique, peut à ce niveau aussi se révéler un bon investissement.
Reste maintenant à entrer un peu plus dans le dur avec des exemples de code réels, des tests reproductibles et quantifiables, la comparaison des différents modèles de programmation qu’autorise Xeon Phi en fonction du langage et du contexte applicatif, et l’utilisation d’outils externes (compilateurs, bibliothèques, profileurs… signés Intel mais pas seulement). C’est ce que nous vous proposerons dans la suite de cette série d’articles au cours des mois prochains. Dans l’intervalle, n’hésitez pas à nous faire part de vos réactions et de vos premières aventures concrètes avec Xeon Phi sur notre site…
La mémoire cache est votre amie
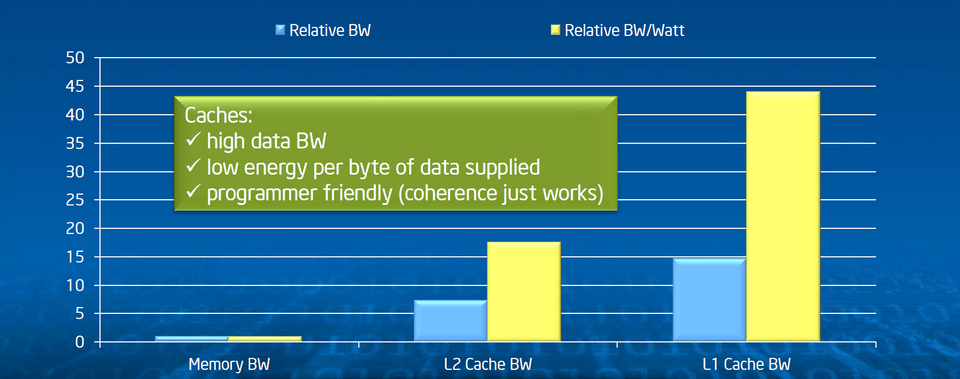
C’est en utilisant avec précision les différents niveaux de mémoire cache qu’on obtient les meilleures performances applicatives. Mais Xeon Phi a ses particularités, qu’il est bon de connaître.
La règle d’or, c’est d’organiser le code de façon à ce que les données connexes tiennent dans des blocs de 512 Ko (ou moins), dans le but d’arriver à nombre de “cache miss” aussi proche que possible de zéro. Les quatre threads matérielles de chaque cœur partagent le cache L2 du cœur concerné mais bénéficient aussi d’un accès à haut débit aux caches des autres cœurs du coprocesseur. Toute donnée utilisée par un cœur X est présente dans son cache L2 mais peut également être présente dans d’autres caches L2 du coprocesseur.
Or, là où un système Xeon classique ralentit les échanges entre sockets – ce qui se produit généralement au-delà de 16 threads (soit 8 cœurs avec 2 hyper-threads chacun) – Phi est conçu pour des échanges impliquant jusqu’à 200 cœurs. Il est toutefois préférable d’organiser la proximité des données d’abord entre threads d’un même cœur, puis dans un second temps entre la globalité des threads du coprocesseur. Pour cela, spécifier des affinités avec des instructions telles que KMP_AFFINITY (OpenMP) ou I_MPI_PIN_DOMAIN (MPI) est tout indiqué.
Notez à ce propos qu’Intel revendique fièrement aucun différentiel de performance en fonction de la proximité physique des cœurs dans le coprocesseur. Pour le fondeur, c’est la preuve d’un excellent design. Pour ce qui nous occupe, cela signifie qu’il n’est pas nécessaire de parcourir dynamiquement les ressources internes de Xeon Phi dans le but d’optimiser le placement et la répartition des tâches.
Qui abandonnera l’accélération GPU ?
Intel arrivant sur un marché où les coprocesseurs GPU sont plus que présents, son discours est nécessairement assez agressif – au sens commercial du terme. Selon le fondeur, les accélérateurs GPU partagent effectivement avec Xeon Phi bon nombre point communs en matière d’optimisation du scaling, de la vectorisation et de l’usage de la bande passante mémoire. En clair, si votre application donne de bons résultats avec une carte Tesla ou FirePro, alors elle donnera a priori d’aussi bons résultats avec une carte Xeon Phi.
Mais Intel revendique une meilleure programmabilité pour Xeon Phi dans la mesure où celui-ci permet d’exécuter des applications qui ne peuvent tourner sur des GPU. Il en conclut que l’effort d’optimisation pour les GPU et les particularités propres à leurs environnements de programmation impliquent des niveaux d’investissement supérieurs sur l’ensemble du cycle de vie de l’application. Si en théorie tout cela n’est pas faux, reste que l’écosystème HPC ne s’est pas trop mal porté jusqu’ici.
Dans un contexte vierge de tout investissement HPC précédent, cet argument peut suffire. La difficulté sera de convaincre les développeurs familier du modèle GPU à abandonner leurs acquis techniques et opérationnels…
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















