
La richesse et la diversité des sessions techniques étaient cette année assez remarquables. Voici, en exclusivité, un florilège des plus marquantes, dans un désordre voulu. Si tel ou tel sujet retient plus particulièrement votre attention, vous pouvez accéder à l’intégralité de la session en vidéo, via son numéro, sur le site NVIDIA.
En accès direct :
• A – Imagerie et visualisation numériques
• B – Domaines scientifiques et mathématiques
• C – Systèmes et infrastructures HPC
• D – Programmation et développement HPC
A – IMAGERIE ET VISUALISATION NUMERIQUES

Accélérer la reconnaissance d’objets (S3102)
Si de très gros progrès ont été réalisés récemment dans la reconnaissance d’objets en général (visages, animaux, objets de marques…), il reste encore du chemin à parcourir pour ce qui est des temps de traitement. Cette session visait à présenter des techniques d’accélération destinées aux ordinateurs LPC (PC de bureau, smartphone…) mais utilisables en environnement HPC pour obtenir du temps réel.
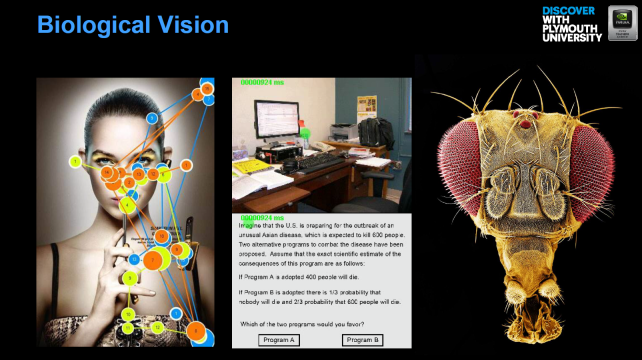
Un système de vision aux performances bluffantes (S3104)
Toujours dans le domaine de la reconnaissance d’objets, cette session, animée par Martin Peniak, de l’université de Plymouth, présentait un nouveau système de vision (pour l’identification d’objets, la navigation, etc.) inspirée de la façon dont certains organismes biologiques interagissent avec le monde. La démonstration était pour le moins convaincante, avec des résultats atteignant 100 % de réussite.

PCL : une bibliothèque accélérée pour le traitement d’images et de nuages de points (S3005)
Dans un grand nombre de secteurs d’activité, le traitement d’images 2D/3D et de nuages de points détermine l’efficacité des applications. Si vous êtes concerné, ne manquez pas cette session qui présente PCL (Point Cloud Library), une remarquable bibliothèque open source (licence BSD) contenant de nombreux algorithmes accélérés pour le filtrage, la reconstruction de surface, la segmentation, etc.
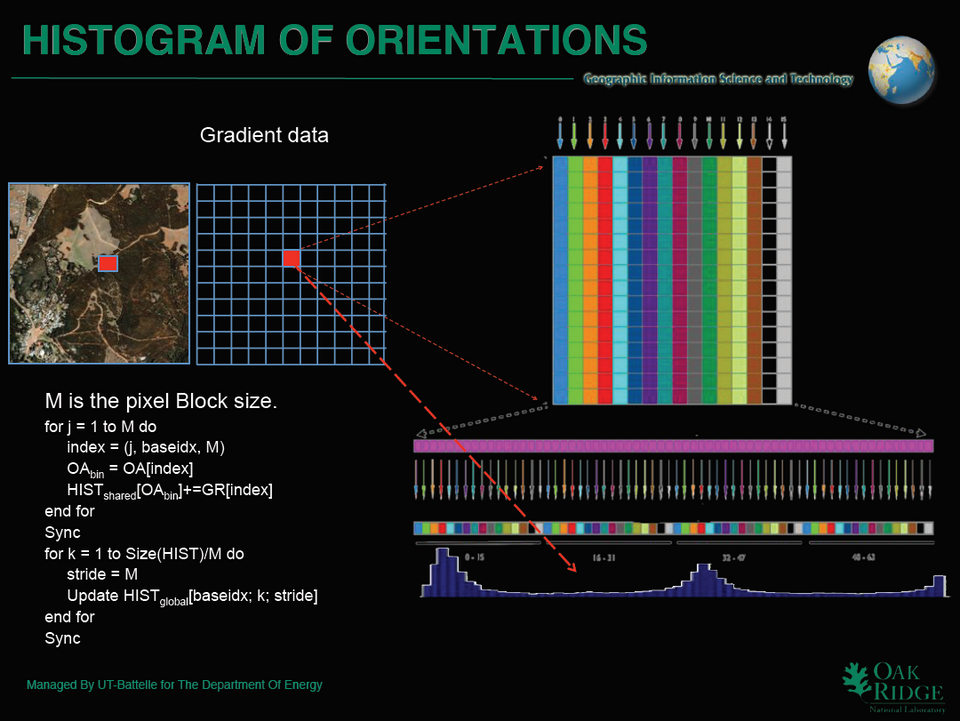
Analyser plusieurs Po de données d’imageries (S3495)
En présentant leur solution de détection de campements humains à partir d’images satellites, deux scientifiques d’Oak Ridge ont dévoilé plusieurs approches pour le développement d’algorithmes HPC capables d’analyser de très larges volumes de données d’imagerie (de l’ordre du Po). Dans leur cas, le traitement d’images couvrant plusieurs milliers de km² (en résolution “sub-metric”) donne des résultats en quelques secondes…
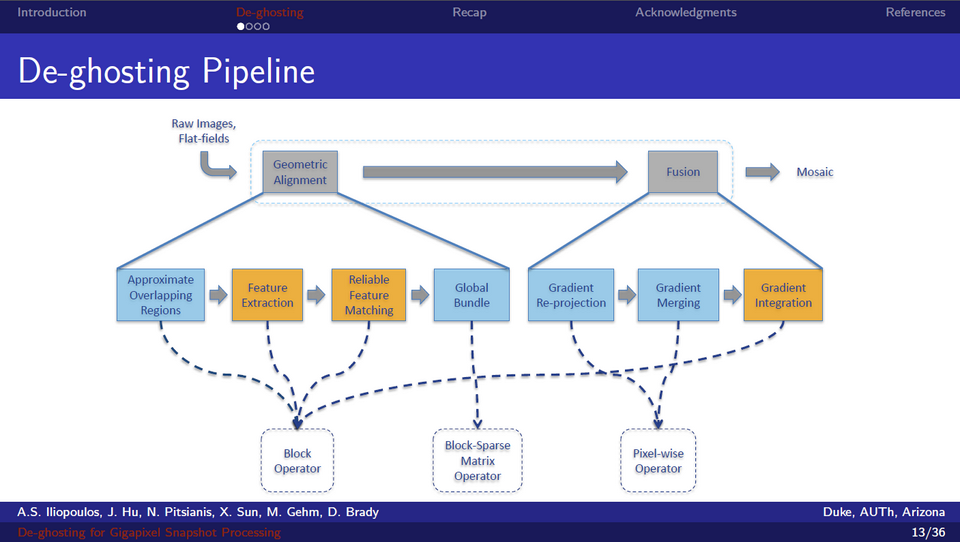
Des images gigapixels à moindre coût (S3219)
Présentée par un étudiant de Duke, Alexandros-Stavros Iliopoulos, cette session mettait en lumière un système de photographie gigapixels composé de 98 appareils photos d’entrée de gamme. Destiné à la prise de vues dynamiques, il s’accompagne d’un ensemble d’algorithmes de composition et de compensation accélérés par GPU. Une foultitude d’excellentes idées à suivre.
B – DOMAINES SCIENTIFIQUES ET TECHNIQUES

Plus loin en simulation moléculaire avec GROMACS (S3283)
Dans une session très interactive ironiquement intitulée “A microsecond-a-day keeps the doctor away”, le Dr Erik Lindahl, du Royal Institute of Technology de Stockholm, présentait les résultats de plusieurs mois de travail sur l’accélération GPU de GROMACS, à la fois sur station de travail et sur systèmes massivement parallèles. Outre les performances en elles-mêmes, la discussion portait sur les décisions d’architecture pour cette parallélisation hétérogène. Un échange riche d’enseignements profitables à l’ensemble de la communauté scientifique.
Du PC au Cray XK7, le top de la simulation moléculaire (S3097)
Tout est dans le titre. En présentant les résultats les plus récents des travaux en analyse et en visualisation moléculaire, John Stone, de l’université d’Illinois, s’est attardé sur leur implémentation à petite et large échelle. Avec un focus intéressant sur ce que l’accélération GPU apporte à la simulation des complexes les plus larges et des échelles de temps les plus longues.
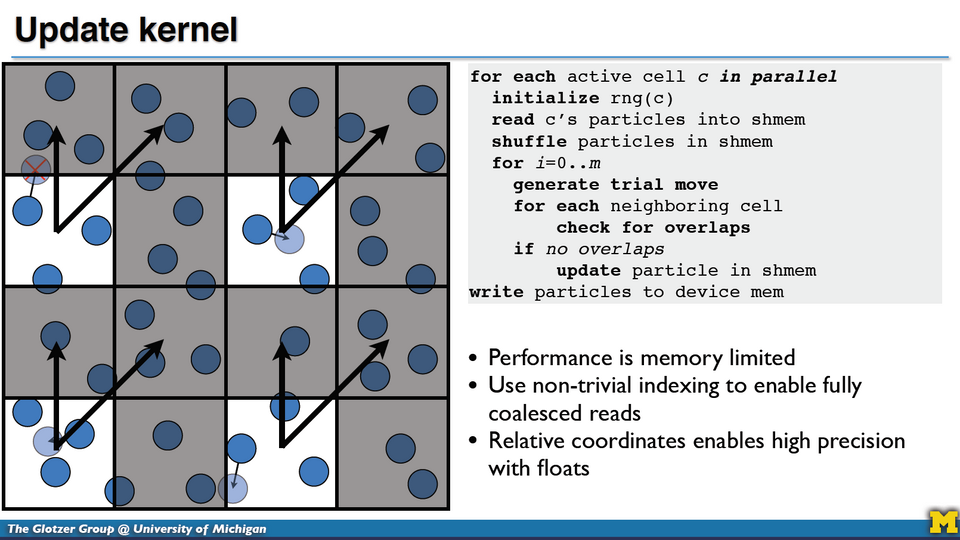
Des techniques pour la simulation de particules massivement parallèle (S3251)
Dans cette session aussi, présentée par Joshua Anderson (université du Michigan), on était dans l’état de l’art – en l’occurrence celui de la simulation de particules. Avec en vedette américaine un tout nouvel algorithme de type Monte Carlo, extrêmement efficace.
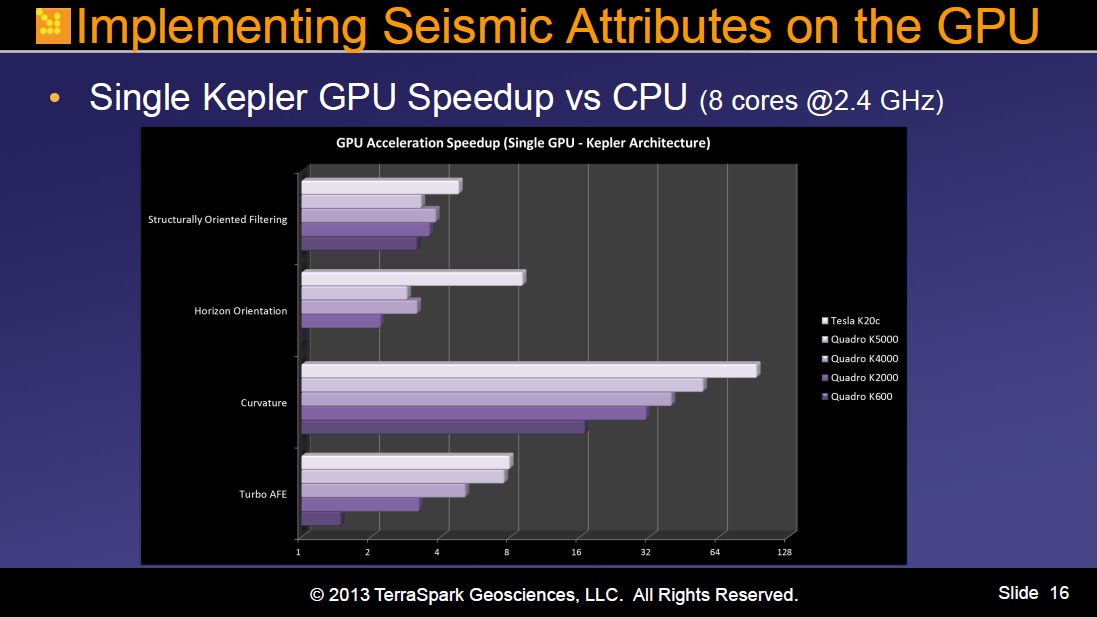
Implémenter des attributs sismiques sur GPU (S3105)
Dans une session riche en anecdotes vécues, Jonathan Marbach, Directeur de l’architecture logicielle et de l’ingénie de TerraSpark Geosciences, racontait les efforts de son équipe dans le portage sur GPU d’attributs sismiques très gourmands en ressources. L’intérêt de cette présentation ne résidait pas tant dans les résultats obtenus après portage que dans l’analyse des différentes stratégies de développement d’algorithmes liés au filtrage structurel du bruit, à l’orientation d’horizon ou à la tolérance aux erreurs.
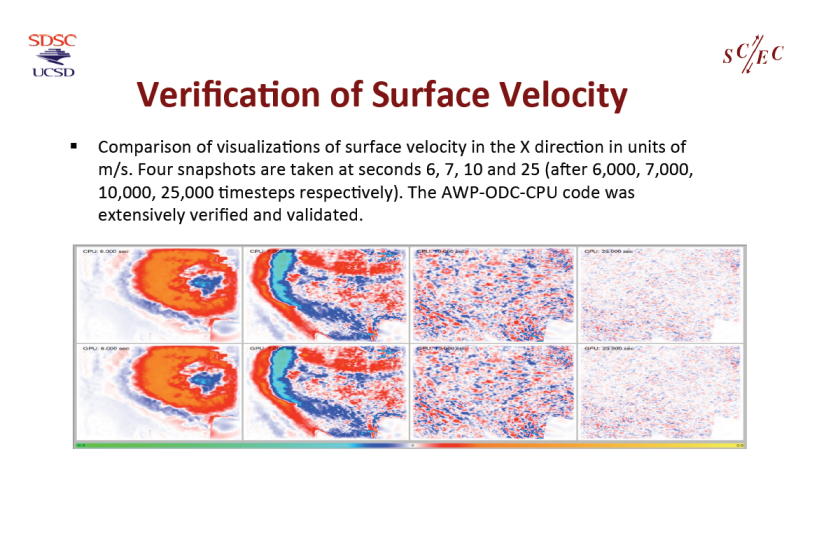
Simulation sismique de classe M8 (S3162)
Le Dr Yifeng Cui, Directeur du High Performance GeoComputing Lab de UC-San Diego, présentait une remarquable application AWP-ODC de simulation dynamique d’un tremblement de terre de magnitude 8 sur la faille de San Andreas. Les spécialistes sauront qu’il s’agit d’une première dans la classe M8. Point à souligner, cette application sert de base à un outil de simulation sismique de classe pétascale.
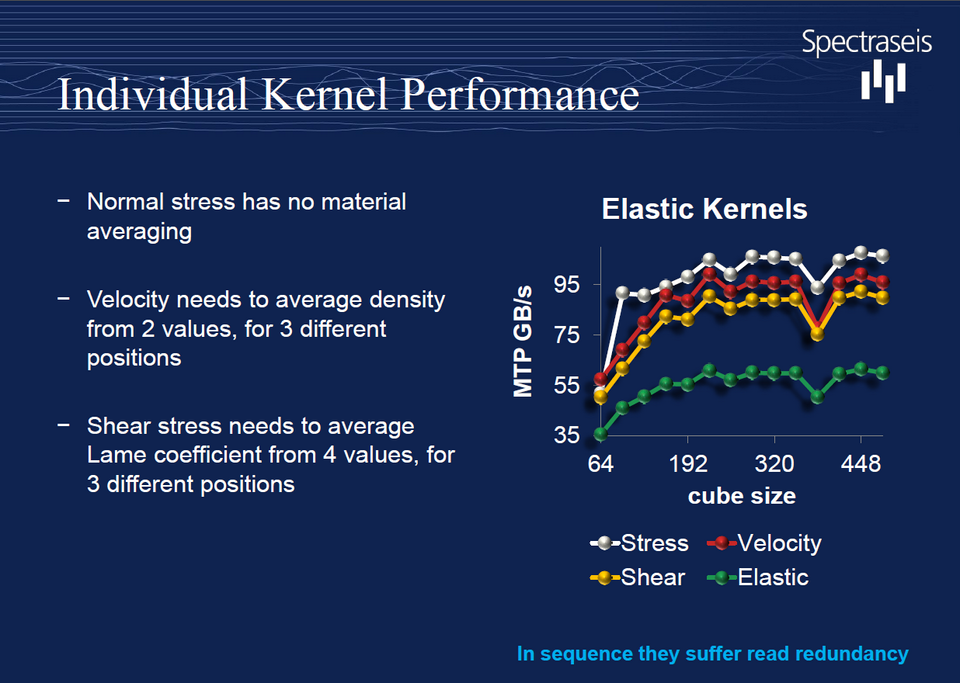
Des algorithmes de propagation d’ondes ultra-rapides (S3176)
Une certaine fierté émanait d’Igor Podladtchikov, de Spectraseis, lorsqu’il présentait, entre autres, ses implémentions “fully-functional” d’algorithmes de propagation d’ondes élastiques et acoustiques. Mais il y avait de quoi : en atteignant 180 Go/s de rendement, ses solveurs sont effectivement les plus rapides à ce jour sur station de travail.
Séquençage à très haute vitesse (S3004)
Bertil Schmidt, Professeur à la Gutemberg University de Mayence, présentait plusieurs outils et algorithmes dédiés au NGS (New Generation Seqencing), capable de produire très rapidement des millions de séquençages ADN et ARN à très bas coût. Citons notamment du code CUDA et des structures de données pour l’accélération de CUSHAW et CUSHAW2 et l’analyse de données métagénomiques.
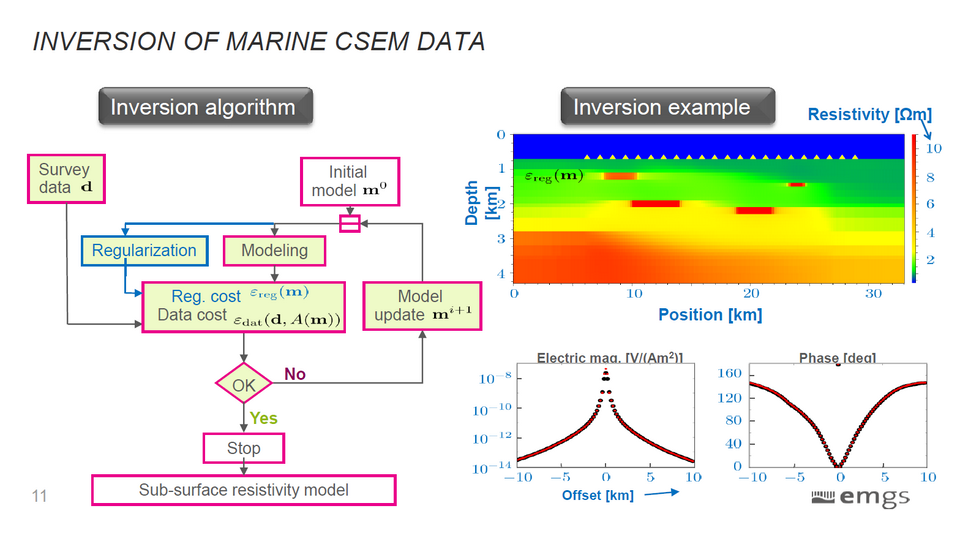
Parallélisation de méthodes pour les équations de Maxwell (S3340)
Dans cette session, le Dr Cyril Banino-Rokkones, d’EMGS, présentait la parallélisation sur GPU et sur CPU d’une méthode FDTD (Finite-Difference Time-Domain) 3D pour les équations de Maxwell, très utilisées dans la recherche en électromagnétisme. Bien sûr, ces implémentations se révèlent nettement plus efficaces que les méthodes séquentielles mais le plus intéressant était la comparaison des approches OpenMP et OpenACC notamment sur un benchmark réalisé pour l’occasion.

Titan : les premiers résultats (S3470)
Nonobstant quelques petits soucis de mise au point (cf. pour cela nos Actus de ce mois-ci), Titan, star du Top500 actuelle, commence à livrer ses premiers résultats. Jack Wells, Director of Science du laboratoire d’Oak Ridge, était là en personne pour nous les présenter : propriétés de matériaux magnétiques pour les énergies propres, techniques de combustion pour les moteurs de demain, modélisation de réacteurs à eau légère… il y en avait pour toutes les disciplines, d’autant que Mr Wells s’est laissé aller à quelques confidences sur le portage vers GPU de quelques grosses applications du laboratoire, jusqu’ici “CPU only”.
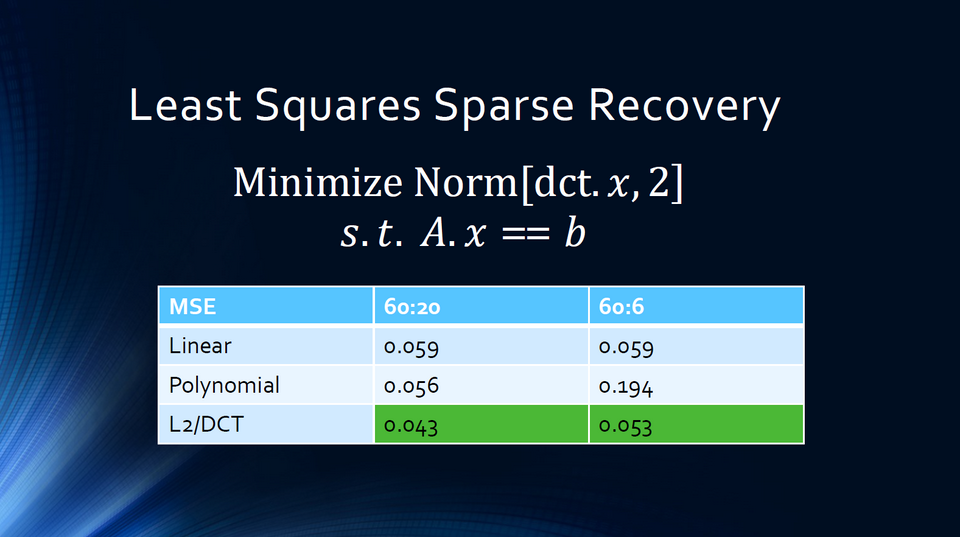
Les enjeux du “Compressed sensing” (S3221)
Responsable du développement chez Part Time Scientists, Wesley Faller proposait un intéressant tour d’horizon du Compressed Sensing, ensemble de technologies dédiées à la transmission de données issues de capteurs à travers des canaux à faible bande passante. Qu’il s’agisse de missions spatiales ou de tâches en environnements extrêmes, ces données peuvent dépasser très largement les capacités des réseaux qui les véhiculent. Le recours l’accélération HPC devient alors indispensable, à l’émission et à la réception, ce que facilite plusieurs librairies spécialisées.
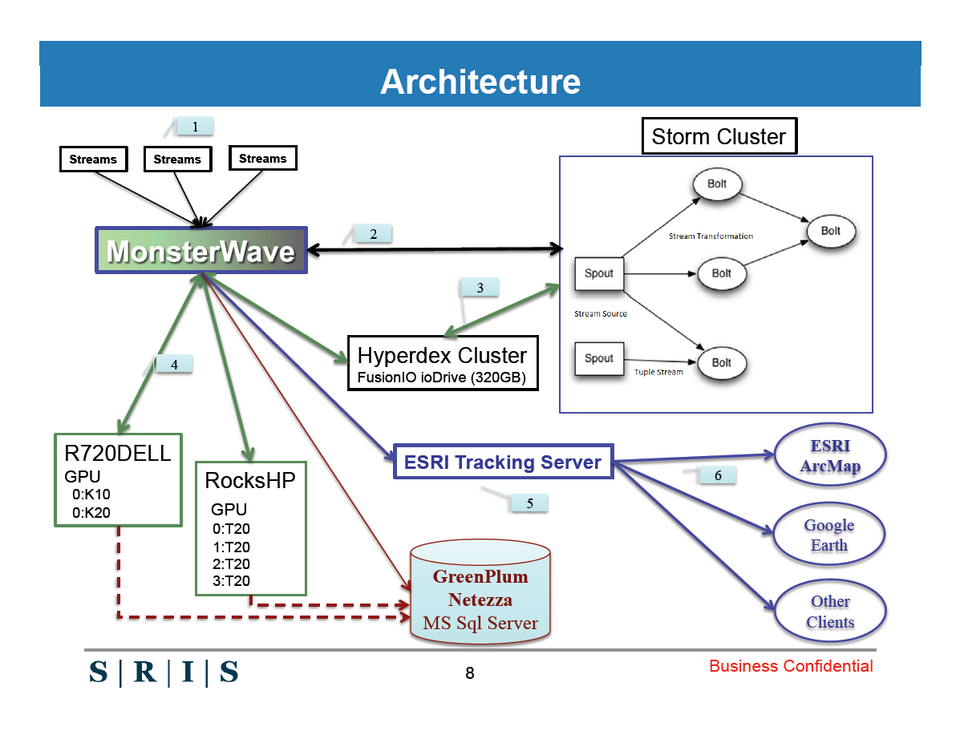
Du Big data en temps réel (S3305)
Dans cette session, le Directeur technique de SRIS, Srinivas Reddy, a évoqué une solution d’interprétation en temps réel de données géospatiales. D’un point de vue technique, l’intérêt de cette session résidait dans le mixage des technologies HPC et Big Data, dans la mesure où le système décrit collectait à l’origine plus de données que le cluster de calcul ne pouvait en traiter. Le recours à, notamment, un cluster HyperDex pour le stockage de données de référence s’est à ce titre révélé déterminant. Une session que nous recommandons aux chercheurs confrontés à ce type de problème, quelle que soit leur discipline.
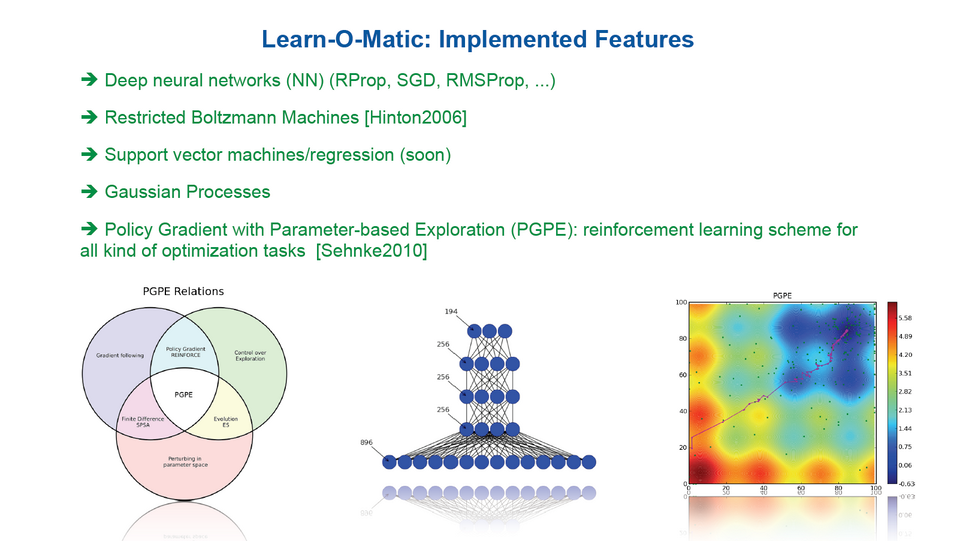
Une suite complète pour l’apprentissage des machines (S3356)
Learn-O-Matic est un ensemble complet d’outils destinés à faciliter l’apprentissage par les machines. L’usage de GPU permet de gérer avec beaucoup de facilité les métaparamètres, d’implémenter l’apprentissage par renforcement et de permettre la sélection des stimuli par pertinence. Compatible avec différentes architectures de réseaux neuronaux, cette solution était présentée à travers deux exemples concrets : l’identification de profil d’ozone à partir de données satellites et la prédiction de production d’énergie éolienne.
C – SYSTEMES ET INFRASTRUCTURES HPC
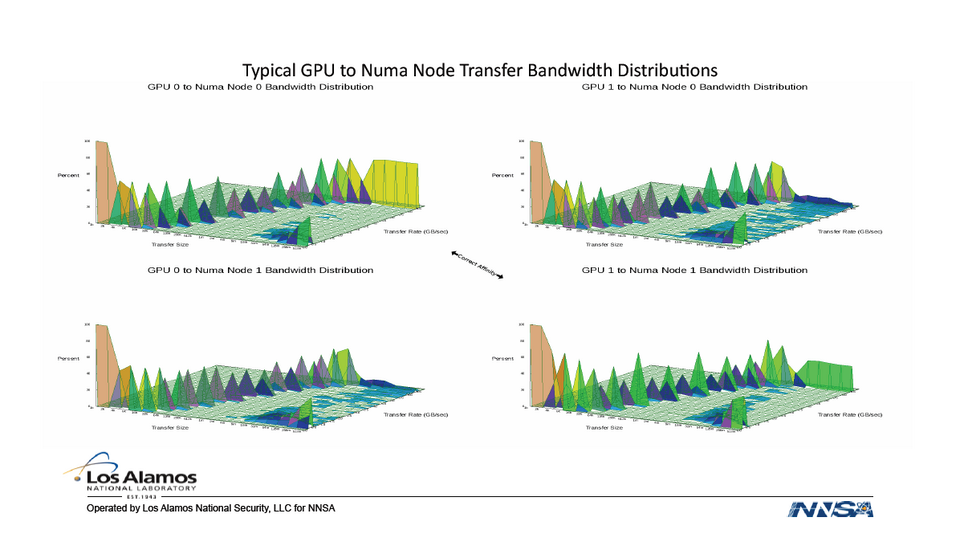
Comment tester les clusters HPC ? (S3248)
Dans une session particulièrement intéressante, trois chercheurs du laboratoire américain de Los Alamos ont présenté leur protocole de test de nouveau clusters HPC, en différenciant les plateformes CPU et GPU. La palette de test unitaires est trop large pour être décrite en détails ici, mais nous y reviendront largement, en nous focalisant plus particulièrement sur l’identification et la correction des “points de faiblesse”. Si la session vidéo vous intéresse, ne manquez pas la partie dédiée aux optimisations “spéciales Linpack”.
CUDA dans le cloud avec OpenStack (S3214)
Très tendance, cette session faisait le tour des bonnes pratiques pour le déploiement de clusters HPC dans le nuage. Prévalence d’OpenStack oblige, la discussion a vite tourné autour des améliorations de la version Grizzly par rapport à l’ancienne version Folsom. Quelques cas concrets ont été abordés dans les domaines du traitement de signal et de l’imagerie, avec des mesures de performances qui tendent à plaider la cause du HPC à distance…
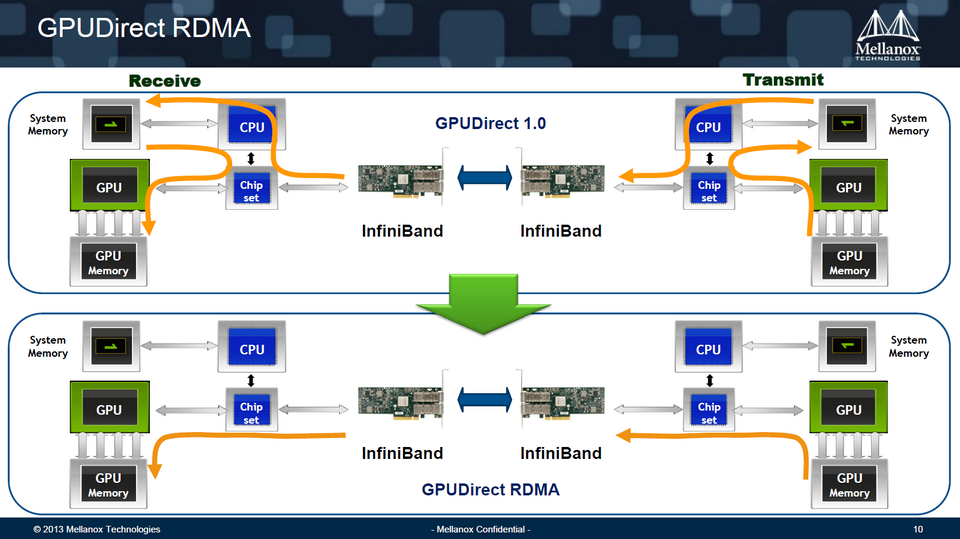
RDMA sur GPUDirect : les bonnes pratiques des pros (S3504)
Présentée par Mellanox, cette session rentrait dans les détails de l’optimisation des interconnexions entre GPUs dans les clusters hybrides. Suite à la sortie de Kepler, une partie de la présentation était également consacrée à l’implémentation de RDMA sur GPUDirect qui permet la communication directe entre GPU et interface réseau en mode peer-to-peer, donc en évitant l’étape CPU. Des conseils très utiles si vous avez adopté les derniers accélérateurs Kepler.

Accélérer l’analyse réseau avec des GPU (S3146)
Compte tenu de l’augmentation en volume et en rapidité des trafics réseau, ça devait arriver : on utilise maintenant des GPU pour accélérer les processus de monitoring, notamment lorsque les analyses doivent se faire sur les paquets de datagrammes. A la fin de cette session, on pouvait envisager de construire son propre analyseur à partir de l’expérience rapportée par les deux intervenants.
D – DEVELOPPEMENT ET PROGRAMMATION
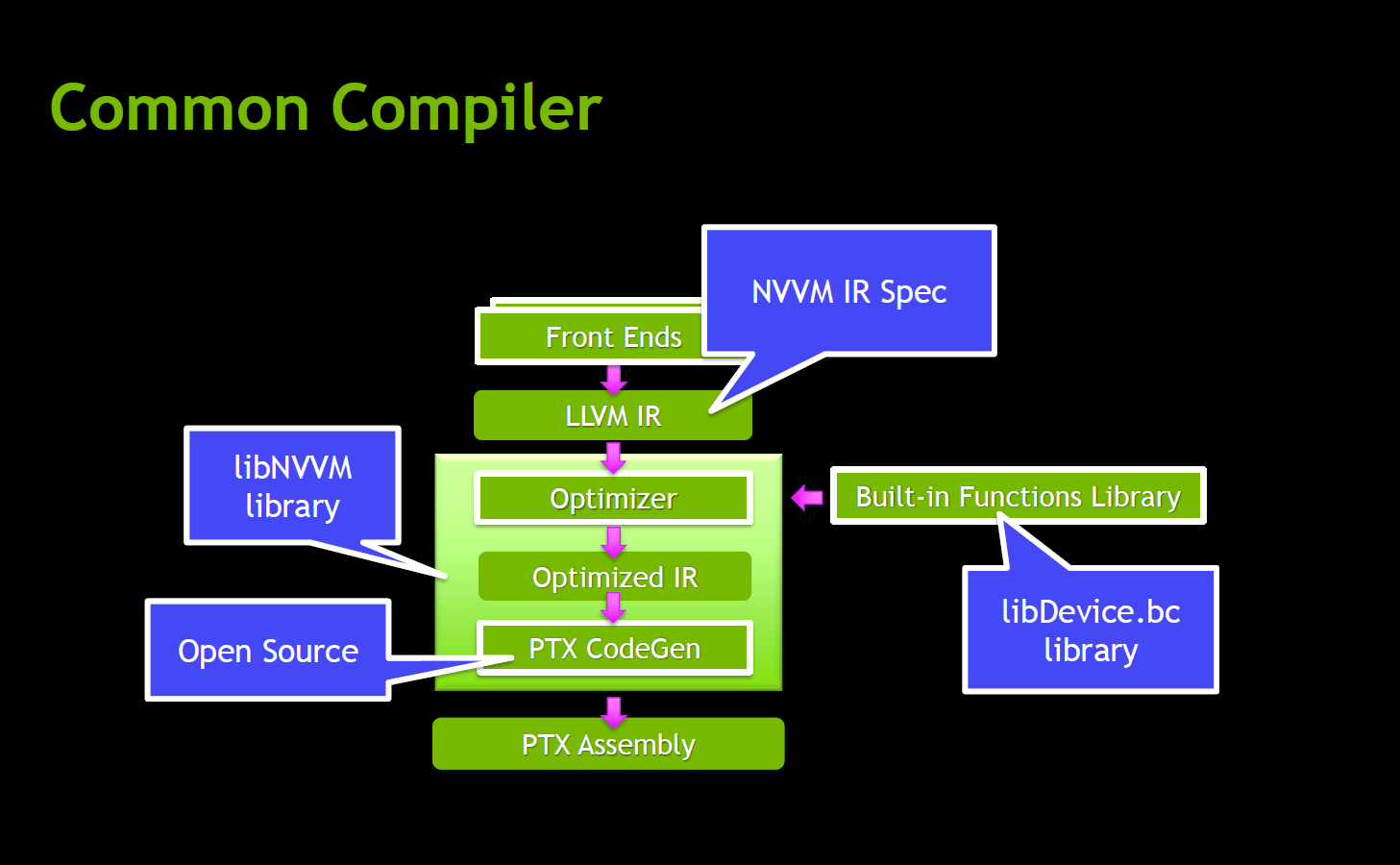
Créer des langages accélérés spécifiques à un domaine (S3185)
Les DSL (Domain-specific language) permettent d’affiner les applications scientifiques spécialisées et leur utilisabilité en bénéficiant de l’accélération GPU. Mais sans outil intermédiaire, l’exercice est souvent fastidieux. Grâce à libNVVM, ce n’est plus le cas, et cette session avait justement pour but de présenter la bibliothèque à travers plusieurs exemples montrant comment tirer profit du parallélisme dynamique et d’autres fonctions propres à CUDA.
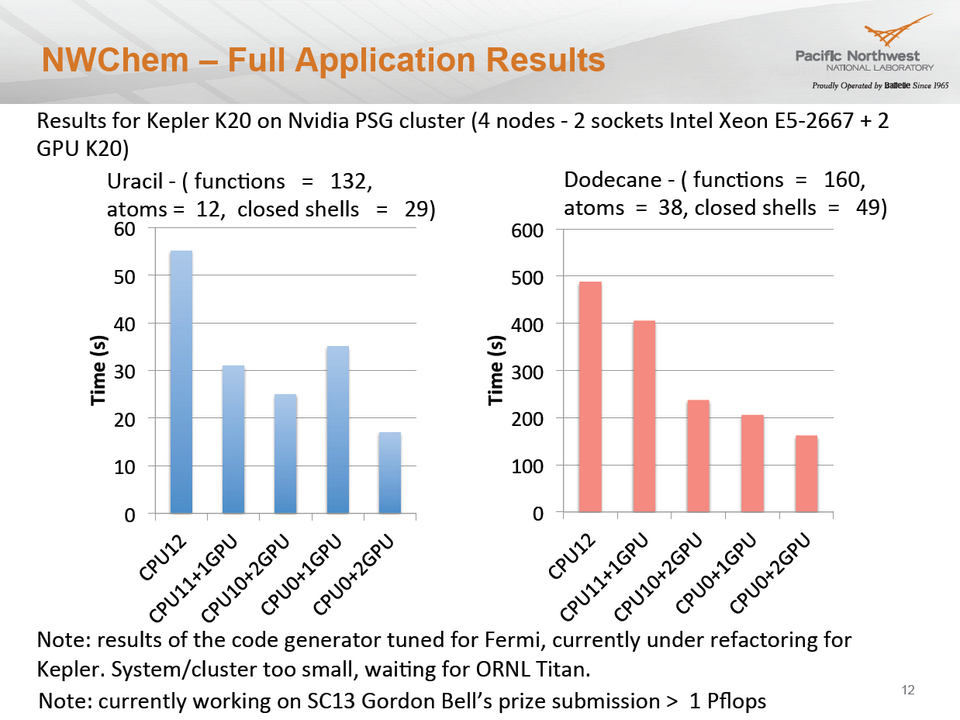
Améliorer les performances applicatives sur les très gros systèmes (S3289)
Après avoir passé en revue les techniques qu’ils utilisent pour accélérer des applications telles que NWCHEM, STOMP ou encore Paraflow, deux ingénieurs-chercheurs du Pacific Northwest National Laboratory ont présenté diverses approches d’optimisation à très grande échelle (plusieurs milliers de GPU) via les DSL, certaines bibliothèques et des runtimes basés sur des tâches – en insistant notamment sur les avantages que présentait l’utilisation d’OpenACC avec les codes sources legacy.

Aller (bien) plus loin avec OpenACC (S3215 – S3447)
Grâce à deux sessions distinctes animées par l’ami Stéphane Bihan, de CAPS Entreprise, et Michael Wolfe, de PGI, développeurs et scientifiques ont pu se familiariser avec les fonctions avancées du “langage”, découvrir un certain nombre de techniques d’optimisation efficaces et rapides, et comprendre leur grand intérêt dans les environnements mixant différentes architectures multi-cœurs. D’un grand intérêt pout quiconque touche de près ou de loin au HPC.
Développer en CUDA pour les plateformes ARM (S3493)
Cette session, menée par deux ingénieurs NVIDIA, proposait un état des lieux du développement CUDA sur ARM. Si vous avez l’intention d’utiliser cette plateforme low-power (aurez-vous même le choix à terme ?), ne manquez pas cette couverture complète des méthodes et des outils disponibles aujourd’hui.

Des flux pseudo-aléatoires en environnement GPU (S3204)
Jonathan Passerat-Palmbach, de l’UMR CNRS 6158, proposait une session ciblant les scientifiques ayant besoin de flux pseudo-aléatoires pour leurs travaux de simulation en environnements parallèles. La spécificité de ce sujet nécessite en effet des connaissances pointues, que Jonathan a rassemblé dans ShoveRand, une bibliothèque Open source qui permet également à l’utilisateur d’intégrer ses propres générateurs personnalisés.

Programmation GPU pour les développeurs .NET (S3145)
De par leur nature même, les langages MSIL ne conviennent pas à la programmation GPU optimisée. Mais un certain nombre d’initiatives, liées à une demande qui s’exprime partout, tendent à réunir les deux mondes. C’est le cas de CUDAfy.Net, un framework open source dont nous vous reparlerons bientôt en détails. C’est à lui que cette session était consacrée, avec des exemples de portage incluant des mesures de performances comparées.
Java et les GPU (S3218 – S3058)
Deux sessions marquantes traitaient de ce sujet qui, visiblement, intéressait beaucoup de monde. Dans la première, Scott Halverson, du laboratoire de Los Alamos, recensait les solutions disponibles (JNI, JCUDA, etc.) pour bénéficier de l’accélération GPU à partir d’une grosse application Java. Dans la seconde, Phil Pratt-Szeliga, de l’université de Syracuse, présentait Rootbeer, un compilateur-traducteur permettant de sérialiser des graphes d’objets composites de sorte qu’ils puissent être accélérés par GPU. Compte tenu de ses performances, et sachant qu’il est disponible sous licence MIT, il n’est sans doute pas inutile de vous y intéresser.
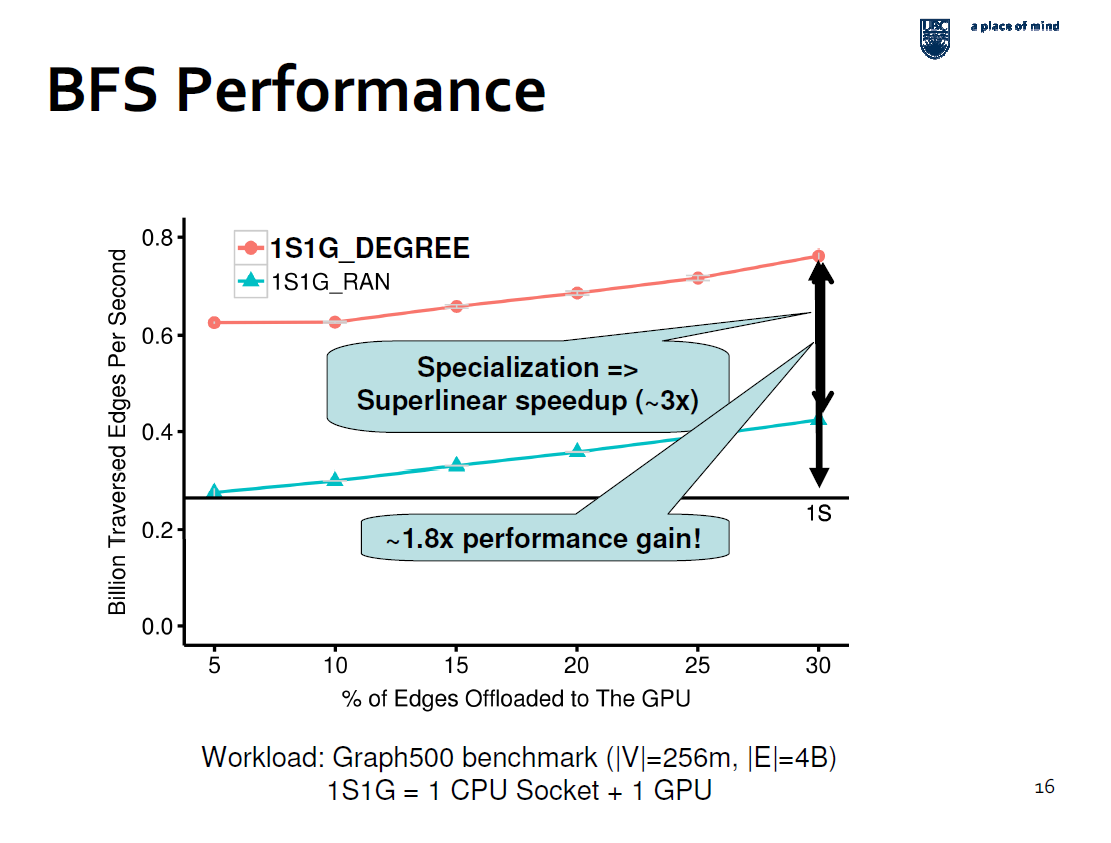
Accélérer le traitement des graphes sur les systèmes hybrides CPU+GPU (S3262)
Les graphes ne sont pas qu’un problème théorique. Quand on doit les utiliser pour des problèmes réels, on se heurte à de nombreuses difficultés liées à leur empreinte mémoire et au degré généralement élevé d’hétérogénéité dans la distribution des nœuds. Cette session avait pour originalité de montrer l’avantage qu’il y a à envisager des solutions sollicitant à la fois CPU et GPU pour leurs avantages respectifs.
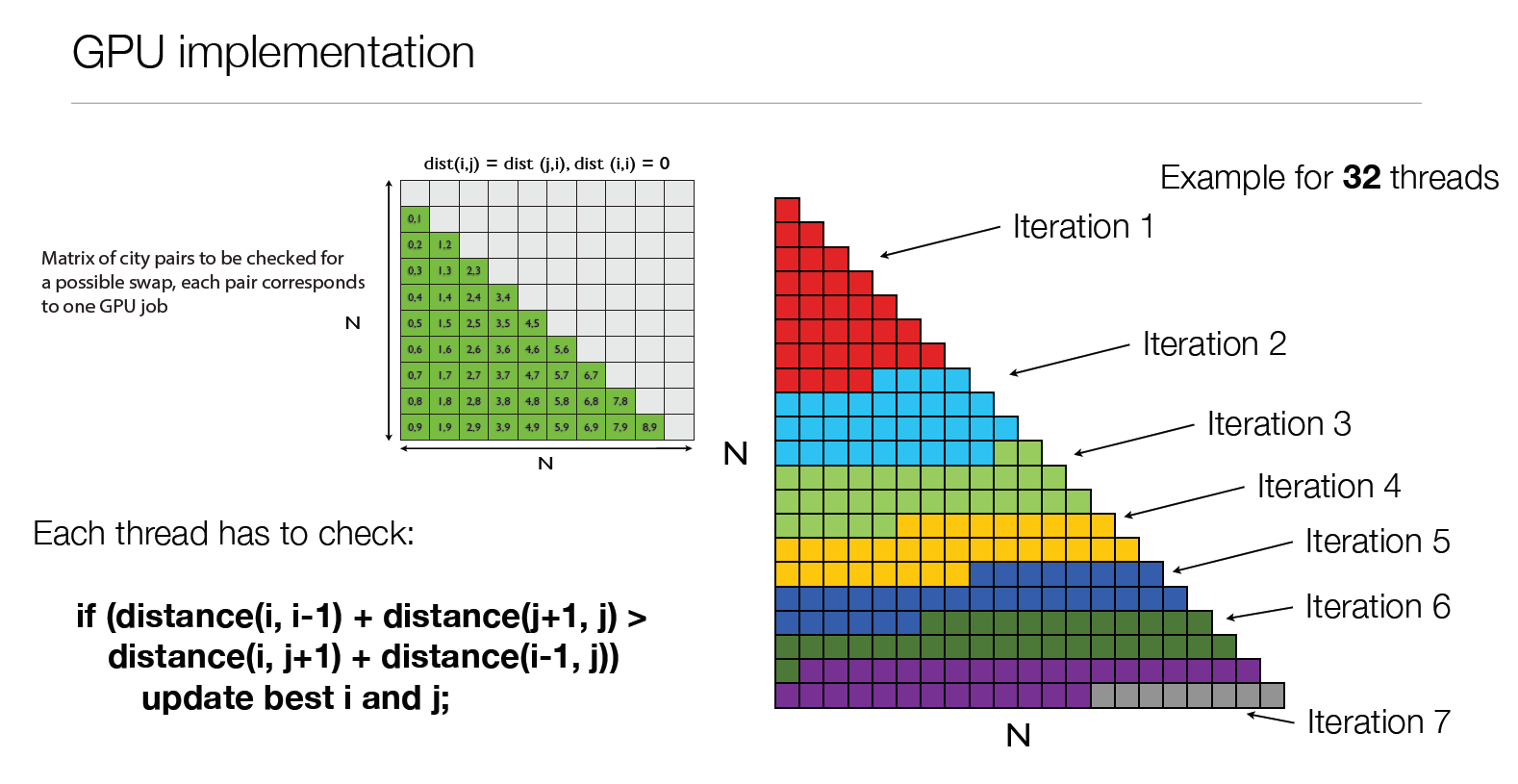
Quand le voyageur de commerce va 150 fois plus vite… (S3222)
S’il est un marronnier dans le domaine du développement, c’est bien le TSP (Travelling Salesman Problem). Kamil Rocki, de l’université de Tokyo, en présentait une implémentation accélérée par GPU. Elle se signalait par un gros effort d’optimisation sur la recherche locale, grâce auquel le gain en performance atteignait 150X par rapport à une version CPU (et encore, en n’utilisant qu’une simple carte graphique). Une session riche d’enseignements.
More around this topic...
Related articles










© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}