
Gilles Grasseau, Ecole Polytechnique, Laboratoire Leprince-Ringuet, IN2P3 ;
Pierre-François Lavallée, IDRIS.
(Cet article fait partie de notre dossier JDEV 2013 : Développer pour calculer)
Alliant les modèles de programmation en mémoire distribuée (MPI) et partagée (OpenMP), le calcul parallèle hybride s’est imposé comme une valeur sure pour exploiter efficacement les calculateurs les plus puissants, et cela tant du point de vue de la performance que de la consommation mémoire. Ses possibilités s’accompagnent toutefois de certaines contraintes : à l’évidence, son implémentation doit être très soigneuse. Il s’agit en effet d’éviter toute synchronisation trop forte entre les processus légers.
De même, il peut être crucial de s’intéresser à la granularité de la répartition des tâches en mémoire partagée (OpenMP). A ce titre, une stratégie de distribution du travail en mémoire partagée d’un domaine MPI en sous-domaines OpenMP peut s’avérer plus efficace qu’une approche laissant OpenMP répartir seul le travail à l’intérieur du domaine MPI. C’est ce que nous avons montré au cours de notre atelier, à partir du code de CFD Hydro (cf. Figs. 1 et 2) qui résout les équations d’Euler compressibles de l’hydrodynamique en 2D.

Fig. 1 – Simulation d’une explosion de Sedov avec la version hybride du code Hydro sur la machine ‘IBM BG/Q’ de l’IDRIS (65536 cœurs, 262144 threads d’exécution).
Les accélérateurs de calculs étant des dispositifs de plus en plus courants dans les centres de calculs (tant au niveau mondial que national ou européen), il nous est apparu indispensable de les prendre en compte dans l’analyse de notre problématique. Pour cela, deux axes ont été privilégiés. Le premier concerne la recherche de performance par l’exploitation de toutes les ressources de calcul – c’est-à-dire les accélérateurs mais aussi, bien qu’ils offrent une moindre puissance de calcul, les cœurs des CPU. Le second concerne la portabilité, objectif qui nous a paru important compte tenu de la diversité des accélérateurs disponibles sur le marché.
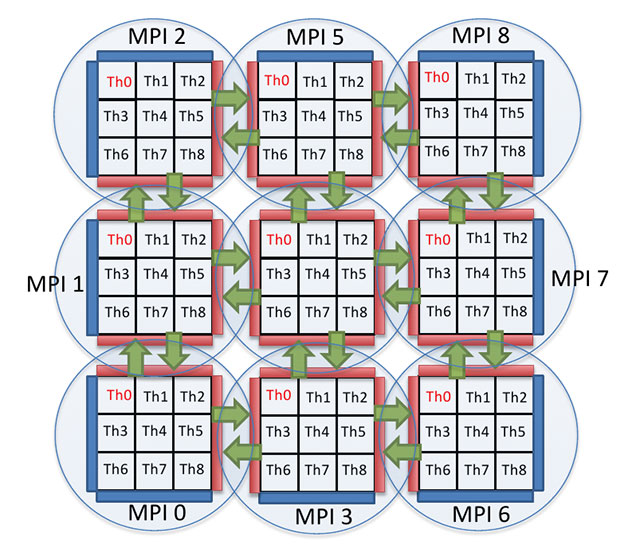
Fig. 2 – Illustration de l’approche hybride : décomposition en domaines MPI puis en sous-domaines OpenMP. Le traitement effectué aux interfaces entre les domaines diffère en fonction de leur couleur : (bleu) conditions limites de l’écoulement, (rouge) pseudo-condition limite de mise à jour des domaines voisins.
Ces deux axes nous ont amené à choisir le modèle de programmation CPU. Profitant de la décomposition en sous-domaines, nous avons sous-traité une fraction de ces sous-domaines aux accélérateurs, la performance optimale étant atteinte en ajustant cette fraction. Sur le code Hydro, étendu de l’implémentation OpenCL, nous avons mis en évidence cette valeur cumulant de façon optimale la puissance des cœurs et celle des accélérateurs.
Nous aimerions, pour conclure ce bref compte-rendu, attirer l’attention sur le point clé qu’est la gestion des interfaces entre les différents domaines de cette architecture à trois niveaux. Dans le code Hydro, cette gestion possède toutes les bonnes propriétés : unicité du traitement, gestion de la hiérarchie des domaines (domaines MPI, sous-domaines OpenMP) et l’extensibilité (ajout sans grandes difficultés de sous-domaines OpenCL)
Pour aller plus loin : http://devlog.cnrs.fr/jdev2013/t7a1
(Dossier JDEV 2013 : Développer pour calculer : article précédent | suivant)
More around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















