
This article is part of our feature story: How CERN manages its data
Every LHC experiment uses a large number of sensors, so the number of interactive data structures is quite significant. Each sensor produces its own raw data, coming directly from the electronic measuring. The problem is that the analyses are typically much higher with regard to the abstraction levels than an elementary change of state. Therefore, complex reconstruction procedures must be executed, which in turn create new data.
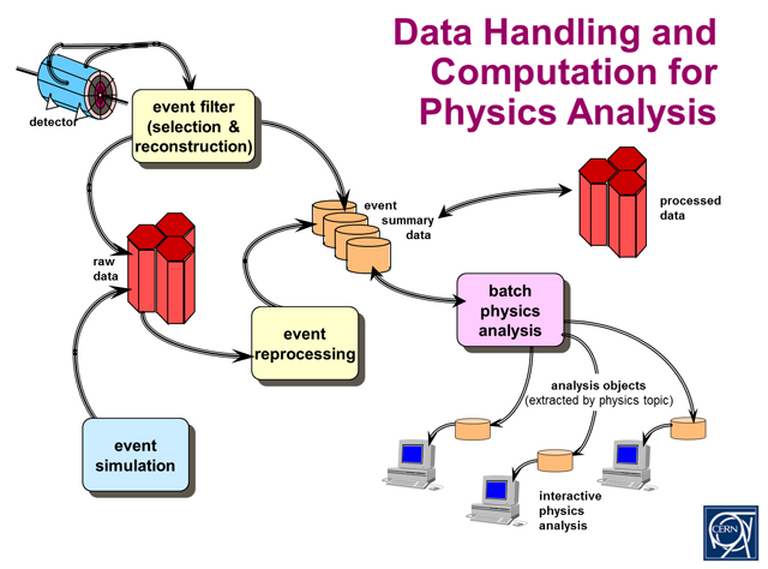
Fig. 1 – A simplified diagram showing one of many different paths for navigating through a network of physics data objects. Here, a specific collision track from the list of all of the available tracks is selected. All the status changes that made it up can be followed. (CERN document)
Considering that the events analyzed (such as the collision of particles, typically) are by principle independent, CERN records one data tree per collision. This tree contains data from all the sensors at different abstraction levels. In practical terms, this is equivalent to thousands of objects of discrete classes offering different types of relationships between them.
The analysis performed after the collection involves navigating through this network of objects from a wide variety of paths. The image below shows one of these paths (very simplified), which is to select a specific track from the list of all of the collision tracks, and then to follow all the status changes that made it up.
 read back
read backMore around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















