
Comment sont alloués les ressources et le temps de calcul de Stampede aux scientifiques ?
Stampede étant financé par la NSF, 90 % du temps de calcul lui est attribué, dans le cadre du programme XSEDE qui fournit des services partagés aux centres de calculs des États-Unis. XSEDE est géré par un comité d’attribution, un groupe d’experts qui se réunit une fois par trimestre. C’est au travers d’XSEDE que les demandeurs font leur proposition d’allocation. Notre mesure, appelée “unité de service” est basée sur des unités horaires d’allocation d’un cœur Xeon. Comme nous avons 16 cœurs dans un Xeon sur un nœud, une heure de temps de nœud correspond à 16 unités de service.
Nous proposons environ 800 000 000 unités de service au travers du programme XSEDE dont 20 à 25 000 000 vont aux start-ups, c’est-à-dire à de nouveaux utilisateurs qui ne passent pas par le comité d’attribution mais qui reçoivent une allocation de démarrage pour leur projet. Environ 175 000 000 unités sont attribuées par le comité aux grands utilisateurs pour la recherche académique. Nous recevons quelques centaines de nouvelles propositions chaque trimestre. La demande est environ cinq fois supérieure à ce que nous pouvons fournir. Ce dernier trimestre, nous avons reçu des demandes représentant un peu plus d’un milliard d’heures et cela devrait continuer à croître.
Pouvez-vous décrire un ou deux projets scientifiques actuellement en cours sur Stampede ?
Nous avons beaucoup de projets à grande échelle dont quelques-uns utilisent véritablement Xeon Phi. Citons par exemple le groupe de Klaus Schulten à l’Université d’Illinois à Urbana-Champaign, qui réalise des simulations de dynamique moléculaire sur des biomolécules. Ils utilisent Stampede comme un microscope afin de mieux comprendre des problèmes fondamentaux comme le repliement des protéines lors de leur conception, et tentent de créer de nouvelles enzymes pour la production de biocarburants de deuxième génération.
C’est cette équipe qui produit NAMD (North American Molecular Dynamics), code très connu dans la communauté. Nous avons obtenu de bons résultats avec ce code exécuté sur Xeon Phi pour la résolution de problèmes de grande taille. L’équipe est maintenant en train d’étudier les retombées dans le domaine de la vaccination.
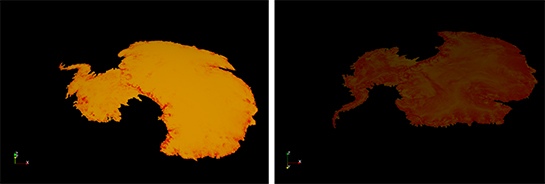
Il y a aussi un projet de géophysique mené par George Biros et Omar Ghattas à l’Université du Texas à Austin. Leur code passe l’échelle de milliers de Xeon Phi pour environ 60 % de la performance crête de Stampede. Ce code est à la base d’un certain nombre de problèmes scientifiques et, tout récemment encore, ils l’ont utilisé pour modéliser la calotte glaciaire. Il s’agissait d’étudier son mouvement sur les pôles, pour savoir comment la glace se déplace, accélère ou ralentit – c’est-à-dire, en d’autres termes, en simulant la dynamique de ces mouvements.
Comment est organisé le support aux utilisateurs en termes de formation, d’expertise et d’optimisation de code ?
Une partie des formations et du support aux utilisateurs est financée directement par le projet Stampede, une autre l’est par XSEDE. Certaines personnes ici et d’autres basées ailleurs participent à ce support. Nous offrons plusieurs niveaux de formation avec des cours traditionnels et d’autres en webcast. Nous offrons également des formations en ligne avec notre partenaire, l’Université de Cornell. Ce Cornell Virtual Workshop permet de suivre une formation en ligne à n’importe quel moment. L’année dernière, nous avons réalisé environ 35 formations directement liées à Stampede mais aussi plus généralement sur certains aspects du parallélisme et de visualisation avec Stampede. La moitié de ces formations était des webcasts.
Nous animons également des tutoriels lors des grandes conférences telles que SC ou ISC. L’année dernière, toujours, près de 2 000 utilisateurs ont suivi nos formations traditionnelles ou par l’intermédiaire du webcast, et environ 10 000 autres ont suivi nos formations en ligne. Nous essayons d’atteindre un grand nombre d’utilisateurs par ces divers moyens.
En ce qui concerne le support au travers de XSEDE, nous proposons un service helpdesk 24/24 et un système par tickets. Un grand nombre de personnes du groupe HPC passent une bonne partie de leur temps à résoudre ces tickets. Je dois également citer l’ECSS (Extended Collaborative Support Service), un service financé par XSEDE au travers duquel nous assignons un de nos experts à une équipe d’utilisateurs. Ce service peut être demandé par les utilisateurs eux-mêmes lorsqu’ils font une requête en ressource de calcul sur Stampede. Mais il arrive qu’un utilisateur dépose un ticket pour un problème de performance et que nous découvrions finalement que les E/S ou les accès au système de fichiers dans le code nécessitent d’être restructurés. Nous assignons alors une personne à mi-temps sur une période de un à six mois. Un petit projet peut représenter 10 % du temps de travail d’une personne sur un mois tandis qu’un gros projet peut représenter une demie année-homme, ce qui est généralement le cas pour la restructuration des codes. A TACC, entre le projet Stampede et le programme XSEDE, l’équivalent d’environ dix personnes à temps plein assurent le support et la restructuration des codes pour l’utilisation de Xeon Phi ou la visualisation à l’échelle pétaflopique.
Quel est le profil des personnes qui assurent le support ?
La plupart viennent soit du groupe HPC soit du groupe Data Intensive. Les personnes que nous recrutons n’ont pas nécessairement un profil d’ingénieur informatique, elles viennent de différentes disciplines scientifiques. Nous avons par exemple des ingénieurs en aérospatiale, en chimie quantique, en astrophysique ou en biologie, en tout une dizaine de PhDs issus d’une dizaine de disciplines scientifiques. Ils travaillent principalement sur des problématiques de calcul mais possèdent les fondamentaux nécessaires dans les disciplines concernées. Ce mélange de savoir-faire est indispensable pour bien communiquer avec les scientifiques. Nous avons des personnes expertes dans la simulation de réacteurs nucléaires, d’autres dans l’exploration des réserves pétrolières et la modélisation sismique. Nous essayons d’affecter la bonne personne au bon projet mais, bien sûr, tout le monde finit par faire du support dans son domaine d’excellence. Posséder de solides compétences en sciences et en ingénierie avec de bonnes méthodes numériques facilite grandement l’avancée des projets.
Stampede est en production depuis plus d’un an maintenant. Quelle est la feuille de route concernant son évolution ?
Comme vous le mentionnez, Stampede a démarré en janvier 2013. Sa durée de vie prévue est d’environ quatre années, ce qui nous amène à 2017. Nous ferons une mise à jour lorsque la deuxième génération de Xeon Phi sera disponible, l’année prochaine ou au début 2016. Courant 2017, nous concourrons pour Stampede-2, un tout nouveau système. Cette machine et ses caractéristiques dépendront du bilan du système actuel et du financement disponible.
Dans le même ordre d’idée, quelle est votre vision sur le prochain supercalculateur de TACC ?
Nous opérons plusieurs calculateurs au sein de TACC. Le prochain, Wrangler, sera disponible à l’automne de cette année. Il s’agira d’un système différent de Stampede, avec des capacités complémentaires. Il sera dédié aux grandes applications Big Data avec un important composant flash pour des E/S à 1 To/s. C’est un système bien plus petit que Stampede en termes de nombre de processeurs mais avec beaucoup plus de capacités d’entrées/sorties. Nous serons en mesure de transférer les données à travers un nœud à une vitesse environ 400 fois plus élevée qu’avec Stampede. Stampede possède un incroyable système de fichiers mais souffre de débits limités à 150 Go/s. Wrangler sera constitué d’une centaine de nœud mais avec des performances atteignant 1 To/s, mieux adaptées aux petites transactions. Nous avons conçu Stampede pour de gros volumes E/S, de gros fichiers et de larges programmes MPI. Wrangler supportera quant à lui le framework Hadoop et d’autres choses de ce type.
Lorsque Stampede-2 sera sur le point de remplacer Stampede en 2017-2018, nous serons en mesure de voir comment, comparativement, Wrangler se comporte avec les applications Big Data. On sera alors dans un contexte de transition des machines basées sur des accélérateurs PCI vers des machines à accélération intégrée. La difficulté sera de trouver le bon équilibre entre des nœuds accélérés mais autonomes et des nœuds plus traditionnels, tout simplement parce que nous voulons continuer à supporter un large éventail d’utilisateurs et les aider à exécuter leurs programmes dans leurs différents domaines scientifiques.
Pensez-vous personnellement qu’une première génération de machines exascale puisse être scientifiquement opérationnelle en 2020 ?
Oui. Sachant que la première machine téraflopique, c’était 1998 et la première machine pétaflopique 2008, on pourrait avoir une machine exaflopique plus tôt, vers 2018. Je suis relativement confiant dans le fait qu’un système aura des performances crête de l’ordre de l’exaflops en 2020. Mais la vraie question est de savoir comment cette machine sera utilisable. On atteindra l’exaflops au Linpack dans ce laps de temps mais la machine en question sera-t-elle aussi équilibrée, aussi bonne pour la science que les systèmes pétaflopiques que nous avons actuellement ? Toute la question est là. Il y a en tous cas encore beaucoup de travail à accomplir. On verra par ailleurs les benchmarks évoluer afin de mesurer plus correctement la performance de cet équilibre. Cet effort est déjà en cours de réalisation et je ne suis pas certain que nous nous utiliserons encore Linpack d’ici-là.
Quels sont à votre avis les principales difficultés à surmonter, en termes matériels et logiciels, pour la mise au point de la prochaine génération de machines hautement parallèles ?
Le défi logiciel est probablement le plus important. C’est ce que nous observons aujourd’hui avec Xeon Phi ou avec les GPU : il faut extraire plus de parallélisme du code. A chaque nouvelle génération, on a affirmé que les défis étaient à la fois dans le matériel et dans le logiciel mais, en vérité, la plupart des avancées ayant conduit au passage de l’échelle Téra à l’échelle Péta ont été d’ordre matériel. En 1998, les codes étaient essentiellement des codes MPI à mémoire distribuée écrits en C ou FORTRAN. En 2008, les mêmes codes MPI avec quelques améliorations étaient capables de passer au niveau pétafloplique. Tout cela est normal car le cycle de vie du logiciel a longtemps été comparé à la durée de vie du matériel. Le problème, aujourd’hui, c’est que nous devons vectoriser les codes. Tout ce parallélisme n’est plus une option maintenant.
L’exascale, ce sera également des codes MPI et OpenMP. Ces codes existent, ils sont déjà écrits et ne seront pas totalement réécrits dans les cinq prochaines années. Mais le travail que nous réalisons aujourd’hui avec les GPU ou le Xeon Phi pour vectoriser les codes et y accroître le nombre de threads sera bénéfique pour le passage à l’échelle. Les codes qui ignoreront ces niveaux de parallélisme ne bénéficieront que d’une fraction, toujours plus petite, de la performance crête des machines. Nous constatons déjà que les codes les moins bien écrits ne sont pas parfaitement parallélisables et atteignent moins de 1 % de la performance crête des machines.
Du point de vue matériel, nous sommes déjà clairement sur le chemin de l’exascale. Nous nous débarrasserons bientôt des cartes PCI pour tout placer sur la carte mère et nous continuerons d’améliorer la performance avec plus de concurrence sur chacun des nœuds Nous aurons ainsi des centaines de milliers de threads par nœud. La question sera alors de savoir si nous pourrons tirer profit de tout ce parallélisme dans le logiciel afin de justifier les énormes investissements dans les calculateurs…
More around this topic...









© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















{kind=link}
{kind=link}