
A solid-state drive (SSD) has many background tasks that occur at the drive level. Host Managed SSD (HMS) technology adds user controls to those drive level background tasks (via APIs) enabling system-level management of SSD operations. By coordinating the background tasks of each and every SSD in the pool, the entire population can share the burden of a given workload, delivering higher performance, greater functionality and better value.
The HMS platform developed by OCZ Storage Solutions will first support its Saber 1000 SSD Series and usable capacities of 480GB and 960GB in a 2.5” x 7mm enclosure. The technology includes a complementary Programmers Guide that enables developers and programmers to control each Saber 1000 SSD in the pool using HMS APIs (Application Programming Interfaces) and includes source code so that any developer or programmer can freely modify the APIs into their software stack. A complementary Reference Design is also available that provides a foundation from which any custom development could be built from.
Using new primitives, the management layer can control such flash functions as garbage collection, log dumps and other drive-level capabilities. On their own, each of these background tasks represents a considerable tax to drive performance. Therefore, the goal of HMS is to coordinate those tasks across the whole pool to remove those drive performance taxes.
Designed for hyperscale datacenters
As hyperscale and large datacenters continue to grow, the cost of administration will increase particularly as more SSDs are attached at the server level. HMS technology delivers central administration across the increasing pools of serverattached storage and represents a new area of SSD design that enables IT managers to better control storage administration costs while maximizing SSD pool performance and overall efficiency.
The Need For Host Managed SSDs
As SSDs gain increasing traction in the enterprise market, storage challenges are raised creating opportunities for technological innovation. Case in point, the Fresh Out-of-Box (FOB) performance of an enterprise SSD is not representative of performance when the drive is under constant load. The constant load is referred to as ‘Steady State’ and as the SSD achieves this status, user I/O is now competing with background operations for drive performance. As solid-state storage has matured as a technology, SSD vendors have produced even more efficient ways of managing background operations through improved designs and optimized firmware architectures. Part of that maturity is an emergence of software managed storage as the market looks to increase performance consistency while reducing cost. HMS is designed to align with that trend by giving the market more tools to manage storage exactly as they choose. In quick review, some of the background operations that SSD firmware manages include the following:
Garbage Collection:
Garbage collection is a background SSD process by which the SSD controller procedurally determines which flash cells have flagged-old data and either consolidates or erases those blocks to reclaim usable capacities. Only pages with good data in that block are read and rewritten into a previously erased page and those free pages that remain are now available for new data. As the operation releases blocks for incoming writes, it includes a copy of data pages from the blocks that have many dirty pages and erasures of these blocks. As a result, incoming read and write commands are pending to this garbage collection process that could increase latency responses up to a few microseconds. Therefore, the solution is to erase unneeded data in flash, which in turn, optimizes performance and reduces flash wear. As a drive’s usable capacity becomes full, garbage collection becomes an urgent process as there are fewer places to store incoming writes.
Latency:
Latency is a measurement that determines the time it takes for a packet of data to get from one designated point to another and assumes that data should be transmitted instantly with no delays. Within an enterprise network, a data packet may be subject to storage and I/O access delays from intermediate devices such as switches and bridges. Specific contributors to latency include mismatches in data speed between a server processor and input/output devices such as SSDs, HDDs and others.
When running write I/Os on an SSD over a sustained period of time, the write history evolves and a change in performance becomes evident. The latency changes on each read or write I/O never return to a level of consistency as delivered in the FOB state. Therefore, the solution is to deliver consistent I/O responses and more predictable, efficient I/O access across the system to reduce potential bottlenecks and help improve end-user productivity. From a TCO perspective, I/O consistency and predictability helps reduce overall power consumption and associated cooling costs, as well as maintenance and support costs.
Log Dumps:
All metadata changes within the Flash Translation Layer (FTL) are logged in device memory, SRAM or DRAM. Once this buffer is saturated, these changes are flushed into persistent media. The time between log dumps depends on the workloads, background garbage collection, trim operations, etc. In order to assure that a log dump will not delay incoming commands, methods are required to stop, resume and force log dumps for the host.
To achieve the best performance, the SSD controller logs all ongoing changes of write commands and for each measured time, dumps the changes to NAND flash memory. During this dump process, the controller is occupied and may cause delays to other commands resulting in performance spikes.
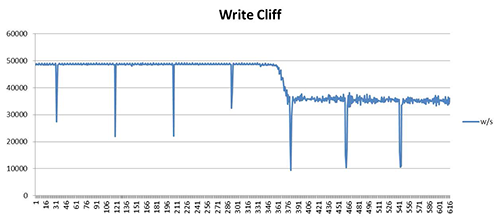
Write Cliffs:
A write cliff occurs when NAND flash memory erasures become slower to perform than actual write (program) operations resulting in performance drops and degradation of write operations. This means that if enough write operations are performed, eventually any finite overprovisioned buffer space will be exhausted and at that point, write operations MUST BE slowed down to the speed of the erasures.
The write cliff effect is most commonly seen in unmanaged SSDs once they’ve been operating for a period of time and occurs when all of the flash cells within an individual SSD have been written to at least once. As part of the Read-Erase- Write process, incoming data is buffered until the flash cell it is destined to be written to has been erased and the new data, along with any retained data (if the page is partially filled), is rewritten back to the flash cell.
Author’s Note: only entire pages can be deleted, not portions, which is why new data that includes partially filled retained data are rewritten back to the flash cell.
The write cliff causes degradation in write performance and often in overall performance (depending on the queue depth). The Figure 1 graph depicts the write cliff when a 480GB capacity Saber 1000 HMS SSD reaches full capacity of writes.
More around this topic...










© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}
{kind=link}