
Last week, the GPU Technology Conference (GTC) in Beijing was the occasion for Nvidia CEO Jen-Hsun Huang to unveil new comers to its Tesla accelerators lineup : the Pascal-based P4 and P40 GPU accelerators. Huang also took the occasion to announce new software to improve performance for inferencing workloads mostly used for applications like voice-activated assistants or spam filters.
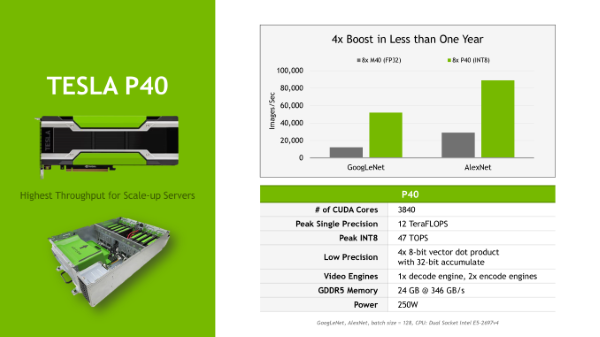
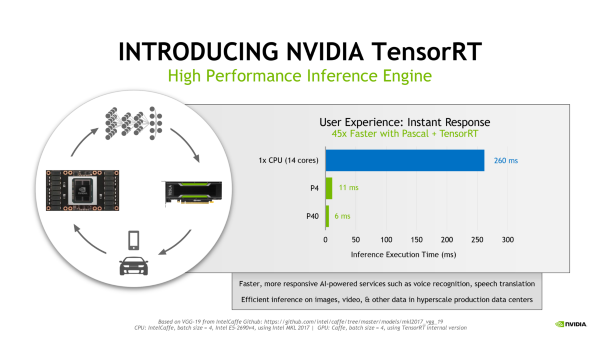
The new cards are packaged in the same form factor as the Maxwell-based M4 and M40 GPUs (and will fit into the same 250 watt server slots). But the difference is that the GPUs feature specialized inference instructions based on 8-bit operations. The GP104 GPU in the Tesla P4 accelerator uses a 16 nanometer FinFET process and has 7.2 billion transistors, more than the double that of the used in the prior generation Tesla M4 card The base clock speed on the CUDA cores is 810 MHz and the GPUBoost is set at 1.06 GHz. On its side, the GP102 GPU that powers the Tesla P40 accelerator card uses the same 16 nanometer processes and also supports the new INT8 instructions to make inferences run at lot faster. The GP102 has 12 billion transistors and a total of 3,840 CUDA cores. These cores run at a base clock speed of 1.3 GHz and can GPUBoost to 1.53 GHz. According to Nvidia the P40 achieved a 45x faster response than a E5-2690v4 Xeon and Depending on the inference workload, it can deliver somewhere between 4X and 5X the throughput of the M40 for the same price.
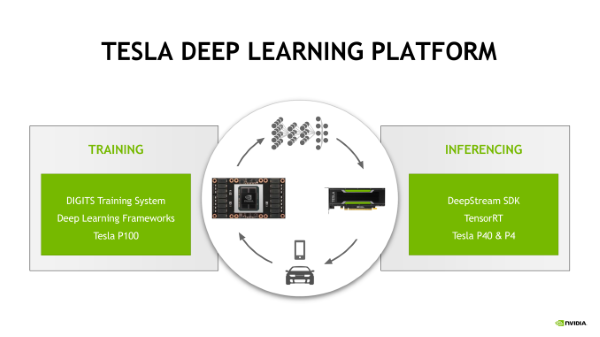
The tests that deliveres this results were run with an internal version of the company’s TensorRT library. The specificity being that the library takes neural nets, built with 32-bit or 16-bit operations, and adapt them for the GPU. “If there’s a GPU in the datacenter like the P4 or P40 then TensorRT will automatically recognize that and transform that neural net into 8 bit,” said Roy Kim, NVIDIA Product Manager for Tesla HPC business unit. “And TensorRT will take neural net and deploy it anywhere – it could deploy it in an embedded Jetson program for example.”
Nvidia also announced a new SDK to help speed video analytics workloads. This SDK called DeepStream has APIs for transcoding video onto various formats, preprocess those videos, and support for deep learning frameworks. A single Tesla P4 server (with two E5-2650 v4 CPUs) can simultaneously decode and analyze up to 93 HD video streams in real time with DeepStream. Nvidia made it clear that even the latest Broadwell CPUs are challenged by today’s complex inferencing workloads. But as we already mention, Intel is also preparing its game for Deep Learning and the next generation Phi processors codename Knights Mill will propably offer a better response to NVIDIA products.
The Tesla P40 is expected to be available in October followed by the P4 in November. All major manufacturers including Dell Technologies, HPE, Inspur, Inventec, Lenovo, QCT or Quanta Computer are ready to integrate the accelerators in their machines. The DeepStream SDK will be available through an invite-only closed beta program.
More around this topic...








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}