
Comme chaque année depuis quatre ans maintenant, la keynote de Jen-Hsun Huang est un sinon LE moment phare de la GPU Technology Conference. Dans le même temps, la présentation du patron, qui dévoile une mise à jour majeure de la roadmap “calcul” de la marque, amène aussi son lot de questions. Certes, une roadmap n’engage pas contractuellement le constructeur. Elle donne le cap et une vision technologique soutenable à deux-trois ans. C’est à mesure de son avancement que les détails techniques, notamment pour ce qui concerne l’implémentation, sont précisés.
Et donc, on sait désormais comment s’appellera la prochaine architecture GPU NVIDIA. Cocorico, il s’agit de… “Pascal”, en l’honneur de l’inventeur de la calculatrice mécanique, ce qui n’a pas manqué de surprendre. Dans les rangs – compacts – de l’assistance, certains y ont d’ailleurs vu un certain retard pris sur la roadmap présentée ici même l’an dernier. On s’en était fait l’écho : à l’époque, c’était à Volta que revenait la lourde tâche de succéder à Maxwell. Alors quid de Volta ? Aux dires du management de NVIDIA, à qui nous avons posé la question, cette architecture reste d’actualité mais dans un second temps, Pascal étant à considérer comme un “refresh” de Maxwell. Pour un peu, on s’y perdrait…
Cela dit, peu importe le nom finalement. Ce qui compte, ce sont avant tout les spécifications techniques et les fonctionnalités qui en découlent. Et de ce point de vue, on remarquera que le support de la mémoire unifiée, initialement prévu avec Maxwell, est maintenant décalé à Pascal, c’est-à-dire à 2016. NVIDIA nous a officiellement confirmé que cette avancée majeure ne sera pas dans Maxwell dont la version notebook (gm106) est d’ores et déjà commercialisée et dont la version compute (gm110) sortira probablement au début de l’année prochaine.
En revanche, la mémoire empilée (stacked memory), annoncée avec Volta, est non pas avancée mais bien maintenue avec Pascal. Cette mémoire DRAM superposée au processeur graphique devrait au minimum doubler la bande-passante et donc améliorer substantiellement l’efficacité énergétique. Selon Jen-Hsun Huang, la seule limite à l’espace qui pourra être adjoint au GPU sera le prix que l’on sera prêt à payer. Dans les faits, on devrait disposer d’environ 2,5 fois les capacités standards actuelles (environ 30 Go, donc).
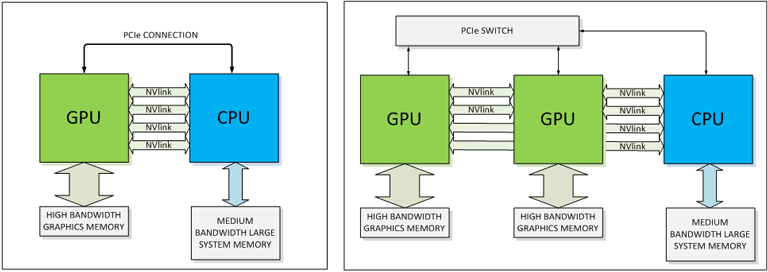
La nouveauté la plus “spectaculaire” présentée cette année reste toutefois NVLink, un bus d’interconnexion point-à-point entre GPU et CPU. Ce bus ne remplacera par PCI Express mais offrira des capacités en bande-passante annoncées comme supérieures de 5 à 12 fois à celles de PCI Express, avec en particulier huit lignes bidirectionnelles à 20 Gb/s chacune. Si le concept est assez prometteur en théorie, reste à savoir comment il s’interconnectera au QPI d’Intel qui, faut-il le rappeler, détient tout de même aujourd’hui l’essentiel des parts de marché serveur. Parierait-on sur le fait que la donne change dans les vingt-quatre prochains mois ? C’est en tout cas la stratégie que semble déployer NVIDIA qui, avec l’annonce en novembre dernier d’une nouvelle collaboration avec IBM visant l’intégration des accélérateurs Tesla dans les serveurs POWER, souhaite ardemment concourir à établir une alternative crédible au x86. Il va d’ailleurs sans dire que POWER et NVLink ont tout pour s’entendre.
Enfin, du côté de l’embarqué et des SoC Tegra, changement de roadmap également, ce qui n’est pas sans une certaine logique. Le successeur de Tegra K1 n’est plus Parker, comme annoncé (encore une fois) l’année dernière, mais Erista qui sortira en 2015 et intègrera dans un même die un GPU Maxwell à 192 cœurs et des cœurs ARM – probablement des quad-cores Cortex-A15 dans un premier temps puis des dual-cores Denver ARMv8 64 bits un peu plus tard. Avec une puissance de 326 Gflops pour une consommation de moins de 10 Watts, ces systèmes peuvent, nous semble-t-il, revendiquer le titre de mini-supercalculateurs. Il ne leur manque plus que le support de la double précision pour figurer parmi les candidats les plus sérieux à la course à l’exascale, d’autant qu’ils sont nativement programmables en CUDA.
More around this topic...









© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}
{kind=link}