
Xinmin Tian, Intel Corporation
Bronis R. de Supinski, Lawrence Livermore National Laboratory
OpenMP Architecture Review Board (ARB)
Abstract — Modern CPU and GPU processors with on-die integration of SIMD execution units for achieving higher performance and power efficiency have posed challenges to use the underlying SIMD hardware (or VPUs, Vector Processing Unit) effectively. Wide vector registers and SIMD instructions – Single Instructions operating on Multiple Data elements packed in wide registers such as AltiVec [2], SSE, AVX [10] and MIC [9] – pose a compilation challenge that is greatly eased through programmer hints. While many applications implemented using OpenMP [13, 17], a widely accepted industry standard for exploiting thread-level parallelism, to leverage the full potential of today’s multi-core architectures, no industry standard has offered any means to express SIMD parallelism. Instead, each compiler vendor has provided its own vendor-specific hints for exploiting vector parallelism, or programmers relied on the compiler’s automatic vectorization capability, which is known to be limited due to many compile-time unknown program factors.
To alleviate the situation for programmers, the OpenMP language committee added SIMD constructs to OpenMP to support vector-level parallelism. These new constructs provide a standardized set of SIMD constructs for programmers who no longer need to use non-portable, vendor-specific vectorization intrinsics or directives. In addition, these SIMD constructs provide additional knowledge about the code structure to the compiler and allow for a better vectorization that blends well with parallelization. To the best of our knowledge, the OpenMP 4.0 specification is the first industry standard that includes explicit vector programming constructs for programmers.
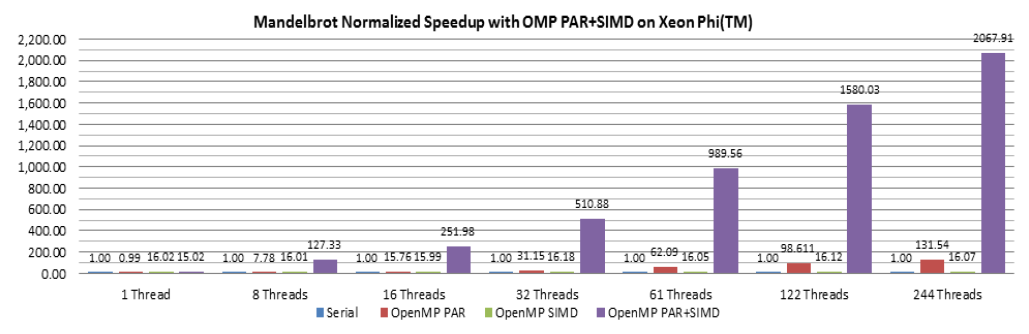
This paper describes the C/C++ and Fortran SIMD extensions for explicit vector programming available in the OpenMP 4.0 specification. We explain the semantics of SIMD constructs and clauses with simple examples. In addition, a set of explicit vector programming guidelines and programming examples are provided in Section 3 and 4 to help programmers to write efficient SIMD programs for achieving a higher performance. Section 5 presents a case study of achieving a ~2000x performance speedup using OpenMP 4.0 PARALLEL and SIMD constructs on Intel Xeon Phi coprocessors.
1 – EXPLICIT VECTOR PROGRAMMING RATIONALE
While the OpenMP loop construct defines loop-level parallelism on for (C/C++) or do loops (Fortran), re-using these existing constructs to perform explicit vector programming for vectorization would not work. The example in listing 1.1 shows a code fragment that can (partially) be executed in parallel, but cannot be vectorized by the compiler without additional knowledge about vectorization and safety information for SIMD vector length selection.
<strong>#define N 1000000</strong> float x[N][N], y[N][N]; <strong>#pragma omp parallel</strong> { <strong>#pragma omp for</strong> for (int i=0; i<N; i++) { <strong>#pragma omp simd safelen(18)</strong> for (int j=18; j<N−18; j++) { x[i][j] = x[i][j−18] + sinf(y[i][j]); y[i][j] = y[i][j+18] + cosf(x[i][j]); } } } listing 1.1 – An example of using worksharing OMP FOR and OMP SIMD constructs.
In listing 1.1, there are two issues that inhibit vectorization when only the loop (for) construct is used: i) the loop construct cannot easily be extended to the j-loop, since it would violate the construct’s semantics; ii) the j-loop contains a lexically backward loop-carried dependency that prohibits vectorization. However, the code can be vectorized for any given vector length for array y and for vectors shorter than 18 elements for array x. The solution to address these issues is to extend OpenMP with a set of constructs and clauses that enable programmers to identify SIMD loops explicitly in addition to parallel loops.
Vectorizing loops is one of the most significant and common ways of exploiting vector-level parallelism among optimizing compilers. However, one major obstacle for vectorizing loops is how to handle function calls without fully inlining these functions into loops that should be vectorized for vector execution on SIMD hardware. The key issue arises when the loop contains a call to a user-defined function sfoo() as shown in listing 1.2. As the compiler does not know what sfoo() does, unless the function is inlined at the call site, the compiler will fail to auto-vectorize the caller loop as shown in listing 1.2.
extern float sfoo(float); void invokesfoo(float *restrict a, float *restrict x, int n) { int i; for (i=0; i<n; i++) a[i] = sfoo(x[i]); } [C:/] icl -nologo -O3 -Qvec-report2 –Qrestrict example_foo.c C:example_foo.c(4): (col. 3) remark: <strong>loop was not vectorized</strong>: existence of vector dependence. listing 1.2. – An example of loop and user-defined function not vectorized.
To overcome this issue, OpenMP allows programmers to annotate user-defined functions that can be vectorized with the declare simd directive. The compiler parses and accepts these simple annotations of the function. Thus, programmers can mark both loops and functions that are expected to be vectorized as shown in listing 1.3.
<strong>#pragma omp declare simd</strong> extern float sfoo(float); void invokesfoo(float *restrict a, float *restrict x, int n) { for (int i=0; i<n; i++) a[i] = sfoo(x[i]); } <strong>#pragma omp declare simd</strong> float sfoo(float x) { ... // function body } [C:/] icl -nologo -O3 -Qvec-report2 –Qrestrict example_vfoo.c C:example_vfoo.c(9): (col. 3) remark: LOOP WAS VECTORIZED. C:example_vfoo.c(14): (col. 3) remark: FUNCTION WAS VECTORIZED.
listing 1.3 – An example of loop and user-defined function vectorized.
The functions invokesfoo() and sfoo() do not have to reside in the same compilation unit (or in the same file). However, if the function invokesfoo() is compiled with a compiler that supports SIMD annotations, the scalar function sfoo() needs to be compiled with the compiler that supports SIMD annotation as well. The vectorization of invokesfoo() creates a call to vfoo() (i.e., simdized sfoo()), and the compilation of annotated sfoo() needs to provide a vector variant vfoo(), in addition to the original scalar sfoo(). With the SIMD vector extensions, the function can be vectorized beyond the conventional wisdom of loop- nest (or loop) only vectorization.
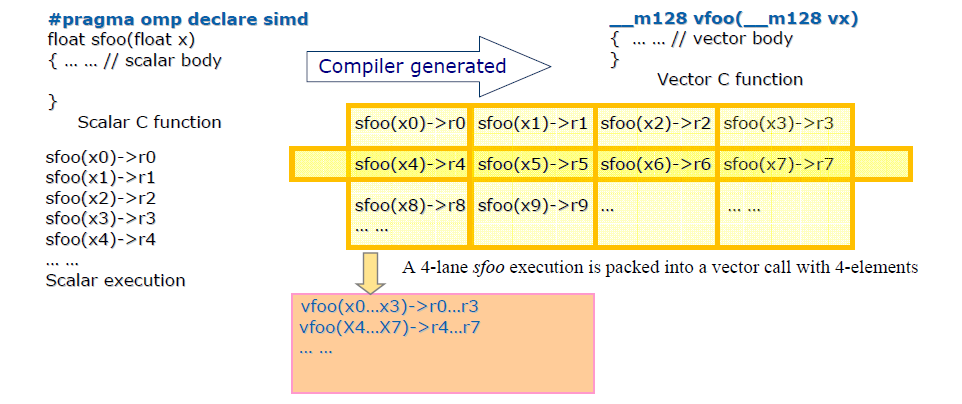
With the compiler code-conversion of a scalar function to its vector function as shown in listing 1.3, its SIMD vector execution is illustrated in Figure 1.4. Essentially, the compiler generates a vector function based on the original scalar function and its vector annotations. At the caller site, after vectorization, every four scalar function invocations (sfoo(x0), sfoo(x1), sfoo(x2), sfoo(x3)) are replaced by one vector function invocation vfoo(<x0…x3>) with vector input argument <x0…x3> and vector return value <r0…r3> through vector registers. The input argument x0, x1, x2 and x3 can be packed into one 128-bit vector register for argument passing, and the result r0, r1, r2 and r3 can be packed into one 128-bit vector register for returning the value. The execution of vfoo() exploits SIMD parallelism.
More around this topic...




In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}