
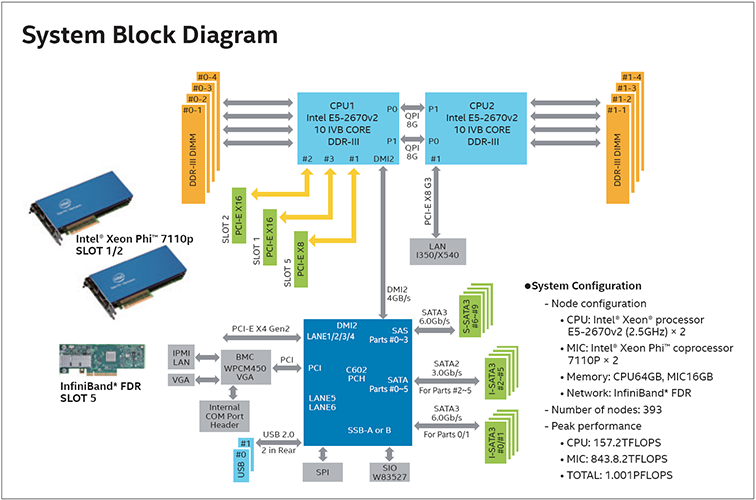
Ensuring high-speed performance with biased MIC board of 2 units with one CPUMIC and CPU
COMA, introduced by the Center for Computational Sciences is an abbreviation of ‘Cluster of Many-core Architecture processor’ The term is also derived from the English name of ‘Coma Berenices’, one of the typical clusters of galaxies. Collection of stars is a Galaxy (Many Core), and a collection of Galaxies (Cluster) has the image of a Galaxy cluster. At the same time, from the fact that it is a machine of the 9th generation Supercomputer PACS Series of the Center of Computational Sciences, the code name of PACS-IX has been used in combination. COMA is a parallel system equipped with 393 compute nodes where one compute node has two Intel Xeon processors E5-2670v2 (2.50GHz) having 10 cores per CPU and two Intel Xeon Phi™ coprocessors 7110P with 61 CPU cores. Peak computing performance of a single node is 0.4TFLOPS for CPU, 2.147TFLOPS for MIC, and 2.547TFLOPS together. Peak computing performance of the entire system is 157.2TFLOPS for CPU, 843.8TFLOPS for MIC, and 1.001PFLOPS together. In addition, all compute nodes are connected by a mutual network through a high-speed network (InfiniBand FDR), with a communication performance ten times that of Ethernet and run a uniform parallel processing between each compute node.
Lustre file server of total capacity 1.5PB by RAID-6 is used for storage and through the InfiniBand* FDR, it is possible to freely access from all compute nodes. ”Compute nodes consists of two MIC boards equipped with the Intel Xeon Phi coprocessor 7110P and a network board of InfiniBand FDR, next to one Intel Xeon processor E5-2670v2, ensuring high-speed communication capability between the coprocessor and the network board. The merit is that just one Intel Xeon processor E5-2670v2 alone can maintain a high-speed performance.” (Mr. Boku)
Uses 3 operating modes to support parallel processing of computational nodes
COMA operations can handle three jobs viz. CPU only, MIC only, and a combination of CPU and MIC and are intended to be used in
the following way.
- CPU only
To support the multi-core oriented programs (+MPI) of the previous generation super computer “2K-Tsukuba”, implementation of which has been stopped in February 2014. Uses 16 cores of the total of 20 cores in the Intel Xeon processor E5-2670v2. - MIC only
To use four cores of the Intel Xeon processor E5-2670v2 and two cores of the Intel Xeon Phi coprocessor 7110P (61 core ×2). Using the offload functionality provided by the Intel compiler for offload execution of some operations on MIC. - CPU+MIC
Monopolization of all computational resources (CPU+MIC) at the node level. To use hybrid programs in the MIC Native mode or Symmetric mode.Intel Linux version of the development tool “Intel Cluster Studio XE” is used in the programming environment, and researchers use the Intel FORTRAN compiler/Intel C++ compiler, and the Intel MPI library as per their needs to create the programs. Mr. Boku says, “Since free compilers can also be effective for some programs, we have developed an application system in which we do not specify a particular product for the compiler or library, but instead, allow the researchers to freely choose and use a compiler or library of their choice”. Used for development of computational science applications in fields such as particle theory and life science COMA can be used by researchers throughout the country without any charge under the “Inter-disciplinary joint utilization program” to support advanced scientific research in the fields of computational science and computational engineering. And, arrangements have also been made for its free use under the “HPCI program” promoted by the Ministry of Education, Culture, Sports, Science and Technology, and under the “Large scale general use program” which is used by researchers throughout the country free of cost.
Research scholars belonging to the Center for Computational Sciences are carrying out research by using “COMA”’s high speed parallel computing in the development of computational science applications in various fields such as the field of Particle Theory, the fields of Astrophysics, Life Sciences and Physical Sciences, and the fields of Material Sciences, Global Environment and Computational Information. Professor Boku has this to say about where to use the large scale parallel GPU cluster “HA-PACS” which first began operations in 2012, and where to use COMA.
“There is no classification based on the subject matter of the research. The researchers can choose as they like, and after careful examination of the subject matter of the research, they can make use of the interdisciplinary joint utilization program. But, HA-PACS require programs to be coded for GPU, as a result of which a large number of programs which run on it have been optimized for GPU. In contrast to this, COMA which uses Intel architecture is highly generic, and can run many more programs.”(Professor Boku)
By delivering lectures on high-performance computing to graduate school students, we develop competence in them to carry out computations according to the techniques of computational science COMA is presently also active in the education of students of the Center for Computational Sciences which promotes inter-disciplinary computational science. In the words of Professor Boku, “Today, the reality is that Japan is running overwhelmingly short of researchers in the scientific field who can write their own programs, when compared to the situation abroad. Therefore, in order to develop competence in many of our researchers so that they can write their own computational programs in various fields of research to perform computations according to techniques of computational science, we are conducting classes in high-performance computation literacy for graduate school students. Besides this, we are also running intensive courses on introduction to high performance computing for 40 to 50 graduate school students every year, and continuing with our initiatives to send out qualified persons with knowledge of high-performance computing”
And even in our “Global 30 (G30)” study program for overseas students who can only attend classes and obtain credits in English, we are planning to conduct classes on super computers such as COMA and HA-PACS directed at these overseas students in order to offer advanced educational services. In the Center for Computational Sciences, we plan to continue to use COMA in various fields of research and study the performance of many-core processors in order to gain knowhow and knowledge to help in the achievement of high-performance. In addition, we are planning to continue with research and performance evaluation in order to achieve the planned launch in 2105 of the super computer using a many-core processor to be jointly operated by the Center for Computational Sciences and the Information Technology Center, University of Tokyo.
Finally, Professor Boku says about Intel that “To implement EFLOPS, they are waiting for feedback based on verification and evaluation of super computing technology in various fields”. Intel will continue to support the development of inter-disciplinary computational science which is being promoted by the Center for Computational Sciences by improving the performance of the Intel Xeon processor and Intel Xeon Phi coprocessor, and making advancements in MIC architecture.
The Center for Computational Sciences, University of Tsukuba and the Information Technology Center, University of Tokyo have set up the “Joint Center for Advanced High Performance Computing (JCAHPC)”
The Center for Computational Sciences, University of Tsukuba and the Information Technology Center, University of Tokyo have set up a super computer system to be designed primarily by the teaching staff of both institutions in the Tokyo University Information Technology Center located in the Kashiwa Campus of the University of Tokyo used since April 2015, and have commenced activities for the launch of a new super computer system. This is the first time such an experiment has been conducted within Japan to set up such a facility and to jointly operate and manage a super computer.
3 centers for HPC Academic Research
The Center for Computational Sciences, University of Tsukuba and the Information Technology Center, University of Tokyo have implemented projects in the past to set joint specifications and procure super computers for each university through the “T2K Open Super Computer Alliance” consisting of 3 centers of the Academic Information Media Center of the University of Tokyo. The specifications of the T2K Open Super Computer Alliance are intended to reduce procurement cost and improve system performance through freedom from vendor dependence, and they are formulated based on the doctrine of “Openness” which represents openness of hardware and openness from user dependence. The establishment of JCAHPC is one step in this direction, and the design and development as well as the operation and management of the high-performance super computers are jointly carried out by the information centers of both universities with the objective of promoting state-of-the-art computational science.
New manycore policy
The policy framework which has been established for the design and development of super computing systems does not follow existing super computing products, but instead, uses many-core processors to design a state-of-the-art system, and also links the system to the OS, programming language, numerical computing library and other systems which form the core technology for the software during the design and development process.
More around this topic...
In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















{kind=link}
{kind=link}