
Comme promis, voici nos premières évaluations comparatives des deux accélérateurs parallèles présentés en détails dans notre numéro de mars. Compute, memory, latency… aucune des trois dimensions fondamentales de leur programmation n’est oubliée. Avec, à la clé, des chiffres surprenants et de vraies différences entre spécifications annoncées et mesurées…
Florent Duguet, PhD
CEO – Altimesh
EXCLUSIF : Téléchargez l’intégralité des codes sources
Que valent vraiment sur le terrain les derniers accélérateurs serveurs proposés par Intel et NVIDIA ? Pour le savoir, nous les avons soumis aux mêmes épreuves applicatives. A notre gauche, un Kepler K20X du commerce. A notre droite, une version de préproduction – détail important – de Xeon Phi SE10P. Leurs spécifications respectives sont détaillées aux tableaux 1.A et 1.B. Concurrentes sur le marché, ces deux cartes ont des vocations globalement similaires mais présentent d’importantes différences techniques. C’est en tenant compte très précisément de ces différences que nous avons codé les procédures d’évaluation proposées dans ce dossier.
Simples précisions sur les architectures
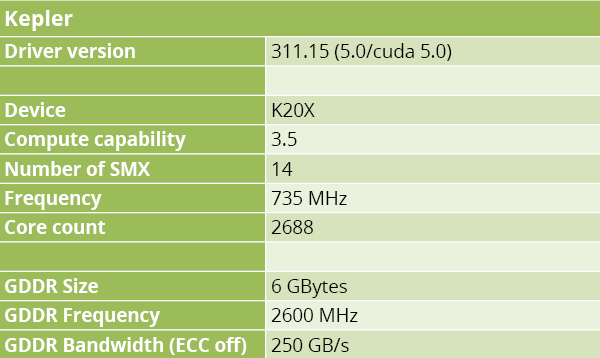
Dans les deux cas, les architectures exposent de très nombreuses unités multiply-add en virgule flottante cadencées à environ 1.1 GHz sur Phi SE10P et 735 MHz sur K20X. Pour y accéder, Kepler propose des appels API passant par un driver, ainsi que des extensions au langage C au travers de CUDA. Phi, pour sa part, embarque son propre Linux, mais ses unités de calcul sont également accessibles via une API. Voilà pour l’aspect “boîtes noires”.
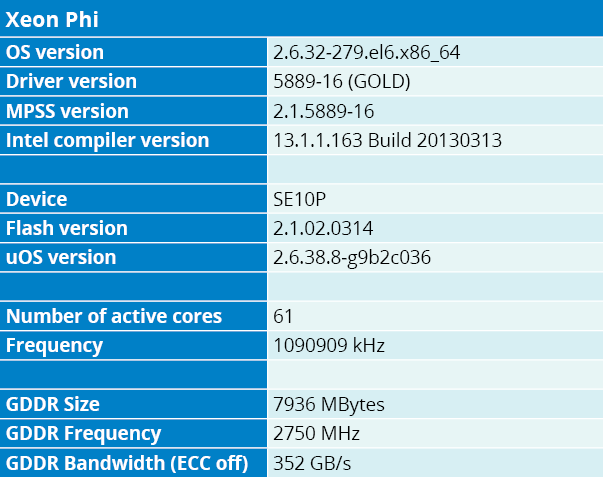
Rentrons maintenant un peu plus dans le détail de leur logique électronique. Pour résumer le gros dossier que nous leur avons récemment consacré, rappelons d’abord que K20X est constitué de 14 “SMX” (Streaming Multiprocessor Extended) – l’équivalent GPU d’un cœur de calcul. Un SMX dispose de ses propres caches, répartiteurs d’instructions et interface mémoire. Il regroupe 192 unités de calcul en simple précision, chacune de ces unités pouvant exécuter une opération FMA (Fused Multiply-Add) en un seul cycle d’horloge. Le résultat, sur le papier, c’est une puissance crête globale annoncée de 3,95 Tflops. En double précision, on descend à 64 unités de calcul embarquées, pour une puissance crête de 1,31 Tflops.
Dans l’architecture Kepler, la distribution des tâches s’effectue sur des warps de 32 entrées. Chaque entrée du warp ayant le même rôle, on peut se risquer à une analogie avec les unités vectorielles des CPU (les systèmes AVX offrant 8 entrées simple précision). Pour orchestrer le tout, quatre warp schedulers incluant 2 unités de répartition chacun sont présents par SMX. Précision importante, un warp scheduler est capable de lancer jusqu’à 2 instructions par cycle.
Rappelons également que les SMX de Kepler peuvent opérer sur plusieurs contextes en même temps. Le développeur bénéficie en théorie d’une certaine flexibilité dans la distribution des contextes, mais l’exécution n’est jamais plus efficace que lorsque les instructions sont les mêmes, sachant que les SMX ne disposent que d’un cache d’instruction unique. Au final, le nombre de threads exécutables simultanément se monte à 2048, avec la mobilisation de 64 warps. Masquer la latence de certaines opérations telles que les accès mémoire, par exemple, nécessite donc que le plus grand nombre de warps soit actif en même temps. On notera enfin, pour la bonne compréhension du code, que l’espace de registre disponible par SMX est de 2 Mbit. Cet espace commun devant être partagé entre les warps actifs, on aboutit à 1024 bits par entrée, soit en toute logique 32 registres de 32 bits, dans le cas où l’on mobilise un maximum de warps simultanément actifs.
Du côté de Phi, l’implémentation SE10P de l’architecture MIC (Many Cores) inclut 61 cœurs pouvant exécuter jusqu’à quatre threads simultanés, à l’instar des cœurs disposant de l’hyper-threading. Les opérations vectorielles disponibles sur les VPU 512 bits ressemblent structurellement à celles des jeux d’instructions SSE ou AVX mais forment un ensemble sensiblement plus complet (le guide de référence Intel compte plus de 700 pages). Par ailleurs, de nouvelles instructions d’accès gather/scatter facilitent les échanges avec la mémoire, une recherche complète pouvant par exemple être effectuée en une seule instruction.
Des analogies fonctionnelles
Malgré ces différences structurelles, on doit quand même, du point de vue programmation, envisager quelques analogies fonctionnelles entre les éléments clés inhérents à (ou découlant de) ces architectures. C’est l’objectif du tableau 2, qui ne doit pas être lu comme une référence de comparaison mais plutôt comme un aide mémoire de développement.
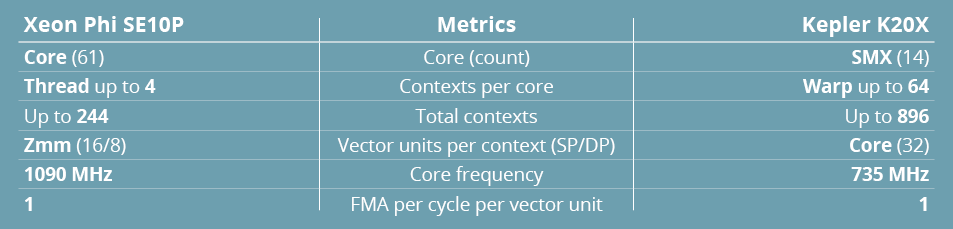
Notez que nous comparons les unités vectorielles aux warps et non au cœurs. C’est qu’en pratique, chaque warp présente un certain degré d’indépendance et peut être interrompu, exactement comme un thread peut l’être dans les cœurs hyper-threadés. D’où le décompte des unités vectorielles (à largeur équivalente) par contexte. On remarquera que les fréquences d’horloge se situent grosso modo au même niveau et que, tout comme dans Kepler, les unités vectorielles de Phi peuvent exécuter un FMA par cycle. Enfin, signalons que chacune des deux architectures embarque des SFU (Special Functions Unit) permettant d’exécuter des opérations particulières – exponentielles, trigonométrie, etc. – avec une efficacité optimisée. Ces unités et les fonctions câblées qu’elles intègrent n’étant pas directement comparables, nous les avons laissées de côté dans nos procédures.
Synchronisons nos montres
Ces observations matérielles expliquent que les calculs et les accès mémoires doivent de préférence être exécutés en parallèle. Ainsi, pour compenser la latence des accès mémoire, on utilise souvent plusieurs contextes parallélisés (warps actifs ou hyper-threads). De ce fait, quand on mesure les performances, on se fonde sur une chronométrie simplifiée où le temps d’exécution équivaut au maximum du temps de calcul et des temps d’accès mémoire. Très classiquement, les problèmes à résoudre se révèlent donc soit d’ordre compute (les temps de calcul sont supérieurs aux temps d’accès mémoire), soit d’ordre memory (rapport calcul / accès mémoire inverse).
Mais cette dualité se complique d’un troisième degré. Depuis l’Intel 80386, mémoire et processeur ne sont plus synchronisés, d’où latence. En pratique, cela signifie que certains algorithmes ne rentrent véritablement dans aucune des deux catégories précitées : les performances sont principalement fonction du temps nécessaire à ce que les données soient disponibles au traitement. Ces temps d’attente impactant fortement la bande passante mémoire, comme le décrit la loi de Little, il en résulte une troisième catégorie de problèmes, d’ordre latency.
Vous l’aurez probablement deviné, notre procédure de test est constituée d’une implémentation naïve mais complète de chacun de ces trois problèmes, ainsi que d’une implémentation adaptée aux spécificités respectives des deux accélérateurs. Pour le problème memory-bound, nous allons lire un large tableau de valeurs en virgule flottante pour les additionner. Pour le problème compute-bound, nous composons une fonction plusieurs fois, en sachant à chaque fois combien d’opérations en virgule flottante nous utilisons. Enfin, pour le problème latency-bound, nous accédons à un petit ensemble de données, nous le traitons et nous stockons certaines valeurs – cette suite d’opération n’entrant ni dans le domaine compute, ni dans le domaine memory.
Memory ou compute ?
Avant d’aller plus loin, penchons-nous sur les spécifications fonctionnelles des accélérateurs pour déterminer la limite théorique entre problèmes compute-bound et memory-bound (la configuration latency-bound n’apparaissant que sur des problèmes de moindre échelle où la latence ne peut être masquée par d’autres traitements).
Le tableau 3 résume ces spécifications et en déduit le nombre d’opérations en virgule flottante devant théoriquement être exécutées pour que le problème soit d’ordre compute.

On remarque qu’il faut, selon ces chiffres, environ 24 à 64 fois plus d’opérations de calcul que d’accès mémoire. Sachant qu’additionner deux vecteurs vers un troisième représente une opération en virgule flottante et trois opérations mémoire, on en déduit qu’il faut jusqu’à 200 fois plus d’opérations compute que d’opérations memory pour que le problème soit d’ordre compute. Cela montre que la plupart des problèmes réels traités en production sont d’ordre memory et que, soit dit en passant, le nombre de flops n’est pas le meilleur indicateur de performance pour nos deux accélérateurs.
Comme évoqué plus haut, nous avons prévu au minimum une version “naïve” – implémentation la plus simple possible du problème, sans aucun effort d’optimisation – et une version “optimisée” qui profite autant que possible des ressources matérielles et logicielles dont nous disposons. Les performances des versions naïves donnent une indication de comportement des deux accélérateurs face aux premières constructions algorithmiques qu’on leur soumet. Les performances des versions optimisées visent à montrer ce que l’on peut attendre d’un effort d’affinage significatif, et ont pour vocation de traduire ce que la plateforme – la vôtre, si vous les réutilisez – peut donner de meilleur.
Le test memory-bound
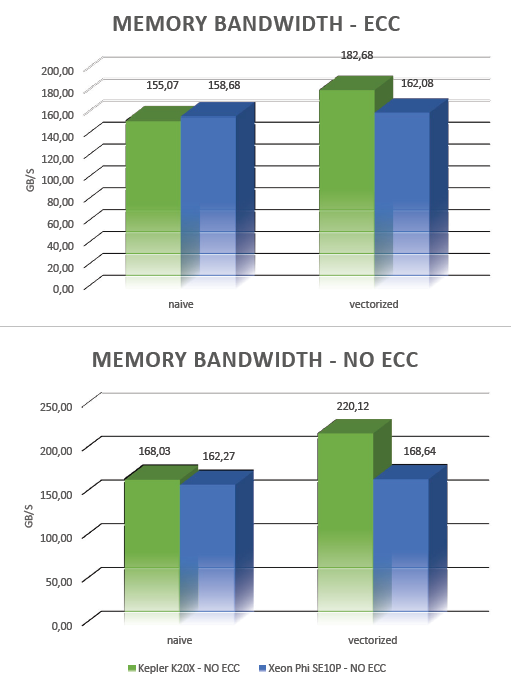
Le pseudo-code du listing 1 résume l’idée générale : on initialise un tableau de centaines de millions de floats, on en lit les valeurs puis on les additionne avant de stocker des sous-sommes dans un tableau plus petit. Le focus, ici, porte sur la bande passante en lecture mémoire, sachant que l’on essaye de lire ces données de la façon la plus efficace possible.
Pour Kepler, trois implémentations :
1 – La première, naïve, accumule les données à partir d’une lecture directe. Cette première approche n’implique aucune modification sur un code existant.
2 – La deuxième utilise des blocs de 128 bits pour lire les floats 4 par 4. Cette approche nécessite à la fois la vectorisation et l’alignement des blocs de lecture. Notez à ce propos qu’un test d’alignement à l’exécution, par rapport aux gains qu’il induit, n’est pas outre mesure pénalisant sur les temps globaux d’exécution.
3 – La dernière utilise __ldg pour épargner le cache L2, et mobilise le canal de cache de textures. Elle requiert, en plus des aménagements du point 2, que les opérations soient effectuées en mode read-only.
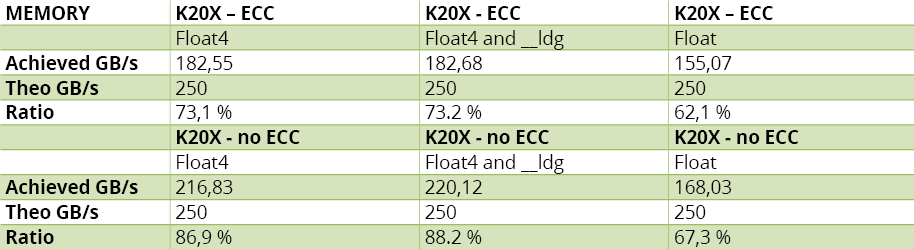
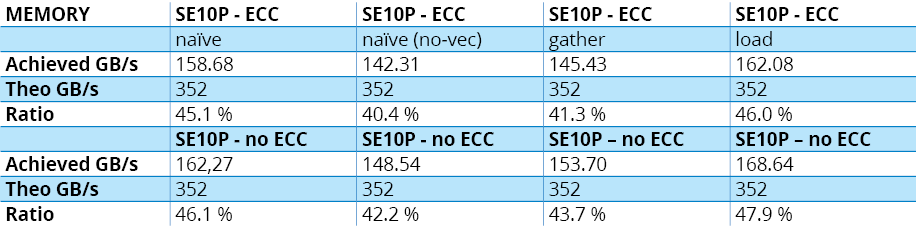
Les résultats sont reportés au tableau 4.A, qui montre que l’implémentation naïve donne déjà de bons résultats. En version optimisée, on ne gagne que 15 % – ou 24 % avec l’ECC désactivée.
Pour Xeon Phi, quatre implémentations :
1 – Version naïve – on laisse le compilateur effectuer lui-même une vectorisation automatique.
2 – On désactive la vectorisation explicitement (simulation de l’impossibilité pour le compilateur de vectoriser le code).
3 – On utilise _mm512_i32 gather_ps pour charger les données de façon non alignée. Cette implémentation requiert une vectorisation.
4 – On utilise _mm512_loa d_ps pour charger les données à partir d’adresses alignées.
Les résultats sont reportés au tableau 4.B. On observe que l’implémentation naïve avec vectorisation activée donne des résultats similaires sinon meilleurs que l’implémentation “gather“. Voilà qui confirme que le compilateur fait correctement son travail. Dans l’implémentation 2 avec vectorisation désactivée, on note une perte de performances proche de 5 % – seulement.
Le test compute
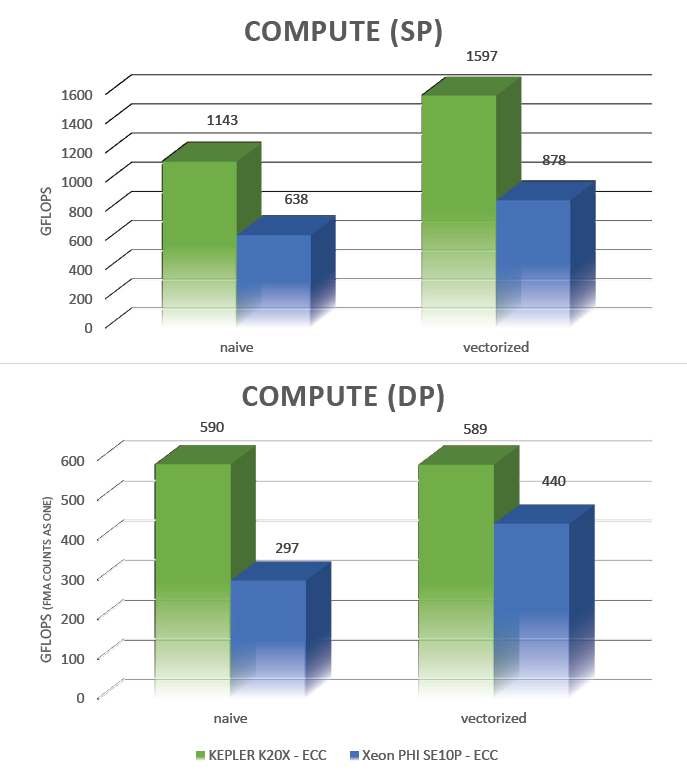
Pour ce test, nous sommes partis d’une approximation de la fonction expm1, très utilisée en finance pour calculer des produits de taux. Cette approximation consiste en une addition (add), deux multiplications (mul) et cinq multiplications + additions (madd). Nous composons ensuite la même fonction 12 fois, ce qui donne des résultats stables pour les valeurs positives inférieures à 1/3. Au total, on a donc 12 add, 24 mul et 60 madd par instruction, ce qui place clairement l’algorithme dans la catégorie compute-bound. Le pseudo-code est indiqué au listing 2.
Point à noter avant de décrire nos implémentations, il existe des cas applicatifs où l’opération madd ne peut pas être utilisée au mieux de ses spécificités. Sachant que la plupart des architectures exécutent madd sur un seul cycle, ou au moins sur le même nombre de cycles que add ou mul, nous la considérons ici comme une flop unique. Dans la suite du document, nous calculerons la puissance des différentes architectures à la lumière de cette observation, donc une puissance nominale de moitié par rapport aux spécifications.
Pour Kepler, deux implémentations :
1 – Les floats sont traités un par un.
2 – Cette version vectorisée traite quatre éléments simultanément. Dans les deux cas, nos tests portent sur des valeurs simple (32 bits IEEE-754) et double (64 bits) précision.
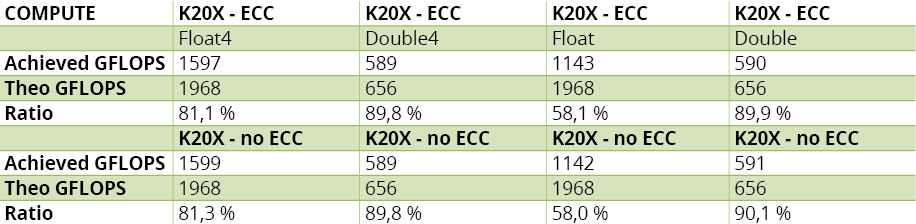
Les résultats sont reportés au tableau 5.A, qui montre que le niveau d’utilisation des ressources est excellent, et ce avec ou sans vectorisation. On remarque cependant que le niveau en SP sans vectorisation est assez moyen. Il faut se rappeler que les 192 cœurs des SMX peuvent être organisés en six ensembles de 32 unités (chaque ensemble traitant un warp). Cela signifie que le système atteint son niveau d’utilisation maximal lorsque six warps exécutent leurs instructions sur le même cycle d’horloge. Sachant que nous ne disposons que de quatre warp schedulers, il faut pour cela qu’ils lancent deux instructions sur le même cycle. Les opérations scalaires de notre implémentation naïve ne permettant pas au système de mobiliser complètement les ressources disponibles, le taux d’utilisation hard reste peu élevé. La vectorisation, c’est-à-dire le traitement de quatre floats par instruction, nous permet d’atteindre un niveau d’utilisation satisfaisant, ce qui confirme l’utilisation du parallélisme au niveau instruction (Instruction Level Parallelism), avec un taux d’utilisation des ressources supérieur à deux tiers.
Pour Xeon Phi, deux implémentations :
1 – Traitement naïf.
2 – Implémentation vectorisée basée sur les instructions natives et l’utilisation des registres m512. Dans cette approche, nous mobilisons deux registres m512 par entrée, ce qui aboutit à 32 entrées float par vecteur, pour obtenir les meilleurs résultats possibles. Par ailleurs, le processeur étant de nature “in-order“, nous avons ajouté quelques instructions de cache prefetching pour optimiser l’alimentation en données, d’où le niveau de performances global.
Les résultats sont reportés au tableau 5.B. Remarquez que lorsque l’on demande au compilateur de vectoriser, les performances, de niveau très correct, sont toutefois moins bonnes qu’avec une vectorisation manuelle. Ainsi, lorsque le code est vectorisé par des instructions intrinsèques, on arrive à un niveau d’utilisation de plus de 80 %, similaire à celui de Kepler.
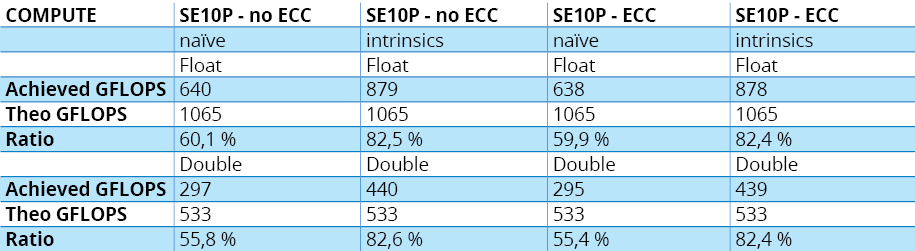
Les graphiques ci-dessous montrent que, en simple précision, bien que l’implémentation Kepler naïve manque de parallélisme au niveau instructions, les résultats sont assez bons. La version vectorisée, quant à elle, est vraiment excellente. En double précision, Kepler se révèle meilleure que Xeon Phi dans les deux implémentations naïve et optimisée. On peut même observer que la version naïve sur Kepler fait mieux que la version optimisée sur le modèle de préproduction de Phi que nous avons utilisé. N’oublions pas toutefois que les algorithmes réellement compute-bound ne sont pas légion ; si nous avions composé notre fonction huit fois au lieu de douze, par exemple, le problème retombait directement dans la catégorie memory.
Le test latency
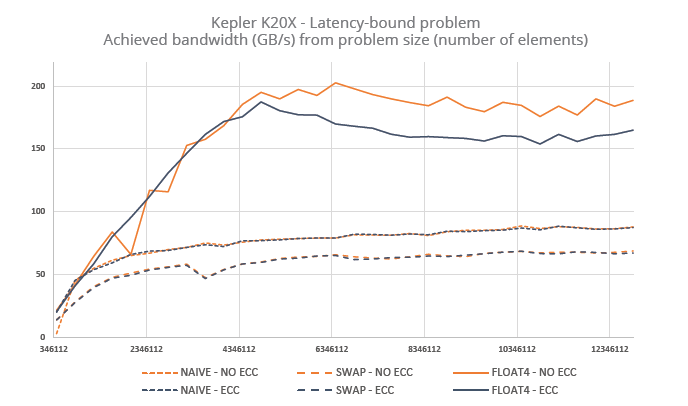
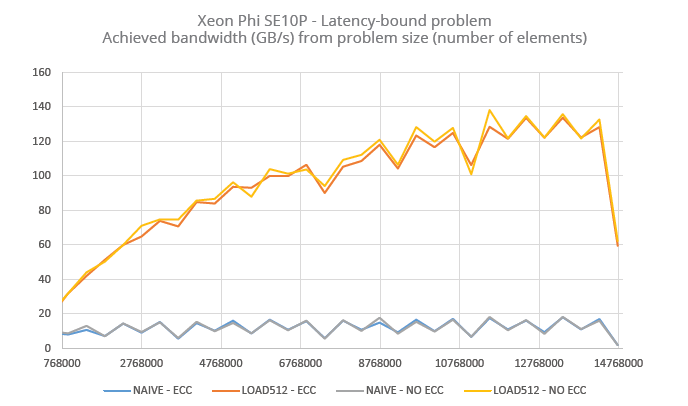
Pour tester l’aspect latence, nous avons utilisé l’exemple d’un accesseur sur une table de référence, la recherche n’étant prédictible ni par le compilateur, ni par le matériel. Le nombre d’itérations est restreint, pour bien mettre en évidence la latence des opérations de lecture. Notez que l’index sur la table est le même pour un groupe de valeurs, ce qui conduit à un axe de vectorisation naturel. Le pseudo-code est indiqué au listing 3. Pour chaque architecture, nous avons utilisé la meilleure taille de tableau possible compte tenu de la distribution minimale des opérations.
Pour Kepler, trois implémentations :
1 – Codage naïf.
2 – Permutation des boucles.
3 – Utilisation de __ldg et traitement des entrées par groupes de huit.
Pour Xeon Phi, deux implémentations :
1 – Codage naïf.
2 – Implémentation intrinsèque avec chargement d’un vecteur de 512 bits complet à chaque itération.
Les graphiques ci-dessous montrent les résultats obtenus avec chacun des deux accélérateurs.
Retour sur les chiffres flops / memops
A la suite de ces tests, il nous a paru pertinent de proposer une variante au tableau 3, qui résumait les spécifications de performances annoncées par Intel et NVIDIA. Le tableau 6 reprend donc la même matrice, cette fois avec les performances relevées à l’issue de nos tests (entre parenthèses figurent les chiffres annoncés). Cela ne vous aura pas échappé, les niveaux de bande passante mesurés ne sont pas exactement les mêmes – loin s’en faut. De plus, il apparaît que les flops annoncés ne sont pas nécessairement disponibles. Compter les FMA comme une flop unique semble d’ailleurs d’autant plus pertinent que de nombreux algorithmes ne mappent pas facilement sur ce type d’opération.

On voit par ailleurs que le ratio flops/memop – qui détermine si tel algorithme est plutôt compute-bound ou plutôt memory-bound – reste assez élevé, et cela qu’on travaille en simple ou en double précision. Cela dit, si l’application utilise quelques fonctions transcendantales, elle pourra être considérée comme compute sur Phi, alors qu’elle pourra rester memory sur Kepler.
Notes techniques
Plusieurs techniques ont été abordées dans ce dossier à propos des différentes implémentations de nos procédures d’évaluation. Il nous a semblé nécessaire de préciser certains points les concernant :
– Vectorisation
Le passage d’une opération scalaire à la même opération sur un vecteur (de taille fixe – et petite, si possible) nécessite un refactoring complet des algorithmes, et un travail supplémentaire pour les instructions de branchement. Son impact sur l’écriture du code est important, sachant que la performance du code dépend très largement de l’utilisation des instructions intrinsèques. Si l’effort de vectorisation est évidemment payant avec nos deux accélérateurs, il l’est également sur d’autres plateformes, notamment les CPU bénéficiant du jeu d’instructions AVX.
– Alignement
On parle ici du déréférencement de pointeurs. Idéalement, les accès mémoire ne devraient se faire qu’à partir de blocs de taille adaptée à l’accélérateur et sur un espace d’adressage à offset fixe. Gérer l’alignement est assez simple sur de petits exemples mais devient nettement plus délicat sur des applications réelles, notamment lorsque les index des tableaux dépendent de calculs complexes. Dans tous les cas, la bonne pratique consiste à en créer les conditions. Nos tests montrent qu’un test d’alignement dynamique ne ralentit pas les opérations outre mesure avec Kepler, de même que l’utilisation d’index (gathering) sur les chargements alignés avec Xeon Phi.
– Assertion read-only
Lorsque l’on accède à la mémoire, on peut supposer qu’aucune autre entité de l’application ne modifiera les données lues pendant l’exécution de la fonction ou du sous-programme. L’intérêt de cette condition, c’est qu’elle permet de simplifier les opérations pour les accélérer. On peut automatiser cette assertion dans certains cas ; dans les autres, le programmeur doit structurer son code de façon à ce que le compilateur puisse l’inférer.
More around this topic...


In the same section







© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.




















