
Les chiffres sont là : la production de données scientifiques est en croissance hyper-exponentielle. Ce déluge annoncé implique une adaptation en profondeur des systèmes, des applications mais aussi des pratiques de la recherche.
Cet article fait partie du dossier En route vers l’exascale.
On a longtemps considéré les applications data-intensive comme triviales. Peu complexes d’un point de vue technique, ne nécessitant pas de ressources de calcul démesurées, utilisant des structures de données classiques (quelle que soit leur volumétrie), elles n’intéressaient pas la recherche informatique qui de ce fait les reléguait à une sorte de second rang, loin derrière l’élite des grands problèmes qui occupent le monde scientifique. Cette époque-là est terminée.
Né en même temps que les réseaux sociaux et le marketing numérique se développaient à l’échelle mondiale, le concept de “Big Data” s’applique aujourd’hui à un large éventail d’applications, notamment HPC. Avec l’idée désormais largement acceptée que des réponses à nos questions se trouvent probablement pour partie dans des données que l’on possède déjà mais qu’on ne sait encore ni traiter complètement ni corréler efficacement.
+ 4300 % par an
Ce “data deluge“, comme disent nos amis américains, seul une analyse chiffrée permet d’en prendre la mesure. Globalement, on estime à 4300 % l’augmentation annuelle moyenne de la production d’informations numériques d’ici 2020, horizon théorique de l’exascale. A cette date, le volume global de données analysables devrait atteindre environ 35 zettaoctets, soit 35 milliards de téraoctets. Voilà pour le monde IT en général.

Pour le domaine HPC plus particulièrement, il est intéressant de regarder à quel niveau de production d’information arrivent aujourd’hui les principaux domaines applicatifs. Une intéressante étude publiée par des chercheurs de l’Université d’Oxford, de l’Université d’Indiana et de Microsoft permet d’apprécier la complexité des problématiques auxquelles on doit dès à présent faire face. Après avoir classé les champs d’applications en 3 catégories (observation, expérimentation, simulation), les auteurs relèvent par exemple que, tous les ans, l’imagerie médicale produit 1 exaoctets de nouvelles données, la surveillance de la Terre 4 pétaoctets, le LHC 15 Po, la modélisation du climat 400 Po et le séquençage du génome 700 Po – mais 10 Eo estimés d’ici 2020. Jusqu’ici, le principal défi a été de produire ces données. Désormais, il est de les analyser.
La fin de l’affinité

Cette situation se complique d’un gros degré quand on prend en considération l’évolution fonctionnelle des applications qui font, in fine, le HPC. Jusqu’à récemment, la majorité des codes se caractérisait par des points communs qui les rendaient exécutables sur des plateformes d’architecture classique : parmi eux, citons une relative affinité spatiale et temporelle, la possibilité de faire tenir les problèmes en mémoire vive et des datasets principalement statiques. Aujourd’hui, les acquis résultant de ces applications changent la donne : les données deviennent dynamiques, de sorte qu’elles perdent de leur affinité et qu’à partir d’un certain niveau de complexité, les problèmes ne tiennent plus en mémoire vive.
On doit donc, en plus des contraintes de programmabilité inhérentes à la mise à l’échelle, ajouter aux applications des fonctions spécifiquement dédiées à la gestion des données en entrée comme en sortie. Selon le type d’applicatif et en fonction de l’état de l’art, la liste est longue : quantification de l’incertitude dans les données elles-mêmes, leurs modèles et leurs méthodes ; modélisation, simulation et analyse de réseaux étendus ; automatisation de l’analyse et si possible de la découverte a posteriori, c’est-à-dire en phase de stockage…
De nouvelles compétences pour les chercheurs
Cette approche proactive, qui détermine déjà un certain nombre de travaux en cours (cf. notre interview de William Jalby), on la retrouve évidemment dans l’industrie. Le Big Data a le vent du marketing en poupe et cela se traduit notamment par d’importants investissement en R&D de la part des grands fournisseurs généralistes (HP, Fujitsu, Dell…) ou spécialisés (DataDirect, NetApp…). Il est d’ailleurs intéressant de remarquer que ces recherches privées correspondent d’assez près aux recherches publiques. On relève ainsi trois grands axes de travail. Il y a d’abord l’accélération des entrées/sorties, avec pour objectif la démocratisation du To/s. Là, chacun se focalise sur des surcouches propriétaires à certains systèmes de fichiers distribués, surcouches permettant de hiérarchiser le stockage, y compris à distance, avec plus d’efficacité. Plus intéressant techniquement, la convergence d’infrastructures vise à combiner des technologies de calcul et de réseau pour permettre le pré- et le post-traitement de routines d’analyse natives à l’intérieur même de l’infrastructure de stockage. Enfin, dans tous les labos, on fait la chasse aux composants, en partant généralement du principe que la mémoire de stockage remplacera avantageusement les disques durs pour ce qui est de l’efficacité énergétique, du coût de déploiement et de l’espace physique.
Il n’est donc plus permis d’en douter : l’exascale sera data-intensive ou ne sera pas. D’ici-là, la séquence des progrès matériels et logiciels en matière de gestion et de traitement de données scientifiques augmentera probablement la productivité de la recherche. Mais elle impliquera aussi l’acquisition de compétences complémentaires de la part des chercheurs. Il faut vous y résoudre…
Quand la recherche se réinvente
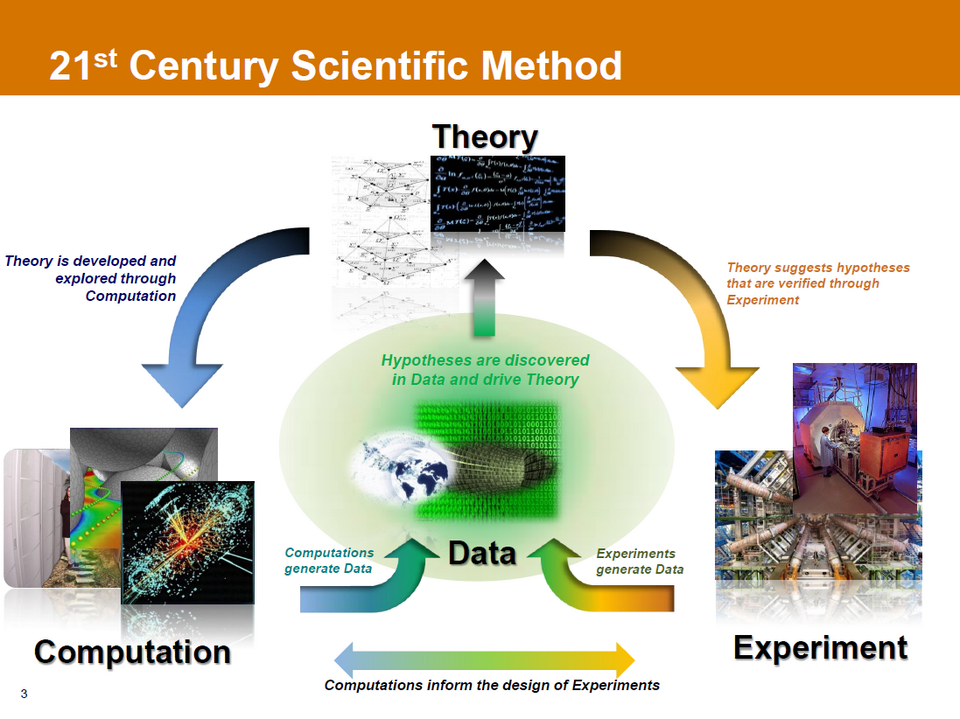
Le règne des données a commencé et, comme le montre ce schéma proposé par John Johnson du PNNL, c’est toute la méthode scientifique qui en est affectée. L’explosion des volumes d’informations produites devrait à terme conduire à une sorte de cyclisation des opérations de recherche, où calcul et expérimentation ne sont plus que deux phases transitoires qui rafraichissent à tour de rôle, de façon presque automatique, l’information dont on dispose et la théorie qui en découle.
Si nous employons le futur, c’est que la communauté n’en est pas encore là. Mais en fonction des interlocuteurs avec lesquels nous échangeons, la prise de conscience de ces transformations en profondeur a déjà eu lieu. D’un côté, on se demande encore si Linpack est bien approprié pour orienter les choix architecturaux en matière de développements matériels. De l’autre, on sait déjà que la seule mesure qui vaille – et qui reste à inventer – c’est celle qui, prenant en compte tout le spectre des problématiques orientées-données, permettra de comparer les systèmes en fonction de leur faculté à produire de la connaissance exploitable.
More around this topic...






© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}