
Où l’on démontre qu’en fonction de la stratégie de distribution des threads sur les cœurs de Phi, il est possible de gagner – ou de perdre – jusqu’à 50 % de performance applicative.
Jérôme Vienne, PhD
HPC Software Tools Group
Texas Advanced Computing Center (TACC)
Le placement des threads OpenMP à l’intérieur d’un nœud impacte de façon importante les performances applicatives. Grâce à la librairie OpenMP d’Intel, il est possible de programmer cette “thread affinity” sur un ensemble de cœurs logiques ou physiques – une fonctionnalité disponible pour les processeurs mais aussi pour les accélérateurs Xeon Phi. Ne pas utiliser cette faculté expose le placement des threads aux seules décisions du système d’exploitation, avec des risques de migrations intempestives. Chaque migration entrainant un rechargement des données dans les caches des nouveaux cœurs, on imagine facilement la dégradation de performances qu’elle occasionne, surtout sur les sous-systèmes comptant plus de 60 cœurs. Plusieurs méthodes existent pour optimiser ce placement. Dans cet article, nous allons évoquer les plus efficaces.
Cerner le problème
Rien de tel pour illustrer l’importance de ce placement que de partir d’une application test. Pour l’occasion, nous avons choisi la version OpenMP du benchmark Integer Sort (IS) des NAS Parallel Benchmarks. IS effectue un tri d’entiers et fournit, à la fin de l’exécution, le nombre de clés triées en millions. Pour l’heure, nous allons simplement compiler le code sans le modifier, avec la simple option -mmic, puis lancer l’exécution sur une version SE10P de Phi (61 cœurs à 1.1 GHz). L’expérience va consister à faire varier le nombre de thread OpenMP de 1 à 244 (4 threads sur chacun des 61 cœurs) pour les 3 types de placement définis par Intel, à savoir balanced, scatter et compact.
Pour utiliser un placement particulier, il suffit de le spécifier littéralement, comme ceci :
export KMP_AFFINITY= balanced
La définition de ces types de placement sera donnée plus bas ; pour le moment, contentons-nous de regarder les résultats du graphique 1. Pour compact, la croissance est linéaire. Plus le nombre de threads est élevé, plus le nombre de clés triées est important. Ce nombre converge vers la valeur obtenue avec balanced lorsque l’on utilise plus de 240 threads.
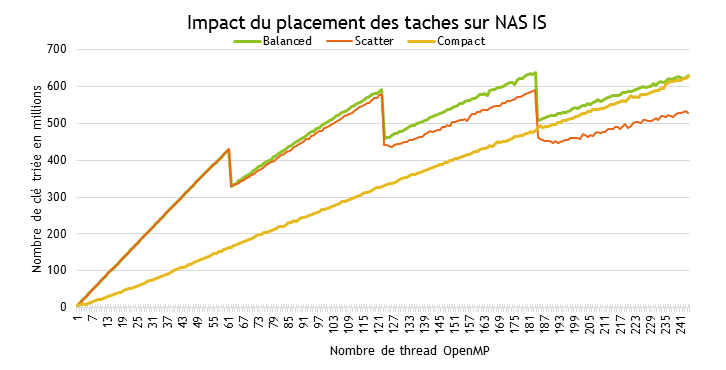
balanced et scatter ont un comportement totalement différent. Les valeurs obtenues sont assez proches au départ mais divergent de plus en plus lorsque l’on augmente le nombre de threads. On observe également des pertes de performances après 61, 122 et 183 threads. Elles correspondent au placement d’une, deux ou trois threads sur l’ensemble des cœurs disponibles, et signalent une mauvaise répartition de charge (certains cœurs traitent plus de threads que d’autres). Notez enfin que la plus haute valeur est obtenue avec 183 threads OpenMP sur un placement de type balanced. Cette petite expérience démontrant comme prévu l’impact des différents types de placements sur le niveau de performance atteignable, il est temps maintenant de les examiner plus en détails.
Le paramètre “modifier”
KMP_AFFINITY est donc la variable d’environnement exposée par Intel pour le placement des threads OpenMP sur les processeurs et les accélérateurs Xeon PHI. Son format est le suivant :
KMP_AFFINITY=
En pratique, on peut tout à fait combiner ces valeurs. Ainsi, il est tout à fait possible d’écrire : KMP_AFFINITY=verbose, granularity=fine,proclist=[3,0,{1,2},{1,2}],explicit
Seule la valeur type vue plus haut est obligatoire, mais toutes ont leur importance. Regardons-les une par une, en commençant par modifier. Cet argument permet à la fois d’obtenir des informations sur le placement des threads OpenMP et d’optimiser leur placement. Pour ce faire, plusieurs valeurs sont possibles.
– verbose/nonverbose, comme son nom le suggère, spécifie (ou non) l’obtention d’informations concernant le nombre de cœurs, de threads, de threads par cœur et concernant le placement. Le listing 1 donne un aperçu du résultat. Plusieurs points sont à noter. Les cœurs physiques de l’accélérateur MIC sont indiqués de 0 à N-1, N étant le nombre total de cœurs. On voit également apparaître des “OS proc” à valeur unique qui sont utilisés pour identifier les différents cœurs logiques. Le placement des threads n’affecte pas leurs valeurs. Enfin, l’OS proc commence par 1 et prend la valeur 0 au premier cœur logique du dernier cœur physique. Les trois derniers cœurs logiques de ce dernier cœur physique ont donc pour identifiant 241, 242 et 243.
– granularity=
proclist=[<proc_list>] permet de
En pratique, on peut tout à fait combiner ces valeurs. Ainsi, il est tout à fait possible d’écrire :
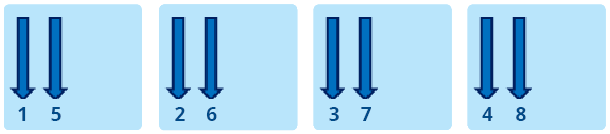
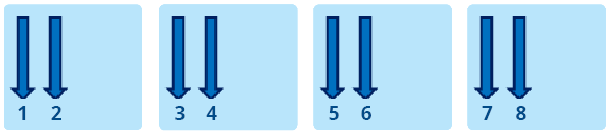
KMP_AFFINITY=verbose,granularity=fine,proclist=[3,0,{1,2},{1,2}],explicit qui affichera les informations découlant de verbose avant de finir par les indications du listing 2. Sachez qu’il existe d’autres valeurs possible pour modifer, mais qu’elles ont ici moins d’importance. Pour les connaître, référez-vous à la documentation fournie avec les compilateurs Intel. L’argument type détermine le placement des threads OpenMP selon les valeurs suivantes : – compact : dans notre précèdent exemple, il était possible de voir que le résultat pour compact progressait de manière linéaire, et en tous cas très différemment de balanced et scatter. La figure 1 permet de ben comprendre son fonctionnement. L’objectif de compact est de placer les threads aussi proches que possible les unes des autres. Xeon Phi supportant jusqu’à quatre threads par cœur, il en résulte que les 4 premiers threads seront sur le même cœur. Ce placement est efficace pour les applications de type compute-intensive qui privilégient l’utilisation du cache à la bande passante. – scatter : cette valeur est à privilégier pour les applications demandant de la bande passante. Comme le montre la figure 2, l’objectif de scatter est de distribuer les threads entre tous les cœurs. Si l’on utilise 60 threads OpenMP avec scatter, chaque thread sera exécuté sur un cœur diffèrent. – balanced : il s’agit d’un compromis entre scatter et compact, uniquement disponible sur Xeon Phi. Comme le montre la figure 3, balanced distribue les threads entre les cœurs mais son comportement diffère lorsque les cœurs exécutent plus d’un thread. Dans ce cas, balanced va essayer de distribuer les threads en essayant de maintenir leur proximité. Lorsqu’un thread n communique beaucoup avec des threads “proches” (dans le sens du rang), il y a de fortes chances que ces threads soient sur le même cache. Ce mécanisme explique la différence de performances avec scatter et les bons résultats obtenus avec l’algorithme IS. – explicit : comme indiqué plus haut, cette valeur assigne les threads OpenMP en fonction de la liste donnée par la valeur de proclist. Ces options sont donc destinées à faciliter le placement des threads OpenMP. Le problème, c’est que compte tenu des 60+ cœurs de Phi, il peut s’avérer complexe de définir un ensemble de threads si plusieurs processus MPI veulent utiliser le mode offload. Pour chaque processus, il faudrait définir une proclist, ce qui deviendrait très vite contraignant. Heureusement, Intel y a pensé en exposant une nouvelle variable d’environnement baptisée logiquement KMP_PLACE_THREADS. Avant d’en examiner le détail et les valeurs, étudions un autre exemple de code montrant l’importance d’un bon placement. Avec une implémentation simplissime d’IS, sur 244 Threads, la différence de performance entre compact et scatter était de l’ordre de 25 %. Si l’on fait appel à MKL, toujours sur Xeon Phi, cette différence peut se révéler encore plus importante. Le code du listing 3 calcule une approximation du nombre de flops réalisées par dgemm. Pour mémoire, dgemm calcule C <= alphaA * B + betaC en double précision, A, B et C étant étant des matrices et alpha / beta des coefficients multiplicateurs. Cette implémentation n’est pas totalement optimisée mais peu importe, elle suffit à notre démonstration. Pour compiler, n’oubliez pas de définir le nombre de threads et de linker MKL comme ceci : icc -o test_affinity -mmic affinity.cpp -mkl -openmp En partant de matrices de 10 000 x 10 000, le code mesure le temps nécessaire à dix appels dgemm pour l’obtention d’une moyenne du nombre de Gflops. Comment cette estimation est-elle réalisée ? Pour la multiplication de la matrice A par B, K-1 additions et K multiplications sont nécessaire pour calculer chaque élément du résultat, soit 2K-1 opérations. Comme les matrices sont de dimension Size * Size, il faut (2K-1) * Size * Size opérations pour obtenir l’ensemble du résultat. Mais comme il faut encore multiplier C par beta et rajouter le résultat au résultat précédent, 2 * Size * Size opérations sont encore nécessaires. Ce qui nous donne au total (2K-1) * Size * Size + 2 * Size * Size opérations. Cela posé, sachant que la valeur de K est égal a Size, il est possible d’avoir une approximation du nombre d’opération à virgule flottante en ne considérant uniquement que 2 * Size * Size * Size. Regardons maintenant les résultats obtenus avec différents ensemble de threads, résumés par le graphique 2. Comme avec IS, en fonction des situations et du placement choisi, on peut parvenir à un gain de performance conséquent. Sur 244 Threads, la différence est de plus de 50 % entre scatter et compact / balanced. KMP_PLACE_THREADS Cette nouvelle variable d’environnement est disponible depuis la version 13.1.0.146 d’Intel Composer XE. Complémentaire à KMP_AFFINITY, elle permet de mieux contrôler le placement des threads à l’intérieur de Phi. On le laissait entendre dans les paragraphes précédents, KMP_PLACE_THREADS est très utile lorsque plusieurs processus MPI sollicitent Phi en mode offload, car elle permet de sélectionner facilement les cœurs. Sa syntaxe est la suivante : KMP_PLACE_THREADS= où n correspond au nombre de cœurs, m au nombre de threads par cœurs (maximum 4) et o à l’offset. Imaginons la situation où quatre processus MPI utilisent 60 threads chacun sur Phi SE10P (il est recommandé de laisser un cœur libre pour l’offload). Comment faire pour s’assurer que ces différents threads soient distribués sur quatre “zones” différentes de 15 cœurs chacune, de façon à ce qu’une zone soit dédiée aux threads provenant d’un processus MPI ? Commençons par définir deux variables : cores=$(( (OMP_NUM_THREADS+3)/4 )) offset=$(( cores*PMI_RANK )) cores nous permet de définir le nombre de cœurs nécessaires en fonction du nombre de threads OpenMP utilisés pour offload. offset détermine la valeur de déplacement, en fonction de PMI_RANK qui fournit le ranking de chaque processus MPI. Pour lancer votre code MPI (appelons-le “test_offload”), il faudra utiliser un wrapper (appelons-le “affinity_wrapper.sh”) similaire à celui du listing 4. Ensuite, il suffira de définir le nombre de threads OpenMP et d’appeler le wrapper avec le lanceur MPI : export OMP_NUM_THREADS=60 mpirun –n 4 –host myHost ./affinity_wrapper.sh Quel sera le placement des threads au final ? Pour le rang 0, nous aurons KMP_PLACE_THREADS=15Cx4T,00 ce qui signifie que les threads utiliseront les cœurs 1 à 15. Pour le rang 1, nous aurons KMP_PLACE_THREADS=15Cx4T,150 Pour les rangs 2 et 3, nous aurons KMP_PLACE_THREADS=15Cx4T,300 KMP_PLACE_THREADS=15Cx4T,450 KMP_PLACE_THREADS=60C,4t seuls 60 cœurs seront utilisés. Ainsi, vous l’aurez deviné, les placements les plus optimaux résulteront de la sollicitation conjointe des deux directives KMP_PLACE_THREADS et KMP_AFFINITY, la première pour le mappage en zones, la seconde pour l’affinage du placement à l’intérieur de chaque zone. Bons développements !
Le paramètre “type”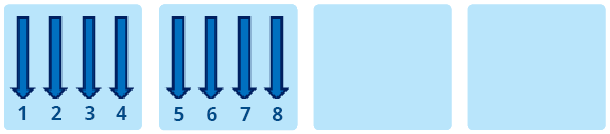
En utilisant MKL…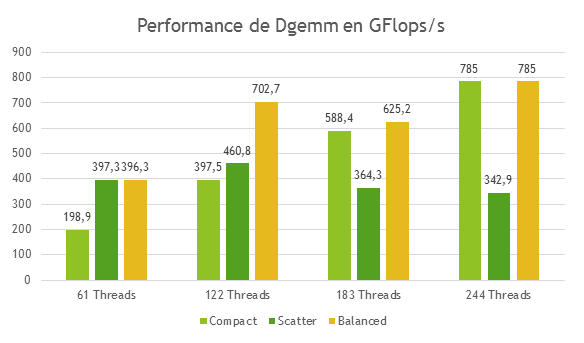
ce qui signifie que les threads utiliseront les cœurs 16 à 30.
ce qui signifie que les threads utiliseront respectivement les cœurs 31 à 45 et 46 à 60. Notez qu’il est possible également de laisser un cœur Phi libre pour l’offload sans utiliser MPI. Avec la directive suivante :
More around this topic...




In the same section








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.


















