
Très largement utilisée en simulation physique et en robotique, la détection de collision permet également de démontrer un principe de réalité contre-intuitif : pour obtenir les meilleures performances, mieux vaut paralléliser… avec modération !
Cette seconde livraison de l’Atelier CUDA va nous amener à regarder de près un problème de base commun à beaucoup d’applications de simulation : la détection de collisions. Si son applicabilité immédiate est ce qui nous intéresse le plus ici, ce problème offre également un avantage aux grands débutants en programmation massivement parallèle : de par sa nature même, il force à oublier un certain nombre de réflexes intellectuels acquis par la pratique du développement séquentiel. Pour en venir à bout efficacement, il faut accepter de laisser les vieilles intuitions au vestiaire et, tout simplement, penser parallèle dès le départ.
Traditionnellement, l’implémentation d’une détection de collision se divise en deux phases successives – la phase dite “large” et la phase dite “étroite”. La phase large a pour objet d’identifier les paires d’objets 3D pouvant potentiellement entrer en collision. C’est la plus délicate et c’est celle qui va nous occuper aujourd’hui. Ensuite, au cours de la phase étroite, on analyse chaque paire identifiée pour déterminer si une collision se produit réellement.
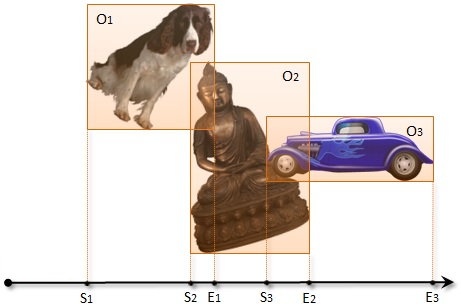
Le souci, avec sort and sweep, c’est que, quelle que soit la façon dont on le code, il se caractérise par un large niveau de divergence à l’exécution. Concrètement, les threads qui aboutissent à un point final dans le tri se terminent immédiatement, tandis que celles qui continuent à s’exécuter doivent reparcourir le tableau des objets ou des paires en un nombre variable d’étapes. Il en découle que les threads associées aux objets les plus grands travaillent plus que celles associées aux objets les plus petits. Donc, si le contexte mixe des objets de tailles différentes, les temps d’exécution des threads adjacentes vont varier fortement, d’où le terme de divergence d’exécution – condition à éviter comme le diable en programmation parallèle.
Avec les CPU, on a l’habitude de s’appuyer sur de larges espaces de cache très proches du contexte d’exécution. Ces espaces rendent les accès mémoire quasiment gratuits en termes de performances dans la mesure où les données sont la plupart du temps disponibles en cache. Mais la parallélisation massive change la donne du tout au tout. Le cache physique, quel que soit sa taille, doit servir un nombre de threads bien plus important. Ce n’est pas grave si les threads exécutent plus ou moins le même code au même moment car alors, la taille globale des données manipulées a toutes les chances de rester relativement réduite. Dans le cas contraire, comme ici avec sort and sweep, le volume des données manipulées explose, de sorte que la taille de mémoire cache effectivement disponible pour chaque thread peut diminuer fortement, jusqu’à parfois tendre vers 0.
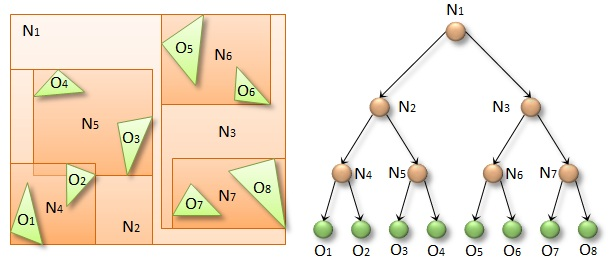
Pour éviter cet essoufflement, la bonne approche consiste à utiliser une Bounding Volume Hierarchy (BVH), structure d’accélération très largement utilisée en ray tracing. Comme son nom le laisse à penser, une BVH est essentiellement une arborescence d’objets (en l’occurrence, d’objets 3D). Le truc, c’est d’associer à chaque objet une enveloppe (“bounding box” dans la littérature) en fonction de sa position sur l’arborescence.
Traversée fantastique
Etant donnée l’enveloppe d’un objet particulier, il est assez simple de coder une fonction récursive permettant d’identifier l’ensemble des objets appartenant aux enveloppes qu’elle chevauche. Le listing 1 propose une telle fonction, qui prend notamment comme paramètres une BVH et une enveloppe à analyser. Après avoir testé l’enveloppe sur la BVH, la fonction retourne une liste de collisions potentielles. NB : la littérature utilise traditionnellement le terme “axis-aligned bounding box” pour qualifier ce que nous appelons “enveloppe”, d’où le nom des variables dans le listing.
L’idée consiste à traverser la hiérarchie de haut en bas, en commençant par la racine. A chaque nœud, on regarde si son enveloppe chevauche l’enveloppe passée en paramètres. S’il n’y a pas de chevauchement, on sait qu’aucun des descendants des deux enveloppes ne pose de risque de collision. S’il y a chevauchement, on regarde si le nœud est une enveloppe ou un descendant final. Si c’est une enveloppe, on continue l’analyse récursivement sur ces descendants immédiats. Si c’est descendant final, on indique une collision potentielle.
Et donc, pour identifier l’ensemble des collisions potentielles entre chaque objet, il suffit d’exécuter une analyse sur chaque objet en parallèle. C’est ce que vous propose le listing 2. Notez que le mot clé __device__ déclaré juste avant traverseRecursive() commande l’exécution sur le GPU, tandis que __global__ nous permet de lancer l’exécution à partir du CPU. Les objets BVH et CollisionList nous servent à stocker les pointeurs mémoires GPU nécessaires pour accéder aux nœuds de la BVH et retenir les collisions potentielles. Il est plus simple ici de les déclarer du côté CPU et de les passer par valeur au kernel.
La première ligne du kernel aboutit à un index unidimensionnel linéaire pour la thread courante. Ainsi, pas besoin d’essayer de deviner la taille des blocs et des grilles. Il suffit de lancer numObjects threads d’une façon ou d’une autre : la seconde ligne fait le ménage automatiquement. C’est à la troisième ligne que l’enveloppe de l’objet concerné est analysée et que les processus récursifs sont lancés.

Si tout va bien, en fonction du GPU mobilisé, le temps d’exécution ne devrait pas dépasser 5 millisecondes. C’est bien, mais c’est encore vraiment beaucoup compte tenu du fait que notre kernel ne traite qu’une partie de la détection de collision, qui elle-même n’est qu’une partie de toute application de simulation. On doit donc pouvoir faire nettement mieux.
Minimiser la divergence
Ca ne vous aura probablement pas échappé, notre implémentation parallèle ne manque pas non plus de divergence. Concrètement, la décision de ne pas traiter un nœud ou d’analyser récursivement ses descendants est prise par chaque thread de façon indépendante et, du coup, rien ne garantit que les threads adjacentes resteront synchronisées. Pour gérer ce problème, le plus simple est encore de traverser l’arborescence de façon itérative et de traiter la pile de récursion explicitement, comme au listing 3.
La boucle s’exécute une fois pour chaque nœud qui chevauche l’enveloppe passée en paramètre. On commence par vérifier si les descendants du nœud courant se chevauchent et on indique une intersection s’il s’agit d’un descendant final. On regarde ensuite si les descendants qui se chevauchent sont des nœuds devant être traités par une itération supplémentaire. S’il n’y a qu’un descendant, on fait de celui-ci le nœud courant et on recommence l’opération. S’il y a plusieurs descendants, on fait de celui de gauche le nœud courant et on pousse celui de droite sur la pile. Enfin, s’il n’y a pas de descendant à traiter, on reprend le traitement sur le dernier nœud poussé sur la pile – la traversée s’arrêtant lorsque la pile est vide.
En fonction du GPU dont vous disposez, vous devriez obtenir un gain de temps d’environ 4X par rapport à l’implémentation précédente. L’explication est simple : cette fois, chaque thread exécute inlassablement la même boucle, quelle que soit la décision de traversée qu’elle est amenée à prendre en fonction du contexte. Par conséquent, les threads adjacentes exécutent les itérations de façon synchrones, et ce même si elles traversent des parties de l’arborescence éloignées les unes des autres.
Jouer sur la proximité
Mais penchons nous un instant sur ces occurrences où les threads traversent effectivement des parties éloignées de l’arborescence. Lorsque le cas se produit, elles accèdent à des nœuds différents (divergence de données) et exécutent un nombre différent d’itérations (divergence à l’exécution). Or, dans notre dernière implémentation, rien ne garantit que les threads adjacentes traiteront des objets effectivement adjacents dans l’espace 3D qui nous occupe. Si bien que le niveau de divergence dépend fortement de l’ordre dans lequel nous présentons les données.
Pour remédier à cela, nous pouvons tirer parti du fait que les objets que nous analysons sont ceux avec lesquels nous avons spécifié la BVH. Comme celle-ci est par nature hiérarchique, les objets qui sont effectivement proches les uns des autres dans notre espace 3D ont toutes les chances d’être situés dans des nœuds adjacents. Autrement dit, la proximité des objets dans l’espace 3D est indiquée par la proximité des nœuds dans l’arborescence. Pour minimiser les divergences que nous venons d’évoquer, il suffit donc d’ordonner nos traitement en conséquence, comme au listing 4.
Ainsi, au lieu de lancer une thread par objet comme précédemment, on lance une thread par descendant final. Cela ne change rien à ce qui se passe dans notre kernel de base : chaque objet ne sera traité qu’une et une fois seulement. Mais ce simple ré-ordonnancement aboutit à un gain de temps d’au moins 2X. Avouez qu’il aurait été dommage de nous en passer, et pour l’efficacité, et pour l’élégance…
Eliminer les redondances
Si vous êtes encore avec nous jusqu’ici, vous aurez sans doute remarqué qu’un double problème subsiste : chaque collision potentielle sera indiquée deux fois (une fois pour chaque objet de la paire), et chaque objet indiquera une collision avec lui-même. Il en découle qu’on peut encore gagner du temps en évitant les analyses donnant des résultats redondants. Qu’à cela ne tienne, une simple modification de notre algorithme va gérer ces cas simplement. Il nous suffit en effet de prévoir que pour qu’un objet A indique une collision potentielle avec un objet B, A doit apparaître avant B dans l’arborescence.
Pour éviter de traverser entièrement la hiérarchie jusqu’aux descendants finaux afin de déterminer si tel est le cas, nous allons garder en mémoire deux pointeurs additionnels pour chaque nœud. Ces pointeurs nous serviront à savoir en interne quel est le descendant final le plus à droite susceptible d’être atteint par chacun des descendants du nœud en cours de traitement. Ainsi, pendant la traversée, on pourra passer outre tous les nœuds ne pouvant être utilisés pour atteindre les descendants finaux situés après le nœud en cours de traitement. Certes, cette explication verbale est un peu compliquée, mais le listing 5 met ça en musique de façon bien plus claire. Et grâce à lui, on améliore encore notre temps de traitement d’un facteur 2…
Indépendance ou simultanéité ?
En affinant nos implémentations successives, nous sommes restés sur une traversée “indépendante” de l’arborescence. En d’autres termes, aucun des traitements réalisés sur un objet donné n’est réutilisé pour les autres. On peut donc légitimement se demander s’il n’y aurait pas moyen d’optimiser aussi à ce niveau-là. Si les objets adjacents dans l’espace 3D exécutent grosso modo les mêmes itérations, ne pourrait-on pas les grouper et exécuter un traitement unique sur l’ensemble du groupe ?
Cette réflexion est ce qui a conduit Christian Lauterback, Qi Mo et Dinesh Manocha, de l’Université de Caroline du Nord, à proposer un algorithme de traversée simultanée. Au lieu de nous occuper de chaque nœud individuellement, l’idée consiste à traiter des paires de nœuds en partant de cette évidence : si leurs enveloppes ne se chevauchent pas, alors il n’y aura aucun chevauchement dans leur descendance respective. En revanche, si chevauchement il y a, on peut traiter rapidement toutes les paires possibles parmi leurs descendants. Une implémentation récursive nous permettra d’identifier efficacement tous les descendants finaux se chevauchant, c’est-à-dire toutes les collisions potentielles.
Sur un processeur mono-cœur, la traversée simultanée fonctionne à merveille. On part de la racine (qui forme une paire avec elle-même) et on exécute une traversée complète grâce à laquelle les collisions potentielles sont identifiées avec une efficacité remarquable. En effet, le nombre d’opérations élémentaires est nettement moindre qu’avec une traversée indépendante (environ 60 % en moins), alors que la nature du traitement reste essentiellement identique.
Oui… mais non !
Pour paralléliser la traversée simultanée, tout ce que nous avons à faire est de découper notre problème en parties indépendantes de façon à solliciter le GPU à la hauteur de ses possibilités propres. Par exemple, on pourrait commencer la traversée non plus à la racine mais à un ou deux niveaux plus bas, regrouper les nœuds par blocs de 256 et lancer une thread pour chaque paire (soit, pour mémoire, 32 896 au total). On obtiendrait ainsi un haut niveau de parallélisme à bon compte. Les seules opérations supplémentaires nécessaires par rapport à un traitement séquentiel seraient en effet de tester le chevauchement de chaque paire de départ. Ce n’est pas la mer à boire…
Dans cet hypothèse, on aurait donc un algorithme économe en opérations élémentaires et massivement parallélisé. Le profil-type pour un niveau de performance optimal. Oui… mais non ! En pratique, à l’épreuve du feu, les résultats se révèlent très mauvais. Pourquoi ? Parce que, vous l’aurez deviné, la divergence, la méchante divergence, est de retour. Dans la traversée simultanée, chaque thread travaille sur une partie complètement différente de l’arborescence, de sorte que la divergence de données redevient très élevée. Par ailleurs, il n’y a plus aucune corrélation entre les décisions de traversée prises par les threads adjacentes, si bien que la divergence à l’exécution redevient maximale. Enfin, du fait le l’indépendance des threads, leurs temps d’exécution vont se remettre à varier très largement. Une horreur !
Comment pallier à cela ? De nombreuses tentatives ont été testées : meilleure assignation des tâches, traversées par paquets, synchronisation des warps, répartition de charge dynamique, etc. Rien n’y fait. Au mieux, on s’approche du niveau de performance de la traversée indépendante, mais on n’est pas encore arrivé à le dépasser.
La morale de cette histoire, c’est qu’un algorithme simple qui dans les faits exécute plus d’opérations que nécessaire peut être plus efficace qu’un autre plus intelligent mais plus complexe à paralléliser. C’est cette complexité qui induit la divergence et rend l’optimisation quelque fois impossible. Les envies de parallélisation peuvent se révéler addictives. Il faut juste savoir s’arrêter à temps !
More around this topic...
In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















