
Intel introduced Scalable Systems Framework (Intel SSF) to help customers purchase the right technological mix to solve their computational problems. Intel SSF provides a common framework that can support workloads running on everything from small workgroup clusters to the world’s largest supercomputers and on-demand cloud computing.
Training deep learning neural networks (and generally both machine learning and other data analytic algorithms) is a computationally intense workload that stresses all aspects of machine design from floating-point performance, to memory bandwidth and capacity, to message latency and network bandwidth. Data preprocessing and big data also exposes any scalability and performance limitations of the underlying storage and data management system.
Computational systems that can meet all aspects of the machine-learning life cycle tend to perform well on a wide-variety of computational workloads due to their balanced nature [1]. In short, they are not knife-edge performance application accelerators but rather balanced systems that can deliver high performance over a variety of workloads, which makes Intel SSF systems attractive to a wide-variety of commercial and scientific users.
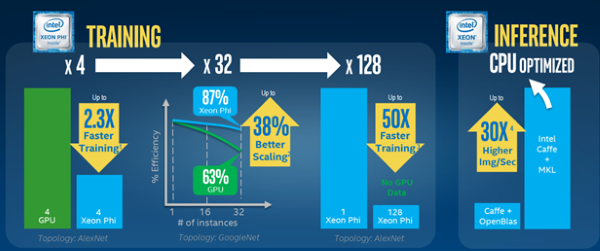
As shown below, Intel announcements at ISC’16 highlighted the success of the Intel SSF technologies over GPUs in terms of scalability and performance when addressing customer challenges in deep learning.
Benchmarks and customer success stories demonstrate that Intel SSF technologies deliver high-performance on a variety of compute- and data-intensive workloads including machine learning. Further, these technologies are starting to replace other traditionally “GPU-only” workloads such as big data visualization of the brain [2] and massive cosmology data sets [3]. Thus Intel SSF is not a “one-trick pony”. In fact, Intel announced at ISC’16 that the Intel SSF ecosystem has grown to 31 partners (19 system providers and 12 independent software vendors). Ultimately, Intel SSF will lead to a broad application catalog of tested HPC apps that will run well on many Intel SSF configurations – including deep and machine learning. More information can be found at intel.com/ssfconfigurations.
Floating-point performance
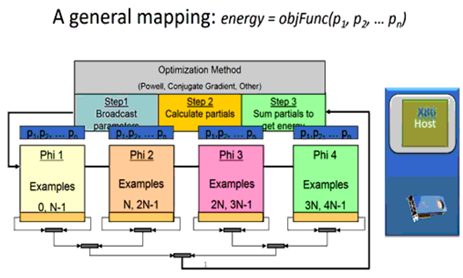
Training Deep-learning algorithms is floating-point intensive as the error on a user provided data set (e.g. the training data) is constantly being reevaluated by an optimization method. The following illustration shows this floating-point intensive optimization by the massively-parallel method of Farber [4].
Computational nodes based on the new Intel Xeon Phi processors (which are part of Intel SSF) can greatly increase floating-point performance to speed training while on package MCDRAM greatly increases memory bandwidth [5] to increase efficiency. In particular, each Intel Xeon Phi processor contains up to seventy two (72) processing cores where each core contains two Intel AVX-512 vector processing units. The increased floating-point capability benefits computationally intensive deep-learning neural network applications.
Software and Customer Feedback are key
Kyoto University (an Intel customer) demonstrated that modern multicore processing technology now matches or exceeds GPU machine-learning performance, but equivalently optimized software is required to perform a fair benchmark comparison. For historical reasons, many software packages like Theano lacked optimized multicore code as all the open source effort had been put into optimizing the GPU code paths.
Two Kyoto benchmarks are shown below. These benchmarks demonstrate that a dual-socket Intel Xeon processor E5 (formerly known as Haswell) can outperform an NVIDIA K40 GPU on a large Deep Belief Network (DBN) benchmark implemented via the popular Theano machine-learning package. The key message in the first figure is the speedup achieved by code optimization (the two middle bars) for two problem sizes over unoptimized code (leftmost pair of bars). The rightmost pair of bars shows that an Intel Xeon processor outperforms an NVIDIA K40 GPU when running the optimized version. It is expected that the newest Intel Xeon Phi processors will deliver significantly faster performance than the Intel Xeon E5-2699 v3 CPU chipset. The second figure shows both performance and capacity improvements.
More around this topic...








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}