
Sur la base de la roadmap Intel, l’industrie considère que les architectures actuelles devraient nous amener à l’exaflops à la fin de la décennie. Mais même chez le fondeur, on a bien compris qu’il était temps d’accélérer. “L’objectif ne s’accommodera pas des recettes appliquées ces dix dernières années” confirme Marie-Christine Sawley. “Il nous faut développer et soutenir des solutions innovantes, dans les domaine hard, soft et applicatifs. Pour atteindre des niveaux de puissance compatibles avec les exigences de l’exascale, le nombre de cœurs sur un même processeur va devoir progresser fortement.” Xeon Phi est la première concrétisation de cette stratégie, qui a l’avantage d’offrir une voie de développement balisée pour les utilisateurs d’architectures et de codes x86. La prochaine génération, attendue pour 2015, bénéficiera d’une gravure en 14 nm, donc d’un nombre de cœurs accru. L’accélérateur Phi “standard” devrait ainsi passer de 1 à 3 Tflops, soit un rendement de 14 à 16 Gflops par Watt.
Pour l’heure, l’avantage théorique reste toutefois aux GPU. L’architecture NVIDIA Kepler, dans son implémentation K20, affiche une puissance de 1,31 Tflops en double précision pour une consommation de 235 W, donc un rapport théorique supérieur à 5 Gflops / W. Mais on attend pour SuperComputing 2013 une version K40 (processeur GK110b), qui devrait selon toute vraisemblance faire sensiblement mieux.
Quand on regarde les classements, quand on se place en contexte de production réelle et à grande échelle, cet avantage se confirme – légèrement. Du côté TOP500, Titan affiche un rendement efficace supérieur à 2 Gflops / W, un peu meilleur que celui de Tianhe-2. Du côté Green500, les deux premières places de la liste de juin sont occupées par des machines hybrides x86 + GPU K20, toutes deux italiennes, qui avoisinent chacune les 3,2 Gflops / W. Mais elles ne boxent pas dans la même catégorie : à côté des 30 Pflops de Tianhe-2, les quelques 100 Tflops des belles transalpines apparaissent bien modestes. Point intéressant, si la troisième machine du Green500, Beacon (NICS), est dotée de Xeon Phi 5110P, ce sont des accélérateurs AMD FirePro S10000 qui équipent la quatrième, le fameux SANAM du KACST Saoudien. Leurs performances respectives : 2,44 et 2,35 Gflops / W.
Là encore, les chiffres actuels montrent qu’on est loin du compte. Les GPU et les APU qui combinent CPU + GPU sur un même die vont eux aussi bénéficier de nouveaux processus de fabrication qui augmenteront “mécaniquement” leur rendement, mais il n’ y a pas de grosse rupture de tendance à en attendre. Voilà pourquoi, à côté du projet DEEP d’Intel à Jülich, d’autres designs sont en cours de défrichage. Parmi eux, l’idée d’utiliser exclusivement des GPU pour le calcul et de laisser la gestion ancillaire des clusters à des CPU très basse consommation ne paraît pas infondée.
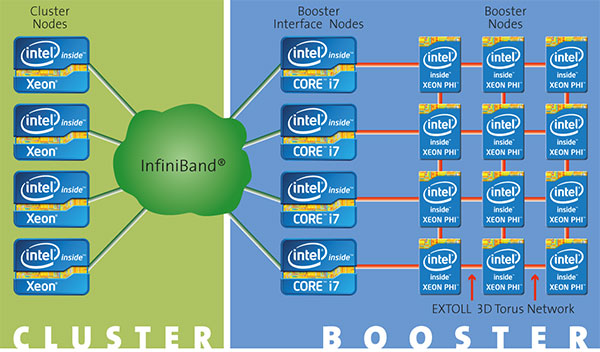
Schéma de principe de l’architecture DEEP, développée par Intel à Jülich.
Nous nous en faisions l’écho le mois dernier, c’est la voie qu’explore le BSC (Barcelona Supercomputing Center) avec le projet Pedraforca. Dans cette machine, des processeurs ARM multicœurs pilotent des GPU compatibles CUDA. Un premier démonstrateur a permis de mettre au point une pile logicielle ad hoc, en montrant (s’il en était besoin) les limites de l’architecture ARM actuelle en calcul intensif. La seconde itération devrait se montrer plus véloce : elle embarque 64 nœuds de 4 processeurs ARM Cortex-A9 et cette fois de “vrais” accélérateurs Kepler K20.
Bull connaît parfaitement l’affaire puisque c’est à lui qu’est revenu de déployer le cluster. Il n’en reste pas moins que Jean-Pierre Panziera considère l’arrivée d’ARM dans le calcul intensif avec un certain scepticisme : “Le projet de BSC a officiellement pour objectif de créer des prototypes de calculateurs. Ils ont réussi à prouver que l’idée fonctionne, qu’on arrive à déployer des clusters ARM, mais le projet ne fait que confirmer les lacunes des processeurs ARM 32 bits. Ces CPU ont été développés pour des appareils mobiles, pas pour le HPC. On verra bien ce que les prochaines versions 64 bits [attendues pour 2014 – ndlr] apporteront concrètement, mais je ne crois pas qu’il faille en attendre de gains énormes en efficacité. Et, de mon point de vue, x86 ou ARM, la différence ne sera pas significative dans une optique de calcul intensif à grande échelle.”
[Cet article fait partie du dossier Efficacité énergétique : Le St Graal du calcul intensif]
“Les GPU seuls ne feront pas la différence…”
L’utilisation des GPU dans le calcul intensif a maintenant dix ans. Sur le papier, les GPU sont intéressants en termes d’efficacité énergétique, mais on n’a pas vraiment résolu le problème du portage des applications sur ce type de nœuds. Il faut savoir que les entreprises mettent environ dix ans à développer un code de simulation, en tablant sur entre dix et vingt ans d’utilisation de ce code à partir de leur choix d’architecture. Certaines entreprises font cet effort de portage, en tirant profit de solutions comme Nastran de MSC Software, mais l’importance de la tâche réduit le nombre réel de déploiements à grande échelle. Objectivement, aujourd’hui, 95 % de la puissance de calcul installée reste en CPU, avec il est vrai quelques nœuds GPU utilisés en test. Dans tous les cas, sur les appels d’offre, Bull se positionne à la fois sur une configuration purement CPU et une configuration hybride CPU/GPU. Personnellement, je considère qu’à horizon 2016-2017, la très grande majorité des nœuds installés, probablement 80 % d’entre eux, sera encore constituée de nœuds génériques x86. Peut-être verra-t-on des nœuds ARM 64 bits prendre une part de marché, tout dépendra de leur efficacité et des environnements de développement qui seront disponibles. Mais je crois plus en l’avenir des CPU multicœurs type Xeon Phi. Disposer à terme de centaines de cœurs dans un slot, c’est sans doute la voie la plus évidente. Ce qui n’enlève rien à la difficulté de porter les applications sur ces nouvelles architectures…
Jean-Pierre Panziera, Directeur technique HPC, Bull.
More around this topic...








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}