
Après 3 ans de loyaux services, après la découverte plus que probable du boson de Higgs, le LHC entame son premier long shutdown. L’occasion idéale pour découvrir comment le CERN relève, au quotidien, le défi du Big Data scientifique…
Ce dossier comprend également les articles suivants :
• Les modèles de données du LHC
• Des chiffres à nul autre pareils
• 100 Po à maintenir
• Un laboratoire unique pour le Big Data
• Focus sur CASTOR, le gestionnaire de stockage du CERN
Au moment où vous lisez ce dossier, plus d’un millier de chercheurs du monde entier travaillent en direct sur les données du LHC (Large Hadron Collider). Si le Centre est universellement reconnu pour son travail d’avant-garde en physique fondamentale, il commence à l’être également pour son infrastructure informatique, et plus particulièrement pour la gestion de ses données expérimentales. Avec une production annuelle qui dépasse les 30 Pétaoctets, le problème n’est pas simple, d’autant que ce trésor d’information a vocation à être partagé sans contrainte de lieu ni d’infrastructure. Le cas du CERN étant à bien des égards emblématique des problèmes de gestion de grosses volumétries que peuvent rencontrer instituts académiques et entreprises privées, il nous a semblé pertinent d’enquêter sur l’affaire. C’est à cette visite guidée que nous vous invitons maintenant.
Big Science > Big Data
“Le plus gros challenge, ici, au département IT du CERN” précise Frédéric Hemmer, son responsable, “c’est évidemment le volume des données, notamment en production.” Ces données, le Centre doit les recueillir, les analyser, les stocker, les protéger et les rendre disponibles à la communauté des chercheurs en mode 24/7. Le choix d’une infrastructure agile (que nous détaillerons ci-dessous) se révèle à cet égard pertinent : à ce jour, le CERN n’a jamais perdu un fichier, toutes causes confondues. Et ce bien que “même lorsque le LHC ne fonctionne pas“, poursuit Frédéric Hemmer, “l’IT ne s’arrête pas. Les analyses sont continues, ici, au Centre, et dans le monde entier.”
Concrètement, le CERN doit anticiper les besoins d’utilisateurs très particuliers, et souvent assez inventifs, qui conduisent des expériences dont les besoins sont techniquement imprédictibles. Ce qui conduit les équipes IT à devoir innover en permanence, avec des contraintes de résultats fortes et un budget de fonctionnement très… constant.
Oracle à tous les étages
En choisissant librement les éléments fondamentaux de sa pile technologique, le CERN veille à respecter un équilibre théorique entre performance, fiabilité et scalabilité. Pour les données, le choix d’une base Oracle a été fait dès 1982 et s’est étendu depuis à toutes les dimensions de l’organisation et du fonctionnement du Centre, des systèmes de contrôle des accélérateurs aux expériences elles-mêmes. Pour les responsables en charge de ces décisions, Oracle répond aux pré-requis en matière de fonctionnalité, de disponibilité, de dimensionnement, et inclut les outils nécessaires à la gestion, la protection et la distribution des données.
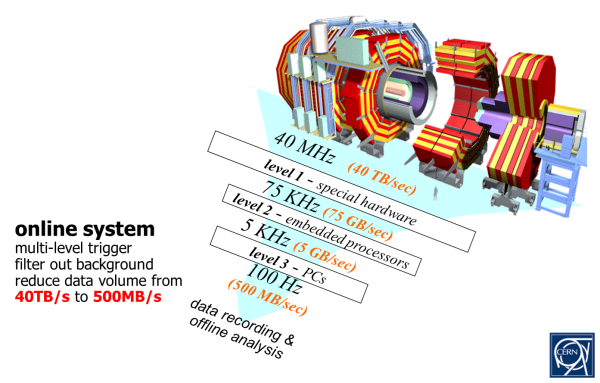
Côté stockage, ce sont les technologies NetApp qui constituent le gros des nouveaux équipements. Pour le constructeur, cette vitrine ne va d’ailleurs pas sans défis techniques. Par exemple, les collisions d’ions lourds (des noyaux de plomb, en l’occurrence), sont des expériences complexes, qui rendent les taux de production d’information très difficiles à estimer par avance. Des taux qui peuvent atteindre 6 Go par seconde. Or, toujours selon Frédéric Hemmer, “les données étant la raison même de notre existence, la mission des équipes IT est multidimensionnelle. Nous devons permettre leur exploitation quasi-immédiate, assurer leur immortalité, gérer les mises à jour matérielles et logicielles en mode non-disruptif, et veiller à ce que l’infrastructure offre un espace virtuellement infini…“
Le LHC dépend de ses SGBD
Si un tel discours est d’ordinaire assez convenu, il faut bien comprendre qu’ici, le moindre problème de recueil ou de gestion de données implique l’arrêt du collisionneur. Techniquement, celui-ci est en effet géré via deux bases. La première ACCCON, stocke les éléments de paramétrage et de contrôle de l’installation. Pour assurer une surveillance permanente du LHC, les opérateurs affinent sa configuration en temps réel via une batterie d’écran regroupés dans une salle dédiée. Pour peu que la base soit indisponible même pendant quelques instants, le collisionneur devient incontrôlable. Il faut donc stopper l’expérience en cours, ce qui implique de faire mourir les faisceaux dans d’énorme blocs de graphite pour disperser leur énergie et protéger l’anneau. Les températures extrêmes sont en effet de nature à endommager les aimants (dont chacun coûte plus d’un million de dollars), ce qui nécessiterait des réparations susceptibles de rendre le LHC indisponible pendant des mois.
La seconde base de données, ACCLOG, enregistre les inputs en provenance des milliers de capteurs qui composent aussi le LHC. C’est elle qui contient les logs à long terme de l’état des aimants et des pièces mobiles, notamment les collimateurs qui protègent les faisceaux en éliminant les particules dispersées. On s’en doute, cette base est la plus large (et celle qui croît le plus vite) parmi l’ensemble des bases du Centre : elle compte aujourd’hui plus de 4,3 trillions de rows. Or, comme elle détermine le calibrage de l’ensemble de l’infrastructure, elle est essentielle au maintien du LHC en ligne.
Une aiguille dans mille bottes de foin
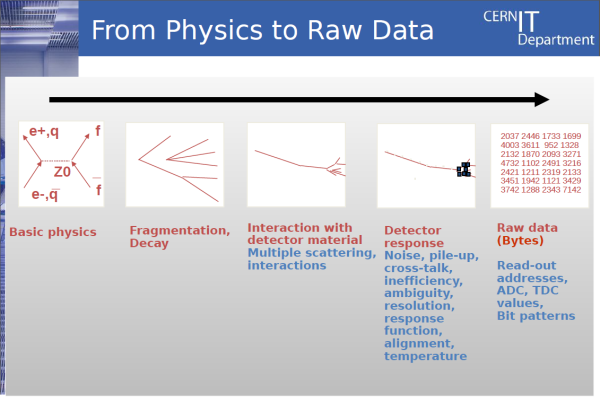
Plaçons-nous maintenant en phase post-expérimentale. Pour l’équipe IT, la mission est d’offrir la meilleure performance d’accès possible aux bases qui indexent les données brutes. Ces dernières sont en effet enregistrées à plat, dans des fichiers ROOT, qui sont ensuite stockés dans un système hiérarchique baptisé CASTOR (voir nos deux encadrés détaillés à ce sujet). Le contexte, mais aussi les traitements, sont donc à peu près identiques à ceux d’une grosse application de Big Data. De plus en plus, pour extraire de l’information pertinente de l’énorme masse de données disponible, on parcourt les datasets à partir d’analyses prédictives.
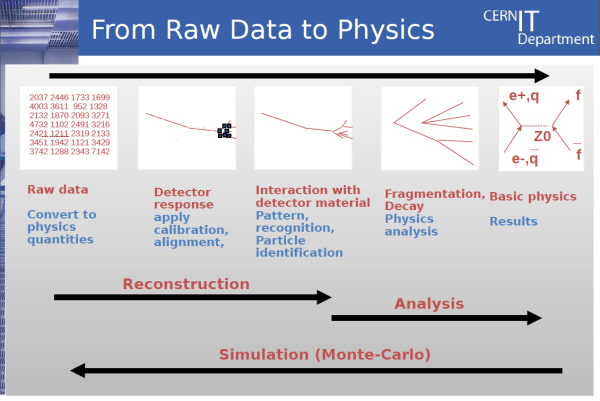
Et donc, concrètement, le système repose sur cinq piliers fonctionnels “critiques“, comme le souligne Eric Grancher, Database Architect dans l’équipe IT.
• Des connexions 10 GbE, une technologie classique à la fois dimensionnable et facile à gérer. Ces connexions permettent d’utiliser les mêmes switches que dans de nombreuses autres installations du Centre, et offrent l’avantage de pouvoir être maintenues par l’équipe Réseau du CERN, qui fournit un support 24/7.
• Le système de fichiers Oracle dNFS, qui offre plusieurs routes de stockage. dNFS a en effet ceci de particulier qu’il court-circuite le système d’exploitation, ce qui se traduit par un niveau de performance à peu près double. Avec un autre avantage de poids : Oracle génère les requêtes NFS directement depuis les bases de données. De ce fait, le système n’a quasiment pas à être configuré ni maintenu.
• Des disques SATA couplés à une technologie de cache spécifique qui offrent une niveau de performance comparable à celui des disques FC pour une fraction du coût de ces derniers. Compte tenu du nombre de disques utilisés au CERN (plus de 64 000, voir notre encadré Des chiffres à nul autre pareils), l’aspect coût est ici déterminant.
• Une technologie de clonage de volumes instantanée, qui permet la création à la volée de copies de datasets modifiables. Cette technologie, baptisée FlexClone, est également d’origine NetApp. L’aspect instantané offre ici un second bénéfice : quel que soit le nombre d’équipes scientifiques travaillant sur un dataset, aucune donnée n’est dupliquée.
• Enfin, le système NetApp ONTAP 8, qui rend possible l’ajout de baies de stockage et le déplacement de données à chaud, sans interruption des expériences en cours. Cette continuité permanente est un des points forts de l’infrastructure car elle équivaut à une disponibilité maximale, le mode cluster permettant quant à lui de pourvoir à tous les besoins de dimensionnement.
Au départ, le choix d’une architecture de type NAS avec disques SATA en RAID 1 pouvait paraître surprenant par rapport à l’option SAN FC plus classique. Pourtant, après plusieurs années d’utilisation intensive, les statistiques parlent (par la voix d’Eric Grancher) : “Depuis 2007, nous n’avons eu aucun downtime lié aux disques SATA, nous n’avons pas perdu un seul bloc de données. Clairement, la fiabilité est aussi bonne qu’en technologie FC.“
Au terme de ce premier parcours, une conclusion s’impose : les technologies actuelles permettent de gérer les données les plus complexes, et les volumes les plus énormes. Si le cas du CERN représente le paroxysme du Big Data scientifique, la voie tracée n’est certainement pas la seule possible. Mais elle a le mérite de l’efficacité, une efficacité saluée par l’ensemble des chercheurs qui ont eu le privilège de la mettre en pratique. Certains points abordés pendant la visite nous ont paru mériter d’être nettement approfondis. C’est le rôle des encadrés qui émaillent ce dossier.
Un grand nombre de détecteurs étant mobilisé pour chaque expérience conduite au LHC, le nombre de structures de données en interaction est assez important. Chaque détecteur produit ses propres données brutes, issues directement de l’électronique de mesure. Le problème, c’est que les analyses portent typiquement sur des niveaux d’abstraction beaucoup plus élevés qu’un changement d’état élémentaire. Par conséquent, des procédures de reconstruction complexes doivent être exécutées, qui à leur tour créent de nouvelles données.
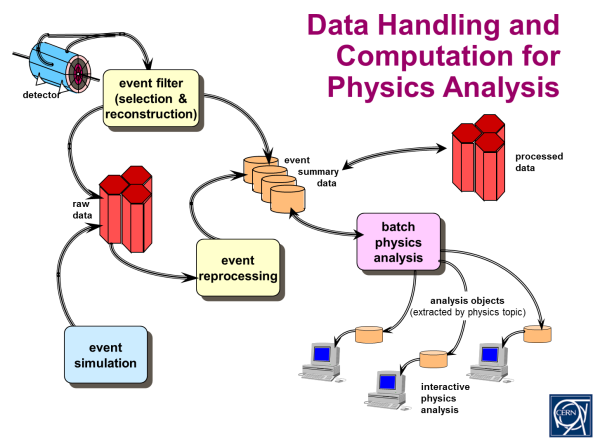
Dans la mesure où les différents événements (des collisions de particules, typiquement) sont en principe indépendants, on aboutit à une arborescence de données par collision. Cette arborescence contient les données de tous les détecteurs aux différents niveaux d’abstraction. Ce qui équivaut concrètement à des milliers d’objets de classes discrètes offrant différents types de liens entre eux.
L’analyse pratiquée après collecte consiste à naviguer à travers ce réseau d’objets à partir d’une large variété de voies d’accès. L’infographie ci-dessus montre une de ces voies (très simplifiée), qui consiste à sélectionner une piste spécifique à partir de la liste de toutes les pistes d’une collision, puis à suivre tous les changements d’état qui l’ont constituée.
Des chiffres à nul autre pareils
- 2 500 employés
- 10 000+ chercheurs et étudiants
- 608 universités
- 113 nationalités
- 828 racks
- 11 728 serveurs
- 15 694 processeurs
- 64 238 cœurs
- 56 014 modules mémoire
- 158 TiB* de capacité mémoire
- 64 109 disques
- 63 289 TiB* de capacité disque brute
- 3 749 contrôleurs RAID
- 1 800 pannes disques / an
- 160 lecteurs de bandes
- 45 000 cartouches
- 56 000 slots cartouches
- 73 000 TiB* de capacité bande
- 24 routeurs haute vitesse (640 Mbps – 2,4 Tbps)
- 350 switches Ethernet
- 2 000 ports 10 Gbps
- 2,4556 MW (consommation IT)
- 120 MW (consommation LHC)
* 1 TiB (tebibyte) = 2^40 soit 1 099 511 627 776 octets, soit 1024 gibibytes.
Un laboratoire unique pour le Big Data
Les recherches menées au CERN ont des implications qui vont bien au-delà de la physique fondamentale. Rappelez-vous, en 1989 : c’est un chercheur de Centre, Tim Berners-Lee, qui a inventé le World Wide Web pour permettre le partage d’information distant entre scientifiques. Plus récemment, la domestication de l’accélération des particules a donné naissance aux PET scans qu’on trouve dans un nombre croissant d’hôpitaux, mais également aux équipements de détection des matériaux nucléaires aux frontières.
Aujourd’hui, compte tenu du volume de données produites par les différentes installations du Centre, c’est (aussi) dans le domaine de la gestion du Big Data que le CERN fait figure de pionnier. Ce dossier ne manque pas de chiffres, mais s’il fallait n’en retenir qu’un, ce serait les 25 Po de données exploitables produites l’année dernière – et ce après que 99 % des informations issues des détecteurs du LHC n’aient pas été jugées suffisamment intéressantes pour être stockées.
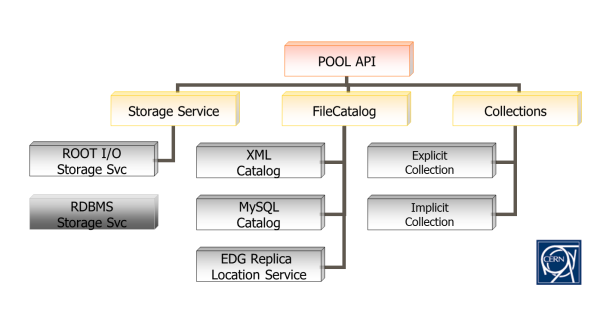
Le CERN ouvre sa bibliothèque d’information à des chercheurs répartis sur environ 150 sites de par le monde. Pour réussir ce tour de force, les données expérimentales brutes ne sont évidemment pas stockées dans un SGBD relationnel. Elles résident dans des fichiers ROOT, particulièrement bien adaptés à l’analyse scientifique grâce à leur modèle de cohérence unique (write once), tandis que la persistance est gérée par un framework “maison” baptisé POOL (Pool of Persistent Objects for LHC). Ce sont les métadonnées sur ce thésaurus qui sont gérées via une base Oracle 11gR2, et donc en cohérence transactionnelle.
Typiquement, les données brutes du CERN sont analysées par batches. Or, chacun sait que ce type de traitement peut vite devenir chronophage. Les data scientists du Centre étudient donc plusieurs moyens d’optimiser non seulement les accès mais aussi les requêtes. Ils travaillent pour cela avec différents grands noms de l’industrie (Intel, HP, Oracle…), dans le cadre du projet openlab (FP7). L’objectif, clairement, c’est d’accélérer la vitesse de traitement des données, pour qu’elle corrèle avec l’augmentation des volumes de production.
Parmi les voies étudiées, les technologies NoSQL telles que Hadoop ou le SGBD Dynamo d’Amazon paraissent les plus prometteuses. A cela, trois raisons. Primo, parce qu’elles se dimensionnent particulièrement bien, notamment en termes de répartition sur un grand nombre de clusters. Secundo, parce que, ce faisant, elles évitent d’avoir à gérer la montée en complexité inhérente aux bases relationnelles. Tertio, parce qu’elles se prêtent parfaitement au stockage sur des commodity servers – les équipements standards ayant toujours eu la faveur des responsables IT du CERN.
Globalement, les travaux en sont aujourd’hui au développement de procédures permettant d’utiliser les liens dans les bases Oracle pour extraire de l’information pertinente, la traiter en mode Hadoop ou en business intelligence pure (comme le font les entreprises depuis longtemps) puis la replacer dans d’autres bases Oracle. Revenir ainsi sur Oracle a plusieurs avantages, notamment la solidité du système, ses possibilités fonctionnelles propres et le fait qu’il soit universellement connu et maîtrisé. Quant à ses défauts les plus souvent cités, notamment les capacités de traitement et de stockage requises, le CERN ne les considère pas comme un obstacle rédhibitoire. Dans l’optique (relativement) proche de l’exascale et compte tenu de la réduction des coûts de stockage en cloud spécialisé, le bénéfice en utilisabilité paraît défendable.
N’oublions pas non plus que le gros de l’analyse des données issues du LHC est réalisé par un réseau mondial comptant plus de 150 centres de calcul (Worldwide LHC Computing Grid – WCLG), eux-mêmes en constante augmentation de capacités. Si l’on ajoute à cela un budget consacré à l’utilisation de services cloud tels qu’Amazon S3, la stratégie prend tout son sens. Une chose est claire : on sait qu’un des principaux goulets d’étranglement pour le passage à l’échelle est la rapidité avec laquelle les données pourront être déplacées de serveurs en serveurs. A ce titre, la recherche de gains de temps et de fonctionnalités en traitement in situ bénéficiera probablement à l’ensemble de la communauté.
Ces trois dernières années seulement, le volume de données issues du LHC a atteint 75 Po, ce qui porte le volume global des données produites par le CERN à un peu plus de 100 Po. A cette échelle, le stockage est une expérience en soi. La stratégie des responsables IT du Centre a consisté à caractériser l’information en fonction de ses probabilités d’accès. Ainsi, 88 Po sont archivés sur bande via le CERN Advanced Storage system (CASTOR), tandis qu’environ 13 Po sont stockés sur un système à disque (EOS) optimisé pour des analyses rapides et simultanées par plusieurs utilisateurs.
C’est quand on aborde l’aspect logistique que ces ordres de grandeur prennent toute leur signification. Le CERN dispose ainsi de huit bibliothèques de bandes robotisées, réparties sur deux bâtiments. Chacune de ces bibliothèques contient à peu près 14 000 cartouches offrant des capacités unitaires variant de 1 à 5,5 To. Le système EOS, lui, se compose de 17 000 disques attachés à environ 800 serveurs, l’ensemble bénéficiant d’un namespace unifié permettant les accès concurrents à des millions de fichiers.
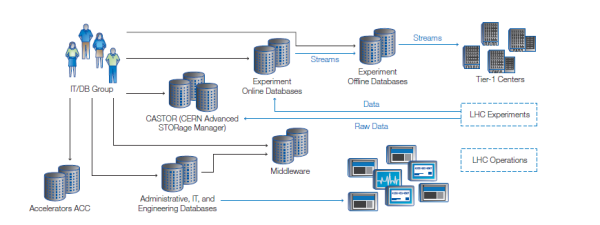
L’équipe IT va profiter du premier long shutdown (LS1) du LHC pour analyser l’état de santé de son trésor de données et mener un certain nombre d’opérations de consolidation et de maintenance sur celui-ci. Par exemple, les bandes vont être répliquées sur des cartouches offrant de plus importantes capacités individuelles. Dans le même temps, les ingénieurs doivent préparer l’arrivée des nouveaux flux de données que produiront les accélérateurs mis à jour. Pour cela, les infrastructures du Centre vont être étendues et un nouveau datacenter distant, situé à Budapest (Hongrie), est en cours de création. Son cluster devrait embarquer 20 000 cœurs, offrir une capacité de stockage propre de 5,5 Po et être interconnecté avec Genève via un réseau 200 Gbps dédié.
Focus sur CASTOR, le gestionnaire de stockage du CERN
Pour assurer la globalité de ses besoins en persistance et en accès, le CERN a développé son propre système de gestion de stockage hiérarchique, baptisé CASTOR (CERN Advanced STORage manager). L’idée de départ était de permettre aux chercheurs du monde entier d’enregistrer, de lister et de retrouver les fichiers à partir d’outils en ligne de commandes ou d’applicatifs utilisant une API maison unique. Principe de base de CASTOR, on accède toujours aux fichiers à partir de cache disques. C’est le back-end du système qui assure leur conservation sur bande. Et pour faciliter la vie des chercheurs, de multiples protocoles d’accès sont disponibles : RFIO, ROOT, XROOT et GridFTP.
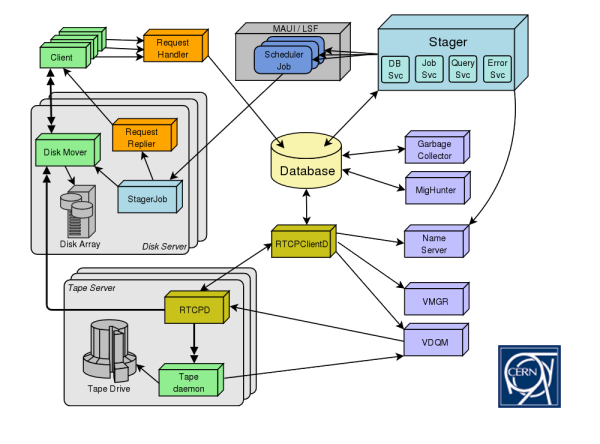
Au cœur de l’architecture de CASTOR, une base de données centrale sauvegarde les changements d’états des composants. Grosso modo, cette architecture se décompose en cinq modules fonctionnels :
• un stager alloue et récupère l’espace de stockage, contrôle l’accès client et gère le catalogue des grappes de disques locales.
• un serveur de noms (fichiers et dossiers) inclut les métadonnées fichiers (taille, dates, checksums, propriétaire, informations de copie sur bande). Des utilitaires en ligne de commande copiés sur le modèle Unix permettent de manipuler l’espace de nom.
• l’infrastructure bande assure la copie de fichiers sous certaines circonstances, en particulier pour assurer la sécurité des données et permettre le stockage de fichiers plus volumineux que la capacité disque immédiatement disponible.
• un logiciel client permet à l’utilisateur de télécharger (dans les deux sens) et de gérer des données CASTOR.
• le Storage Resources Management System autorise l’accès aux données dans un environnement grid via son propre protocole. Il interagit avec CASTOR pour le compte d’un utilisateur ou d’autres services tels que FTS (le système de transfert de fichiers utilisé par la communauté LHC pour exporter des données).
Pour maximiser l’efficacité du stockage, CASTOR utilise en priorité de larges fichiers (1 Go minimum). Pour les contenants plus petits et/ou non-expérimentaux, les utilisateurs sont invités à utiliser AFS, un système de fichiers distribué plus classique. Typiquement, un fichier stocké via CASTOR sera copié sur bande en moins de 24 heures (8 heures pour les données de physique expérimentale). Les instances disques sont ensuite effacées de façon asynchrone.
Au moment de recharger des données à partir d’une bande, les délais peuvent varier. Le temps moyen est d’environ quatre heures. Les applications ayant besoin de ces données patientent entre la requête et la bonne fin de son exécution, puis démarrent automatiquement leur traitement après celle-ci. Il est toutefois fréquent que des requêtes préalables soient lancées qui permettent de “monter” les données sur disque avant leur téléchargement. Notez enfin que chaque groupe de chercheurs / d’expériences se voit attribuer des SLA qui déterminent précisément les stratégies de stockage propres aux travaux menés.
More around this topic...









© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















