
Processeurs hybrides, convergence HPC / HTC, memory-centrism… la perspective de l’exascale excite la créativité technique de la communauté. Voici, à notre avis, les propositions d’architectures les plus porteuses.
Cet article fait partie du dossier En route vers l’exascale
C’est maintenant acquis, les plateformes de l’exascale ne ressembleront que de très très loin aux machines les plus puissantes d’aujourd’hui. Même les tenants de l’approche évolutive reconnaissent que des modifications architecturales de plus ou moins grande ampleur sont indispensables à un tel passage à l’échelle. Propositions structurelles, nouvelles technologies, les candidates ne manquent pas…
L’approche hybride
Celle sur laquelle la plupart des experts semble s’accorder, c’est l’association de processeurs de différents types. Un recensement rapide des grandes applications HPC fait apparaître qu’elles se composent souvent de deux types de segments : ceux qui sont limités en performance par leur nature mono-thread, et ceux qui sont limités dans leur débit par la matériel sous-jacent. Face à cette hétérogénéité, la solution logique consiste à faire travailler ensemble, le plus près possible les uns des autres, un petit nombre de composants optimisés pour la latence, comme les cœurs des CPU actuels, et un ensemble plus important de composants optimisés pour le débit (les cœurs des accélérateurs MIC / GPU). C’est ce que propose le projet de plateforme DEEP (voir plus loin), au niveau de l’architecture globale du système. Mais rien n’empêche d’envisager que ce mix puisse être implémenté directement au niveau socket,. Comment ? Par des “processeurs” hybrides qui, grâce à cette intégration, supporteraient nettement mieux la multiplication en très grand nombre que les CPU classiques. Il faudrait pour cela que l’industrie leur trouve une utilité autre que le HPC, de sorte que leur diffusion en masse puisse amortir leur développement. Peut-être du côté du mobile..?
Cette notion de convergence ou d’intégration, on la retrouve dans l’idée de combiner une bonne fois pour toutes les designs HPC que l’on connaît et les architectures de type “HTC” (High Throughput Computing) comme celle du CERN, par exemple. Pour les partisans de ce rapprochement, on obtiendrait le meilleur des deux mondes : une énorme capacité de calcul intensif exécutable sur un volume de données virtuellement illimité. Séduisante, cette proposition semble en train de faire son chemin. Sans trahir de secrets, on peut prévoir que des annonces dans cette direction devraient être faites au cours d’ISC’13 et du Forum Te@tec 2013, deux événements dont votre publication préférée est partenaire officiel. Il est probable que ces annonces entérineront un rapprochement effectif entre HPC et HTC, avec des roadmaps porteuses d’ambitions fortes. Pour qu’elles débouchent sur de nouvelles architectures intégrées disponibles commercialement, il faudra en revanche attendre encore un peu.
La mémoire au centre de l’architecture ?
Côté mémoire, ça bouge aussi. On peut déjà envisager l’industrialisation prochaine d’hypercubes de composants empilés placés à proximité directe des cœurs voire directement au-dessus de ceux-ci (cf. nos Actus et la 3ème partie de ce dossier). Voilà qui devrait régler pour un certain temps les problèmes de bande passante nominale. Mais ce progrès ne suffira probablement pas à homogénéiser les plateformes exa.
C’est en partant de cette analyse qu’une autre proposition architecturale commence à faire parler d’elle. Si l’on considère que l’exascale est synonyme de très gros volumes de données, pourquoi ne pas abandonner tout simplement le classique compute-centrism des plateformes actuelles pour passer à un design plus memory-centric ? Concrètement, l’idée serait de placer le sous-système mémoire au centre fonctionnel des machines et de considérer les processeurs comme des périphériques, ce qui supprimerait, de plusieurs façons possibles, les problèmes de bande passante globale pour le transfert de données. Cette petite révolution copernicienne, si elle suscite l’adhésion de la communauté, pourrait prendre un certain temps. Mais, après tout, 2020 n’est pas non plus pour tout de suite…

Autre concept novateur, celui développé par le projet EHA (Extremely Heterogeneous Architecture), présenté en décembre dernier à I-SPAN 2012. La cible, cette fois, c’est l’efficacité énergétique structurelle des cœurs de calcul. EHA reprend à son compte l’idée d’hybrider les nœuds, mais cette fois en associant des cœurs “general purpose” avec d’autres hyperspécialisés (GPUs, ASICs et FPGAs). Les cœurs génériques seraient chargés du contrôle et du traitement général de l’application, tandis que les cœurs spécialisés seraient fortement dédiés à l’accélération des segments applicatifs les plus souvent sollicités. Ainsi, lorsque tel ou tel segment est inactif, ou lorsqu’il n’a pas besoin d’accélération, le ou les composants programmés pour son exécution peuvent être éteints. Du point de vue purement électronique, cette approche ne manque pas de sens : on ne contraint pas l’accélération, mais on ne gaspille aucun Watt pour rien. Encore en développement théorique, EHA devrait prochainement proposer des résultats d’efficacité chiffrés à partir de simulations reproductibles.
L’exascale à partir de l’existant
Si ces approches n’ont pas encore réellement franchi le stade du tableau noir, il en est une autre, plus conservatrice, dont les premiers développements pratiques sont déjà en cours. DEEP (Dynamical Exascale Entry Platform), tel est son nom, a ceci de particulier qu’elle repose en grande partie sur des technologies existantes (CPU x86 et accélérateurs parallèles). Pour assurer leur passage à l’échelle, elle met en œuvre une architecture duelle dite “Cluster Booster”, qui regroupe les CPU en un Cluster classique et les accélérateurs en un second baptisé “Booster”. Dans la mesure où les accélérateurs sortent du périmètre des nœuds, les applications composées de kernels de nature différente peuvent exécuter côté Booster ceux qui supportent pleinement la scalabilité, et côté Cluster les autres.
Développé par le Jülich Supercomputing Centre et fortement soutenu par Intel, DEEP est motorisé par des processeurs Xeon et s’ouvre sur l’extérieur via des interfaces InfiniBand Mellanox. Dans le Booster, on trouve essentiellement des accélérateurs Xeon Phi interconnectés par un réseau Térabit en topologie torique 3D baptisé EXTOLL (et développé à l’Université d’Heidelberg). Le niveau de latence des échanges, inférieur à la microseconde, permet aux applications de tirer le maximum du sous-ensemble MIC.
Selon ses initiateurs, cette architecture est aujourd’hui la plus à-même de servir de base aux premiers systèmes exaflopiques, compte tenu de l’état actuel de l’art et du marché. Si les premières expériences sont concluantes, elle devrait bénéficier d’un refroidissement liquide à température ambiante qui optimisera son efficacité énergétique et facilitera la réutilisation de la chaleur captée. Une fois validée, la réalisation technique de l’ensemble du système (armoires, racks et lames) sera confiée à Eurotech.
Ne pas toucher aux applications
Au niveau logiciel, DEEP joue également la carte de l’innovation raisonnable. La pile devrait permettre l’exécution sans retouche des applications traditionnelles, et cela tant au niveau Cluster que Booster. Le système intégrera pour cela une version spéciale de ParaStationMPI, de ParaTech, qui supportera le réseau du Booster et sa topologie torique.
Afin de tirer le maximum des spécificités de cette architecture, une couche supplémentaire au-dessus de MPI est prévue. C’est elle qui assurera l’intégration des segments de codes à haute et à faible scalabilité, et permettra qu’elles soient exécutées sur le Booster et le Cluster, respectivement.
Reste à assurer la programmabilité de l’ensemble. Pour cela, un nouveau modèle de programmation baptisée OmpSs a été conçu (par le Barcelona Supercomputing Center) dans le but de permettre le découpage des applications en tâches. L’idée, bien sûr, c’est d’utiliser au mieux l’électronique disponible sur le Booster et sur le Cluster, mais également de faciliter la répartition des opérations et les échanges entre les deux bords de l’architecture. Un middleware, en cours de développement, sera chargé de la gestion des ressources matérielles sous-jacentes et autorisera, notamment, les entrées-sorties directes au niveau Booster.
DEEP, l’exascale conservatrice
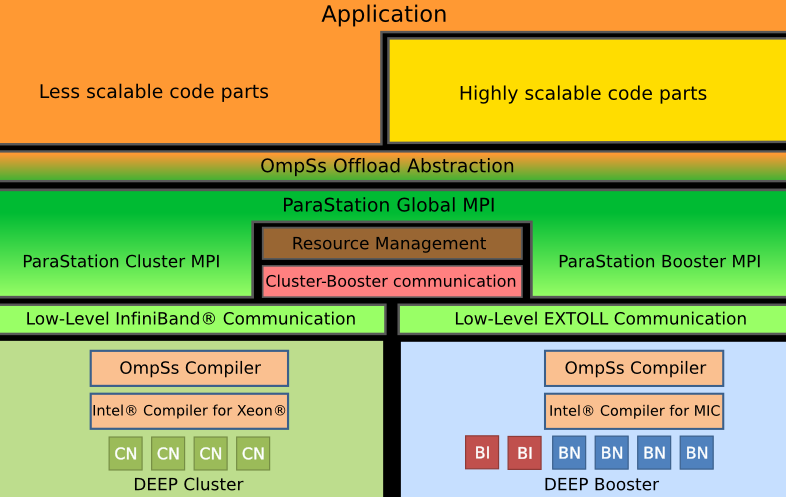
Mixant les concepts de cluster d’accélérateurs et de cluster avec accélérateurs, le projet d’architecture DEEP, fortement soutenu par Intel, se distingue par l’utilisation de technologies actuelles et un gros travail d’adaptation pour le passage à l’échelle. La figure ci-contre en résume l’idée générale : un cluster de CPUs doublé d’un second cluster d’accélérateurs x86 (“le Booster”) doté de son propre réseau d’interconnexions ultra-performantes. La figure 2 décrit sa pile logicielle, qui comprend notamment un middleware dédié à la gestion du Booster, un compilateur spécifique permettant la décomposition des applications en tâches “Cluster” ou “Booster”, et une API autorisant l’exécution des applications existantes telles quelles.
More around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}