
Démonstrations applicatives, roadmaps technologiques, annonces produits… la “keynote” inaugurale de cette 4ème GTC, menée tambour battant par Jen-Hsun Huang, ne manquait pas de surprises. Un show à l’américaine, comme si vous y étiez !
A l’image de l’Intel Developer Forum, la GPU Technology Conference s’est imposée d’année en années comme un rendez-vous incontournable tant pour la presse que pour les diverses communautés techniques concernées. Et comme à chaque fois, c’est Jen-Hsun Huang, patron de NVIDIA, qui a ouvert le bal. Chacun a pu apprécier ses talents d’entertainer (plus de 2 heures sur scène) – des talents bien servis par une série d’annonces et de démonstrations en direct qui ont, avouons-le, captivé un parterre de milliers de participants.
Le rythme technologique s’accélère
Car Huang n’était pas venu les mains vides. L’annonce des nouveaux GPU Kepler n’a que six mois environ, et déjà on sait ce que seront les deux prochaines générations. L’année prochaine, NVIDIA lancera l’architecture Maxwell, dont le point fort est une gestion unifiée de la mémoire virtuelle entre CPU et GPU. Concrètement, le fondeur promet qu’avec cette génération, CPU et GPU seront capables chacun d’accéder à l’ensemble des ressources mémoire du système hôte. C’est techniquement déjà le cas aujourd’hui, mais cette nouvelle architecture, qu’accompagnera une mise à jour majeure de CUDA, en rendra la programmation beaucoup plus facile.
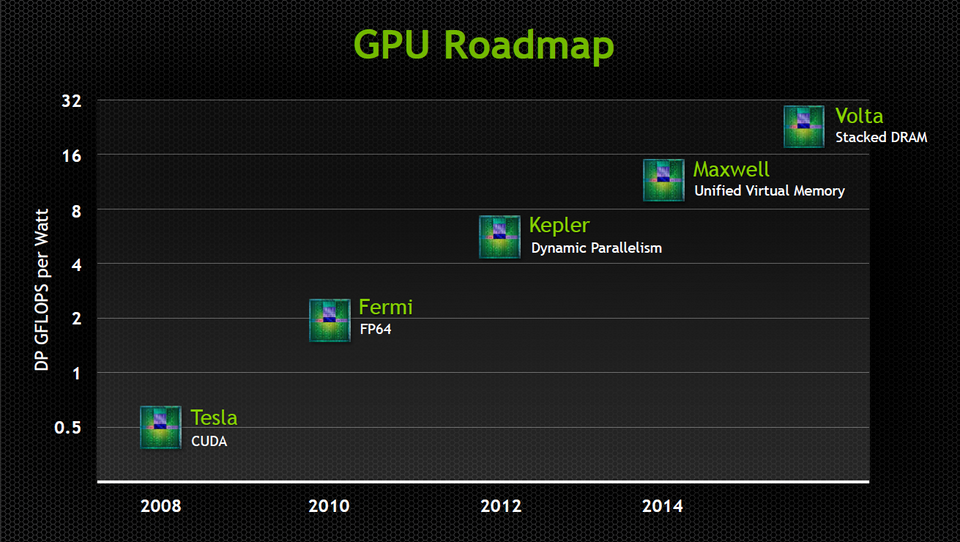
Deux ans plus tard, c’est-à-dire si tout va bien fin 2016, NVIDIA devrait annoncer la disponibilité commerciale des GPU “Volta”, avec cette fois encore une innovation majeure : la mémoire empilée. Aujourd’hui, la mémoire des GPU réside sur un circuit imprimé “à part”, placé au plus près du processeur graphique mais électroniquement et physiquement séparé de celui-ci. Avec Volta, non seulement les composants mémoire seront physiquement placés au-dessus du GPU, mais ils seront eux-mêmes superposés en couches discrètes. Résultat : des accélérateurs de taille réduite, avec une efficacité énergétique accrue (deux facteurs importants pour leur intégration par milliers dans de gros clusters) et, surtout, une explosion de la bande passante. Huang estime que Volta croisera à environ 1 To/s, un taux qui permettrait par exemple de transférer le contenu intégral d’un disque Blu-ray de la mémoire au GPU en 1/50ème de seconde. Et que d’ici-là, les problèmes d’industrialisation et de dissipation thermique inhérents à ce type de configuration seront résolus.
Des produits mobile pour le HPC ?
Du côté des processeurs mobiles, la roadmap était tout aussi ambitieuse. Au point d’ailleurs que parler de “mobilité” uniquement n’a plus de sens. Les perspectives qu’ouvre la gamme Tegra lui permettent de s’inscrire en alternative aux CPU classiques, notamment dans le cadre des efforts d’intégration massive de “petits” cœurs hybrides aux clusters clouds et locaux.
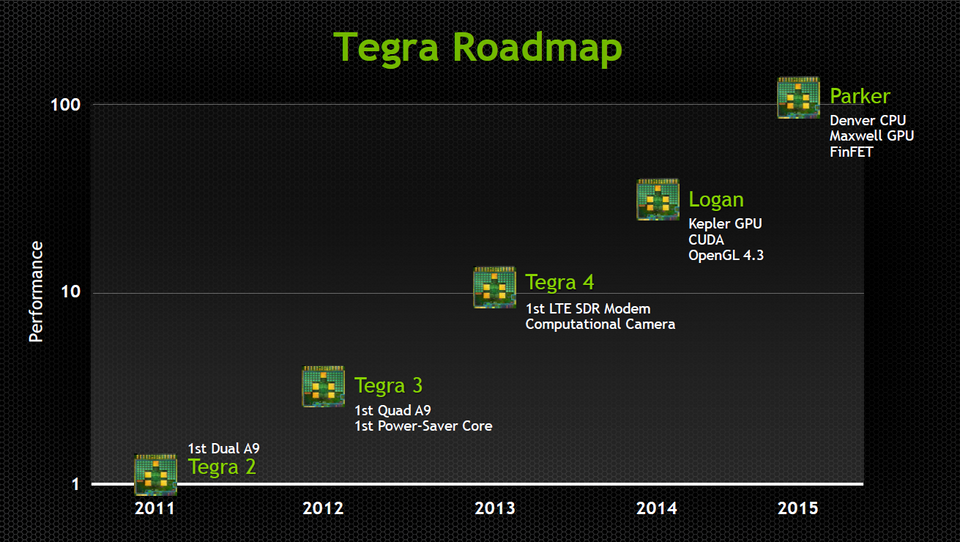
Déjà disponible, Tegra 4 est basé sur un noyau Cortex A-15 quadri-cœurs. Une version 4i, mise en production plus tard cette année, intégrera la 4G LTE. Mais la vraie révolution est pour 2014, où la version baptisée “Logan” embarquera un GPU Kepler complet et sera compatible OpenGL 4.3. De l’aveu même de Huang, les premiers prototypes sont déjà en fabrication, ce qui laisse à penser que la roadmap sera effectivement tenue.
18 à 24 mois plus tard, NVIDIA devrait annoncer “Parker”, autre saut quantique, qui sera constitué d’un processeur ARM 64 bits et d’un GPU Maxwell (voir plus haut) complets. “Par rapport à la génération 3, nous aurons alors multiplié les performances de Tegra par 100“, déclarait fièrement Mr Huang.
Pour mieux illustrer les progrès accomplis jusqu’ici, le boss avait judicieusement émaillé sa présentation de démonstrations live dont certaines étaient assez bluffantes. On a pu voir, par exemple, une simulation d’océan réalisée avec l’application Waveworks et mettant à contribution diverses générations de GPU. Au début, on est encore dans un jeu vidéo. Mais à mesure qu’on change de processeur et que les données de vitesse du vent (échelle de Beaufort) sont prises en compte grâce à l’augmentation des ressources de calcul, la simulation atteint un niveau de réalisme remarquable. Les vagues, les creux, la houle, l’écume, le cargo en souffrance… on s’y croyait réellement.
Conversation avec un alien
Montant d’un cran dans la difficulté technique, la simulation d’une conversation entre Huang et un personnage virtuel dont le visage était en très gros plan a elle aussi fait son petit effet. Chacun sait que la simulation des visages est délicate non seulement du fait des très nombreux paramètres qui régissent nos expressions et le jeu systémique de nos traits, mais aussi parce que notre cerveau est capable de déceler un niveau de détails faciaux bien plus élevé que pour n’importe quel autre sujet d’observation.

C’est FaceWorks, application basée sur une énorme bibliothèque d’expressions filmées en vidéo, qui avait été choisie pour la démonstration. FaceWorks a en effet ceci de particulier qu’elle permet, grâce à l’accélération GPU, de rendre en temps réel ces expressions par le biais de “meshes” 3D. Si l’on distinguait encore souvent le caractère artificiel du personnage, il faut reconnaître que nous n’avions, pour notre part, jamais vu de simulation humaine dynamique aussi convaincante.
Le niveau de détail dans le grain de la peau, dans l’expression des rides, dans la logique musculaire qui accompagne l’élocution d’Ira (le personnage virtuel) étaient tout simplement époustouflants. De l’aveu même de Huang, on était à un niveau de performance d’environ 40 000 opérations par pixel à une fréquence de 60 Hz…
Des pavés dans la mare
Et c’est là précisément, que les démonstrations prenaient toute leur cohérence. Car elles avaient été conçues à partir de nouveaux produits commerciaux annoncés ce matin-là en même temps que les roadmaps technologiques. A commencer par GTX Titan, une carte graphique de très haut de gamme que Huang a qualifié de “most complex semiconductor device ever made“. Positionnée à environ 1000 $ aux Etats-Unis, Titan inclut un processeur GK110, le même que dans les accélérateurs Kepler K20. Elle offre de ce fait une porte d’entrée vers le HPC aux budgets les plus modestes, tout en étant 100% compatible CUDA. Nous aurons très bientôt l’occasion de la mettre à l’épreuve.
Autre annonce produit majeure, Kayla, un mini PC intégré (format mini-ITX) doté d’un Tegra 3 et d’un GPU Kepler spécifique à 192 cœurs. Là, l’objectif est l’implémentation de solutions accélérées en conditions d’environnement difficiles, voire en applications embarquées. On pouvait retrouver dans Kayla un certain nombre de développements déjà commercialisés par l’italien Seco, qui en propose plusieurs déclinaisons matérielles alors que Kayla ne sera pour l’instant disponible qu’en version unique.
Un cluster HPC prêt à l’emploi

Mais c’est véritablement avec GRID VCA que le public HPC de la salle a été le plus impressionné. En reprenant grosso modole même concept que GRID GPU, dédié à la virtualisation de serveurs pour le jeu, GRID VCA (pour Visual Computing Appliance) offre un serveur d’accélération prêt à l’emploi dans un châssis 4U. La encore, les spécialistes auront reconnu, derrière le logo NVIDIA, le serveur FT77A-B7059 de Tyan. L’ensemble est géré par une pile logicielle et un hyperviseur dédiés, compatibles au niveau virtualisation avec Citrix, vmWare et Microsoft, et déjà certifiés par les plus grands noms du monde serveur (IBM, Dell, HP, Cisco…). Disponible en deux versions (8 ou 16 GPU Kepler), Grid VCA est positionné à environ 25 / 40 k$, et nécessitera le paiement annuel d’une licence logicielle de 2,4 / 4,8 k$.
Il est temps maintenant de passer à la revue de détails de ces annonces produits. C’est à elle que nous vous invitons dans la deuxième partie de ce dossier. Mais pour revenir un instant sur cette “keynote” inaugurale, l’impression qu’elle nous a laissé est celle d’une grosse montée en puissance du concept accélération GPU + CUDA, et cela sur des bases solides. Aux deux extrémités de la gamme, des puces mobiles aux plus gros accélérateurs GPU, la cohérence de l’offre est complète. Reste à savoir comment réagira le reste de l’industrie…
More around this topic...










© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}