
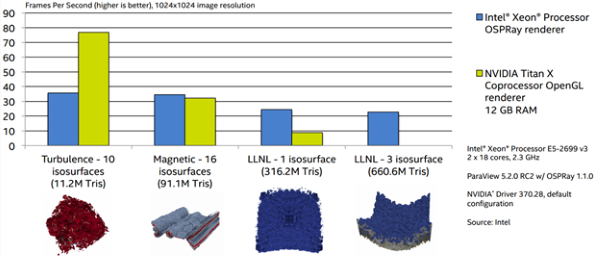
Figure 4: OSPRay vs. GPU Performance (Source: Intel)
Figure 4 compares the performance of OSPRay ray tracing on Intel E5-2699 v3 dual socket against an NVIDIA TitanX (Pascal) GPU running standard OpenGL rendering. Note that as the complexity and size of the 3D models increase, ray tracing overtakes the GPU’s OpenGL rasterization boding well for comparative performance as well as higher fidelity provided by ray tracing as model complexity increases. As the benchmark results below indicate, Intel Xeon Phi processors deliver strong performance on OSPRay as well, comparable to Intel Xeon processors, which bodes well for scientific visualization with very good performance per watt on the many Intel Xeon Phi clusters that are now being built or are in production. Many are now listed in the TOP500 list.
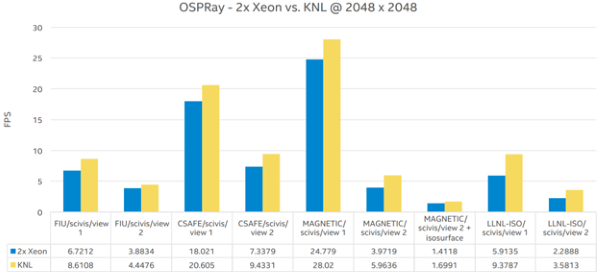
Figure 5: KNL delivers good performance (Source: Intel)
The Stephen Hawking Center for Theoretical Cosmology utilized ParaView with VTK powered by OSPRay to visualize a baseline 36 TB data set with a 600 GB memory foot print utilizing four Intel Xeon Phi 7230 processors and one Intel Xeon E5 v4 dual socket node. This visualization achieves 10 FPS over an Intel Omni-Path Architecture (Intel OPA) fabric interface. The Intel OPA fabric is also part of Intel SSF. Similarly, over 1000 Intel Xeon E5 processors v3 delivered a framerate of 15 FPS utilizing in-situ visualization of domain wall formation in the universe in an SGI UV-300 system. The timescale of the visualization was from the Big Bang until today, or 13.8 billion years. The memory footprint of this run was over 10 terabytes.
OpenSWR for raster graphics
Not just restricted to ray-tracing, SDVis also supports scalable and performant raster-based visualization – an area previously dominated by GPUs due to their optimized hardware for raster-based gaming.
The Intel SSF OpenSWR software is an OpenGL compatible software rasterizer that does not require modification of the visualization software. The source code is also freely available from mesa git master repository. Mesa is a very popular open-source library implementation of the OpenGL specification. The inclusion of OpenSWR in Mesa means that OpenGL rendering packages can now run OpenGL codes on general-purpose hardware with typically higher performance then the default “llvmpipe” package. Again, the uptake by scientific users has been strong. For example OpenSWR is used in production at organizations such as the Texas Advanced Computing Center (TACC) and Los Alamos National Laboratory (LANL)
OpenSWR is rapidly evolving to deliver even greater performance and more features. Jeff Amstutz (Software Engineer, Intel) discussed the OpenSWR roadmap at the Intel HPC Developer Conference. Amstutz put some hard numbers behind the performance claims. For example, OpenSWR recently achieved some dramatic performance improvements (80x) as compared to the default Mesa llvmpipe-based driver. This can be seen in the following benchmarks that were measured using VTK, the scientific toolkit behind the well-known ParaView and VisIt packages. Amstutz observed that “VTK is a good platform for showing comparative performance across typical visualization rendering workloads”. See the slides from his talk, “Update On OpenSWR: A Scalable High-performance Software Rasterizer For SciVis” for full benchmark specifications and disclaimers.
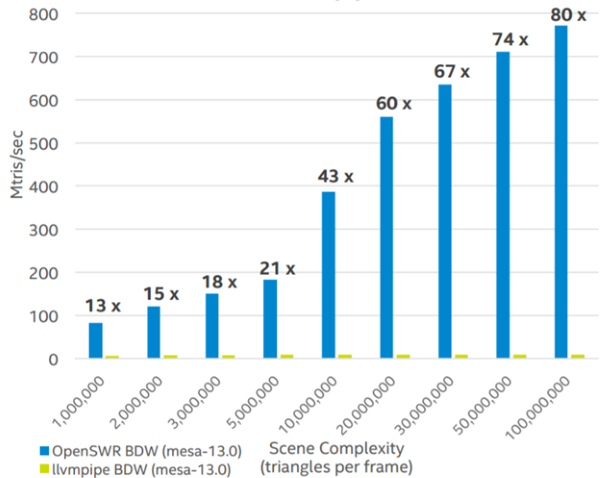
When discussing OpenSWR optimizations, Amstutz pointed out that Intel Xeon Phi processor optimizations are still in-progress, but that Intel Xeon Phi processor performance is good even though OpenSWR is currently using the shorter Intel AVX2 instruction set utilized by older Intel Xeon processors. Work is planned to refactor the pipeline stages to make use of the Intel AVX-512 instruction set. Amstutz also noted that OpenSWR will be the first Mesa software renderer with multi-sample anti-aliasing (MSAA) support. Overall, OpenSWR is being targeted for large raster rendering workloads as the team has already focused on “specific optimizations necessary for high triangle count workloads” that particularly aid in parallelism and vectorized culling techniques.
Summary
The visualization world has dramatically changed since 2014 due to technology advances and significantly improved performance in general-purpose computing hardware and SDVis software packages. Customer stories and benchmark results show that CPUs now outperform even the latest generation GPUs in visualization workflows. These results fly in the face of entrenched thinking, but the software is free so there is no barrier to everyone validating benchmark results.
As the figure below illustrates, in situ visualization eliminates massive amounts of data movement. The end result is that more detailed can be created faster – and even rendered at interactive framerates. Succinctly, the pictures tell the story.
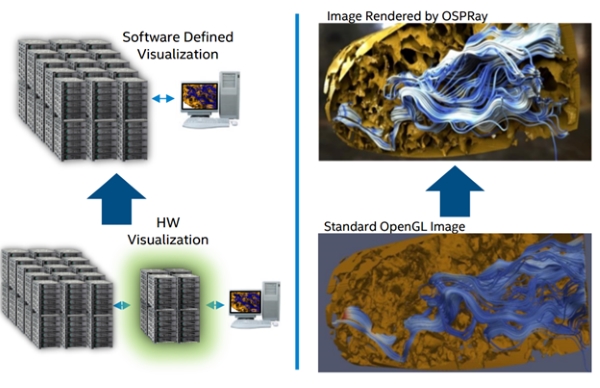
Figure 6: Eliminate massive data movements from your visualization workflows while increasing the fidelity and definition in your images (Source Intel. The data set for the images was provided by Florida International University)
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national labs and commercial organizations. He was also the editor of Parallel Programming with OpenACC. Rob can be reached at info@techenablement.com.
More around this topic...










© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















