
As promised, here is our first comparative evaluation of the two prominent parallel accelerators readily available for purchase and deployment. Compute, memory, latency – none of the three fundamental dimensions of their programming has been forgotten. The result? Surprising figures and real differences between the official specs and our measurements…
Florent Duguet, PhD – CEO, Altimesh
EXCLUSIVE : Download the complete benchmark source code!
By now, almost everyone in the HPC community has had a chance to give NVIDIA’s Kepler or Intel’s Xeon Phi parallel accelerators a spin. But what are they really worth in the field? To find out, scientifically, we submitted them to the very same applicative challenges. On one side of the ring, a commercial Kepler K20X. On the other side, a preproduction sample – the detail is important – of Phi SE10P. Their official specifications are detailed in Tables 1-A and 1-B below. Declared rivals in the marketplace, both cards share a similar vocation – that is, accelerate your applications – but they feature significant technical differences. It is in taking them into account that we coded the evaluation procedures proposed below.
Simple precisions regarding the architectures
Intel’s and NVIDIA’s architectures are very similar yet very different at the same time. Both are based on a many/multi-core grid structure including multiply-add floating-point compute units running at clock frequencies of 735 MHz (K20X) vs 1.1 GHz (SE10P). Kepler’s cores are accessible via API calls through a driver; Phi hosts a complete Linux OS, but its compute machinery is also accessible through an API. So much for the “black boxes”.
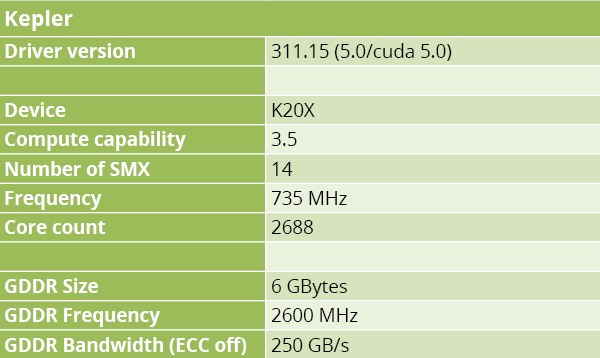
Table 1.A – NVIDIA’s Kepler K20X technical specifications.
Let’s now dive a bit deeper into their respective internal logics. Kepler accelerators comprise SMX (Streaming Multiprocessor Extended) units that one could compare to CPU cores. Each SMX has its own cache, instruction dispatching units and memory interface. These SMXes (14 in K20X) hold 192 single-precision floating-point units, each of which can perform a multiply-add in one clock cycle, for a headline peak performance of 3.95 Tflops. On the DP front, the units count is down to 64, with an official peak throughput of 1.31 Tflops.
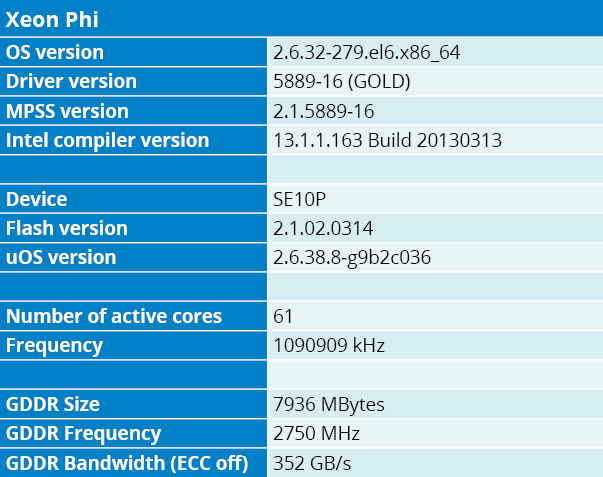
Table 1.B – Our sample of Intel’s Xeon Phi SE10P technical specifications.
Work distribution on a Kepler accelerator is organized in 32-entries warps. Warps are logically equal between each other – scheduling up to two instructions per cycle – with potential masking. We may compare them to CPU vector units since current AVX systems have 8 single-precision entries. To orchestrate operations, SMXes include four warp schedulers with two dispatch units each.
An SMX can run several contexts at the same time. This context distribution is flexible to some extent, but it is optimal if instructions are the same (SMXes offer single instruction caches). The maximum number of concurrent “threads” to be run is 2048, which in effect mobilizes 64 warps. Hiding latency for some operations (e.g. memory access) requires a maximization of the number of concurrently active warps. Note that the number of registers available is 2 Mbits for each SMX, for an approximate total of 28 Mbits in a K20X. This register space is shared among active warps, which narrows it down to 1024 bits per entry – or 32 registers of 32 bits.
Intel’s Xeon Phi, on the other hand, is an implementation of the x86 MIC (Many Integrated Core) architecture. This architecture is easier to figure: it holds several independent cores (61 in our setup) featuring 512-bit vector units. Each core is hyper-threaded with up to four threads. Vector operations are structurally very similar to SSE or AVX, but with a significantly broader base and reach (Intel’s Reference Guide is more than 700 pages long). A now well-known example of this is the new gather and scatter operations. Designed to ease vector access to memory, they for instance perform a lookup in a single instruction.
Functional analogies
These structural differences notwithstanding, we must consider some analogies between the two architectures, if only from the standpoint of a programmer with a mission to design a consistent benchmarking suite. These analogies, listed in Table 2, should not be seen as a reference for comparison, but rather as a guide for programming insights and in view of the brief technical notes at the end of the article.
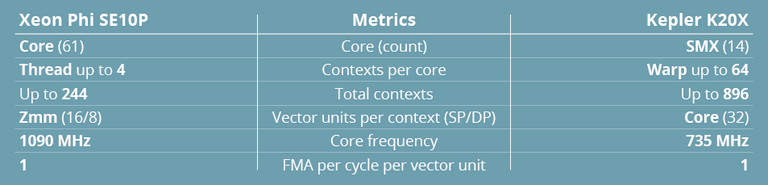
Table 2 – Architectural specifications.
Based on both accelerators’ metrics, we compare vector units with warps, not cores. Indeed, each warp is largely independent and can be paused at some points, just as a thread (within hyper-threaded Xeon Phi cores) would be. This results in comparable vector unit sizes of 32 versus 16. Frequency is similar, or at least in the same range. Each vector unit entry can execute a fused multiply and add in a single cycle. Both architectures also have special function units (SFU) that allow exponential or trigonometric operations, among others, to be computed with excellent throughput. However, these units and the hardwired features they include are so different structurally that we decided to leave them out of this work.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















